qemu的xxx.img格式磁盘
其实就是一个普通的二进制文件,里面没有任何格式,它就是dd的结果。生成一个这样的磁盘只需要
# 创建空的磁盘镜像文件
dd if=/dev/zero of=$disk_image bs=1M count=100
ext2文件系统格式
制作方法
# 格式化为ext2文件系统
mkfs.ext2 $disk_image
# 创建临时挂载点
tmp_mount=$(mktemp -d)
# 挂载磁盘镜像
sudo mount -o loop $disk_image $tmp_mount
# 检查rootfs/binary目录是否存在
if [ -d "rootfs/binary" ]; then
# 复制文件到磁盘镜像
sudo cp -r rootfs/binary/* $tmp_mount/
else
echo "错误:rootfs/binary目录不存在"
fi
# 卸载磁盘镜像
sudo umount $tmp_mount
查看文件内容
sudo mount -o loop $disk_image /mnt
ls /mnt
sudo umount /mnt
超级块
在 ext2 文件系统中,超级块(Super Block)是存储文件系统全局元数据的核心结构,包含文件系统的布局、容量、状态等关键信息。以下是其格式的详细解析:
一、超级块的结构与核心字段
1. 基本结构
超级块的大小固定为 1024 字节,其数据结构在 Linux 内核中定义为 struct ext2_super_block(位于 这里)。以下是关键字段的说明(顺序不对,顺序看图):
| 字段名 | 类型 | 描述 | | ——————— | —— | ———————————————— | | s_inodes_count | __le32 | 文件系统中 inode 的总数。 | | s_blocks_count | __le32 | 文件系统中数据块的总数。 | | s_r_blocks_count | __le32 | 为超级用户保留的块数(通常为总块数的 5%)。 | | s_free_blocks_count | __le32 | 当前可用的空闲块数。 | | s_free_inodes_count | __le32 | 当前可用的空闲 inode 数。 | | s_first_data_block | __le32 | 第一个数据块的位置(通常为 1,块 0 保留给引导扇区)。 | | s_log_block_size | __le32 | 块大小的对数(以 2 为底),例如:0 表示 1024 字节,1 表示 2048 字节。 | | s_blocks_per_group | __le32 | 每个块组包含的数据块数。 | | s_inodes_per_group | __le32 | 每个块组包含的 inode 数。 | | s_magic | __le16 | 魔数(Magic Number),用于验证文件系统类型,ext2 的魔数为 0xEF53。 | | s_state | __le16 | 文件系统状态(如已挂载、需要检查等)。 | | s_mnt_count | __le16 | 文件系统已挂载的次数。 | | s_max_mnt_count | __le16 | 文件系统允许的最大挂载次数,超过后会提示执行 e2fsck。 | | | | | 下图是linux下的定义,代码在这里:  下图是osdev的截图,说的是一致的,但是注意,super block是sector 2和3:
