80686-Pentium Pro
SMP对称多处理器
Pentium Pro开始支持SMP,即在一个机器上使用多个CPU。多路CPU的实现方式主要有两种,一种称为SMP,即对称多处理器,另一个为NUMA,即Non-Uniform Memory Acess。在SMP系统中,多个CPU平等一致地访问总线、外设、内存等资源,各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,也称为UMA。 SMP的设计较为复杂,多个处理器共享总线等资源在CPU个数较少的时候不是什么问题,但在CPU个数较多时,对总线带宽,总线一致性等都提出的较大的挑战,因为在更多的CPU中,通常采用NUMA架构。在NUMA架构中,每个CPU有各自的内存,一个CPU也可以访问其他CPU上的内存,但是访问速度相对较慢。这个特性会被操作系统感知,操作系统在分配内存和计算任务时,尽量将内存和计算任务分配在临近的CPU和内存上。
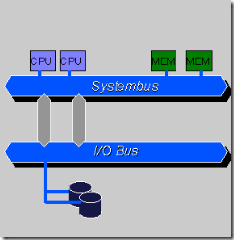 对称多处理器系统架构图
对称多处理器系统架构图
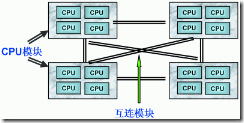 NUMA系统架构图
NUMA系统架构图
Cache的变化
在80486中,Intel将L1 cache放进了CPU,到了80686(其实没有这个叫法了)也就是pentium Pro,Intel将L2 cache也放进了CPU。并且在L1 Cache中将数据和指令分开,即一个8KB的数据Cache, 一个8KB的指令Cache。
将数据和指令分别存取的存取结构叫做哈佛结构,区别于混在一起的冯·诺伊曼结构。
哈佛结构是一种将程序指令存储和数据存储分开的存储器结构。哈佛结构是一种并行体系结构,它的主要特点是将程序和数据存储在不同的存储空间中,即程序存储器和数据存储器是两个独立的存储器,每个存储器独立编址、独立访问。
--百度百科
当然,在CPU外面,DRAM内存还是那么一套内存,硬盘也是那么一套不区分指令和数据的硬盘。因而可以说x86 CPU是在内部采用哈佛结构、外部仍然是冯·诺伊曼结构。 实际上除了少数单片机、DSP等设备,谁也不会最外层的存储设备都区分数据和指令。所以这种内部哈佛,外部冯·诺伊曼结构的做法似乎已经成了业界共识。
DIB结构
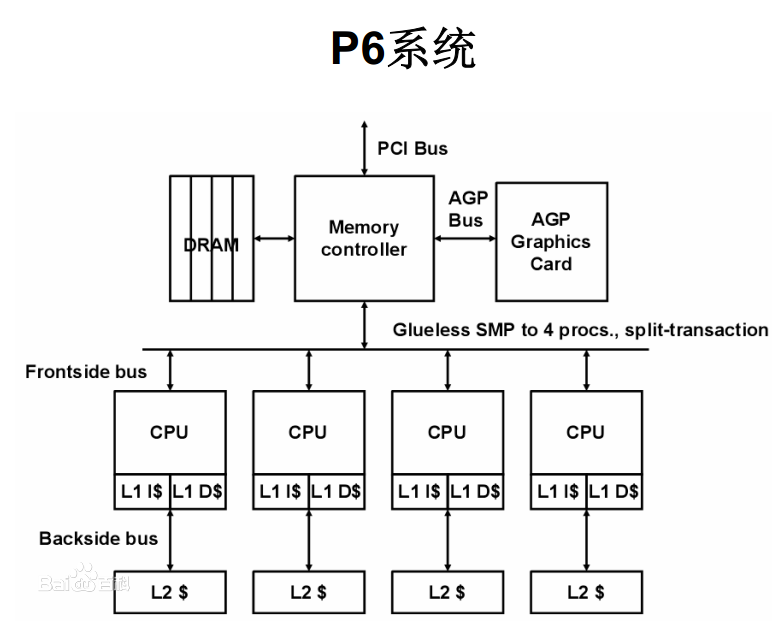
即L2 Cache与DRAM(即我们常说的内存)总线并行,在以前的系统中,包括仅有L1 Cache的系统和有外部L2 Cache的系统。数据的获取都是串行的,即先是L1 Cache中取数据,miss后去L2 Cache中取,如果L2 Cache依然miss,则去DRAM中取数据。