下图是osdev的截图,说的是一致的,但是注意,super block是sector 2和3: 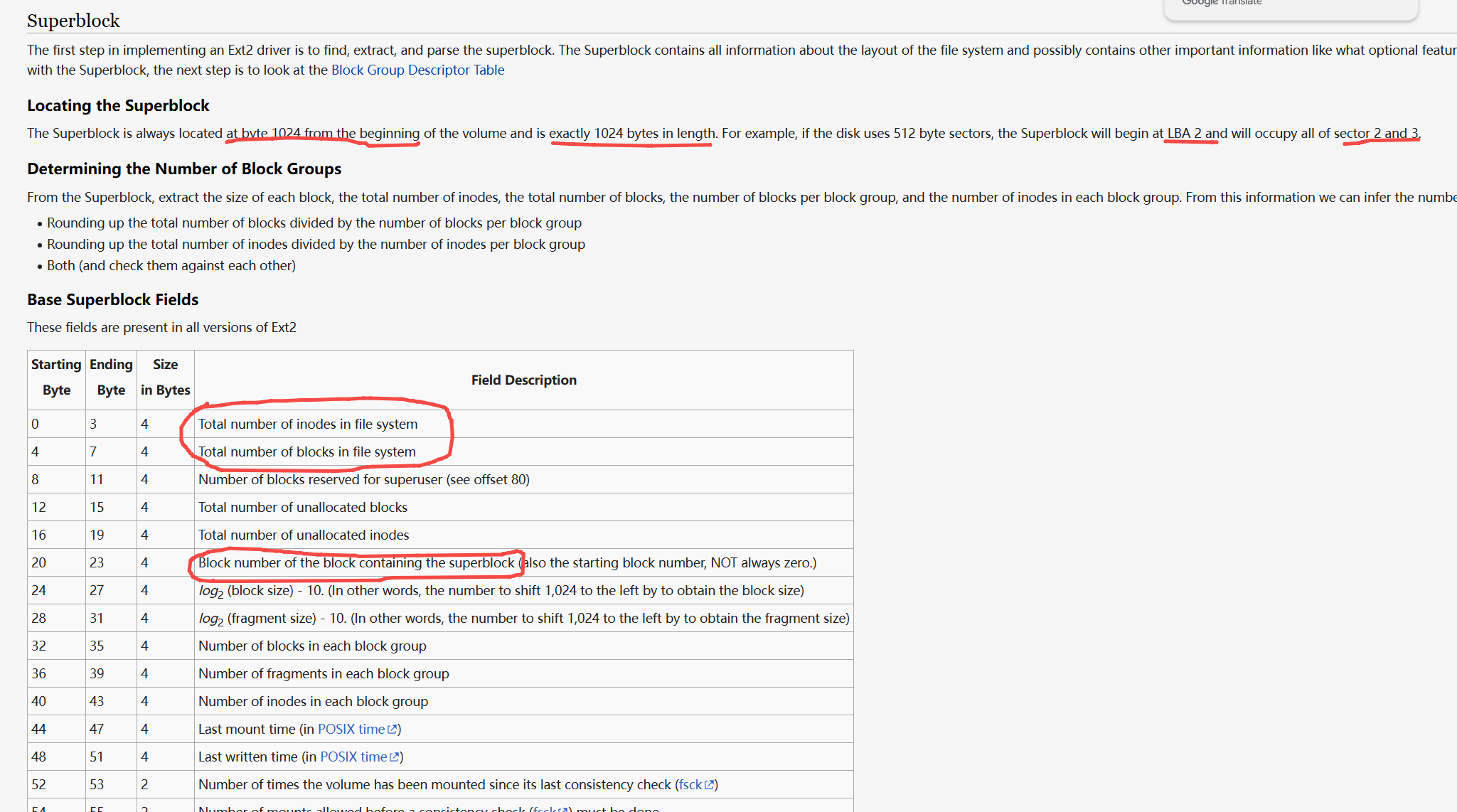
2. 关键字段的计算与应用
- 块大小:
块大小(以字节为单位)通过公式block_size = 1024 << s_log_block_size计算。例如,若s_log_block_size为2,则块大小为4096字节。 - 块组数量:
总块组数量由s_blocks_count / s_blocks_per_group确定。每个块组独立管理 inode 和数据块,提高文件系统的可靠性和性能。 - 魔数验证:
通过s_magic字段判断文件系统类型。若魔数不为0xEF53,可能表示文件系统损坏或非 ext2 格式。
二、超级块的备份机制
为防止主超级块损坏,ext2 会在每个块组的起始位置备份超级块。例如:
- 主超级块:位于块组 0 的1024字节处,与块大小无关。
- 备份超级块:分布在块组 1、2、3 等的起始块(具体位置由
mke2fs工具在格式化时确定)。
恢复方法:
使用 e2fsck -b <备份块号> /dev/sda1 命令指定备份超级块进行文件系统修复。例如,e2fsck -b 8193 /dev/sda1 表示使用块号为 8193 的备份超级块。
三、超级块的实际查看与解析
1. 使用 dumpe2fs 工具
通过 dumpe2fs -h /dev/sda1 命令可查看超级块的详细信息:
# dumpe2fs -h /dev/sda1
Filesystem volume name: <none>
Last mounted on: /mnt
Filesystem UUID: 5b6740c3-...
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: ext_attr resize_inode dir_index filetype sparse_super
Block size: 4096
Blocks per group: 32768
Inodes per group: 8192
Reserved block count: 16384
Free blocks: 1048576
Free inodes: 81920
First data block: 0
2. 二进制数据解析
使用 hexdump 或 dd 工具可直接读取超级块的二进制内容:
# hexdump -n 1024 -s 1024 /dev/sda1 | less
00000400 20 63 00 00 00 8c 01 00 cc 13 00 00 67 79 01 00 | c...........gy..|
00000410 15 63 00 00 01 00 00 00 00 00 00 00 00 00 00 00 |.c..............|
...