由于L2 Cache相对L2 Cache比较慢,相对于DRAM取数据的时延来讲,L1 Cache miss的时延还可以忽略,L2 Cache miss的时延就不能那么简单的忽略了。
为了降低L2 Cache miss对总的访存时延的影响,在L1 Cache miss时,直接将访存的地址同时发给L2 Cache控制器和DRAM内存控制器。如果L2 Cache hit,则直接采用L2 Cache中的结果,如果L2 Cache miss,则等待DRAM中的访存结果。这样就降低了L2 Cache miss时的访存的整体时间。当然这也有一个问题,就是L2 Cache hit的时候,多做了一次无谓的DRAM访存操作,增加了内存总线的压力。
下面的图片中可以看出,DRAM和L2 Cache的采用并列的方式同时对接总线接口单元BIU。
ILP=3的指令级并行
在上一篇文章 80586-初代奔腾的超标量 中,讲到初代奔腾支持同时取指、解码、执行、回写两条指令,即有两条流水线,两个ALU,可最多同时执行两个互相没有数据依赖的指令,这种做法称为指令级并行(ILP, Instruction Level Paralism),在Pentium Pro中,有三条这样的流水线,可以最多同时执行三条指令。
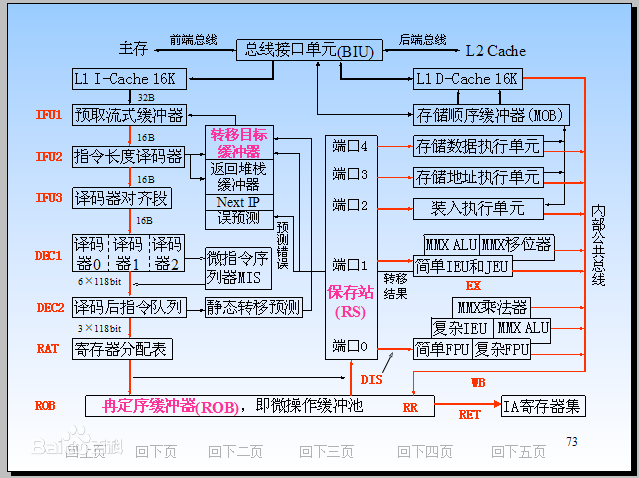
12级流水线
上面图中的红字表示的流水线中的三个单元,从图中可以看出,总共有12个单元。其中:
- 取指有三个单元,分别为IFU1, IFU2和IFU3.
- 译码有两个单元,分别为DEC1, DEC2。 在译码这里涉及到两个技术,即微码技术和分支预测技术。 DEC1有三个译码器,译码结果是微指令序列,即将CISC的指令转换成多条RISC指令,然后传给DEC2。 在DEC2译码后,如果发现有分支指令,则会进行分支预测,控制取指单元去取某个更可能的指令分支上的指令。
- 寄存器分配表
- Reorder Buffer,即对指令进行乱序的单元
- DIS,应该是指令的分发单元
- EX, 即流水线中的执行部分,这里包括通常的ALU、MMX指令执行单元、浮点计算单元等。
- RR
- WB
- RET
大页
处理器分页通常都是支持4KB的页,一个页设得如此之小,造成的一个问题就是页表条目变多,页表size大,TLB miss也增多了。现在它也支持4MB的大页。可以从一定程度上缓解上述问题。
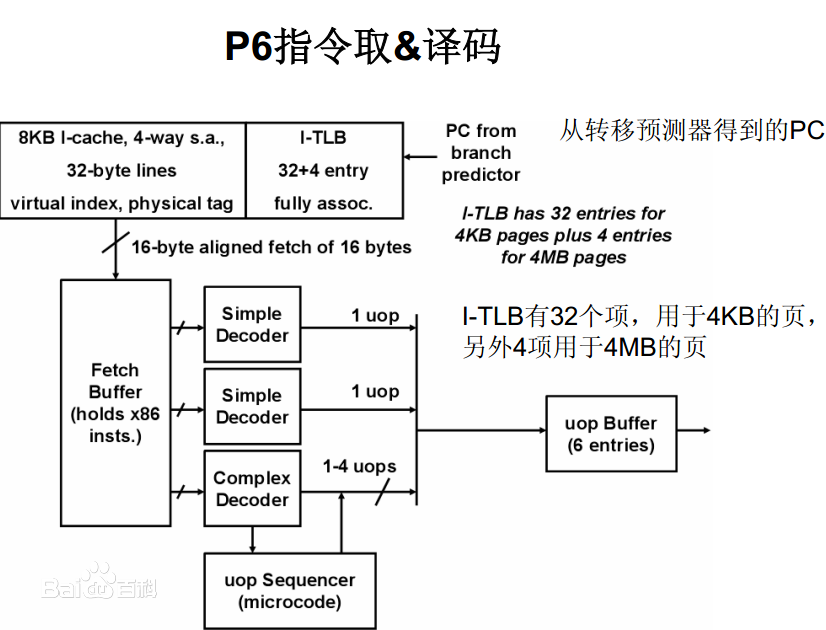
对应地,TLB增加了个项,专门用来缓存大页的页表项。
在现代处理器中,由于内存变得越来越大,服务器的内存可能达到几个TB的内存,大页的支持已经提高了一个1GB的页。