00000430 40 f0 e3 66 00 00 ff ff 53 ef 01 00 01 00 00 00 |@..f....S.......|
- 魔数:
0xEF53位于偏移量0x438处(小端序存储为53 ef)。 - 块大小:
s_log_block_size字段为0x02,对应块大小为4096字节。
四、超级块的版本差异与扩展
1. 版本演进
- ext2:基础版本,无日志功能。
- ext3:在 ext2 基础上增加日志功能,魔数仍为
0xEF53,但通过s_feature_incompat字段标记日志特性。 - ext4:兼容 ext2/ext3,支持更大的文件系统和 inode 扩展(如 256 字节 inode)。
2. 扩展字段
- 特性标志:
s_feature_compat、s_feature_ro_compat、s_feature_incompat字段记录文件系统支持的特性(如扩展属性、目录索引等)。 - UUID 与标签:
s_uuid和s_volume_name字段用于唯一标识文件系统和设置卷标。
五、常见问题与维护
- 超级块损坏:
- 现象:文件系统无法挂载,提示
Invalid superblock。 - 解决方案:使用备份超级块恢复(如
e2fsck -b 8193 /dev/sda1)。
- 现象:文件系统无法挂载,提示
- 文件系统一致性检查:
- 命令:
e2fsck -f /dev/sda1。 - 作用:检查并修复超级块、块组描述符、inode 表等元数据错误。
- 命令:
- 调整文件系统参数:
- 使用
tune2fs工具修改超级块参数(如最大挂载次数、保留块比例等):# tune2fs -c 0 /dev/sda1 # 关闭自动检查 # tune2fs -m 10 /dev/sda1 # 将保留块比例调整为 10%
- 使用
六、总结
超级块是 ext2 文件系统的"心脏",存储了文件系统的全局信息。通过 dumpe2fs、e2fsck 等工具,管理员可查看、维护和修复超级块,确保文件系统的稳定性。理解超级块的结构和备份机制,有助于深入排查文件系统故障并优化性能。
block group
在 ext2 文件系统中,块组描述符(Block Group Descriptor)用于描述每个块组的信息,其位置与超级块和块大小等因素相关。
1. 块大小的确定
根据超级块中的 log_block_size 字段,块大小的计算公式为 块大小 = 1024 << log_block_size。已知 log_block_size = 2,则块大小为 1024 << 2 = 4096 字节。
2. 超级块的位置
超级块位于块 0,这是固定的。超级块存储了文件系统的全局信息,包括块组描述符表的相关信息。
3. 块组描述符表的位置
在块大小为 4096 字节的情况下,块组描述符表通常紧跟在超级块之后,也就是位于块 1。因为超级块占据了块 0,而块组描述符表需要紧挨着超级块,以便文件系统能够快速定位和读取。
4. 验证与解释
- 验证:你可以使用
debugfs工具来验证块组描述符表的位置。在debugfs中,可以使用block_dump命令查看特定块的内容。例如,使用block_dump 1可以查看块 1 的内容,这里应该就是块组描述符表。 - 解释:块组描述符表包含了每个块组的详细信息,如块位图的位置、inode 位图的位置、inode 表的起始块等。文件系统通过读取块组描述符表,能够快速定位到每个块组的关键信息,从而进行文件和目录的管理。
综上所述,在你提供的超级块信息所对应的 ext2 文件系统中,块组描述符表位于块 1。
5. Group descriptor的结构
/*
* Structure of a blocks group descriptor
*/
struct Ext2GroupDesc {
uint32_t bg_block_bitmap; /* Blocks bitmap block */
uint32_t bg_inode_bitmap; /* Inodes bitmap block */
uint32_t bg_inode_table; /* Inodes table block */
uint16_t bg_free_blocks_count; /* Free blocks count */
uint16_t bg_free_inodes_count; /* Free inodes count */
uint16_t bg_used_dirs_count; /* Directories count */
uint16_t bg_pad;
uint32_t bg_reserved[3];
};
inode
在 ext2 文件系统中,inode(索引节点)是存储文件或目录元数据的核心结构,每个文件或目录在创建时都会被分配一个唯一的 inode。它不仅包含文件的属性信息,还通过指针体系管理文件的数据存储,是文件系统实现高效访问和数据组织的关键。以下是其深度解析:
一、inode 的核心结构与字段
1. 基础布局
inode 的大小通常为 128 字节(ext2)或 256 字节(ext4),其结构在 Linux 内核中定义为 struct ext2_inode(位于这里)。以下是核心字段的说明(但顺序不对,不要做为顺序参考):
| 字段名 | 类型 | 描述 |
|---|---|---|
i_mode | __le16 | 文件类型(如普通文件、目录、符号链接)和权限位(rwxrwxrwx)。 |
i_uid | __le16 | 文件所有者的用户 ID。 |
i_gid | __le16 | 文件所属组的组 ID。 |
i_size | __le32 | 文件的字节大小。 |
i_atime | __le32 | 最后访问时间戳(精确到秒)。 |
i_mtime | __le32 | 最后修改时间戳(精确到秒)。 |
i_ctime | __le32 | inode 元数据最后变更时间戳(精确到秒)。 |
i_links_count | __le16 | 硬链接数量(文件被引用的次数)。 |
i_blocks | __le32 | 文件占用的块数(以 512 字节为单位)。 |
i_block[EXT2_N_BLOCKS] | __le32 | 数据块指针数组,支持直接、间接和双重间接块。 |
具体结构在这里,截图如下:

osdev上的说明:
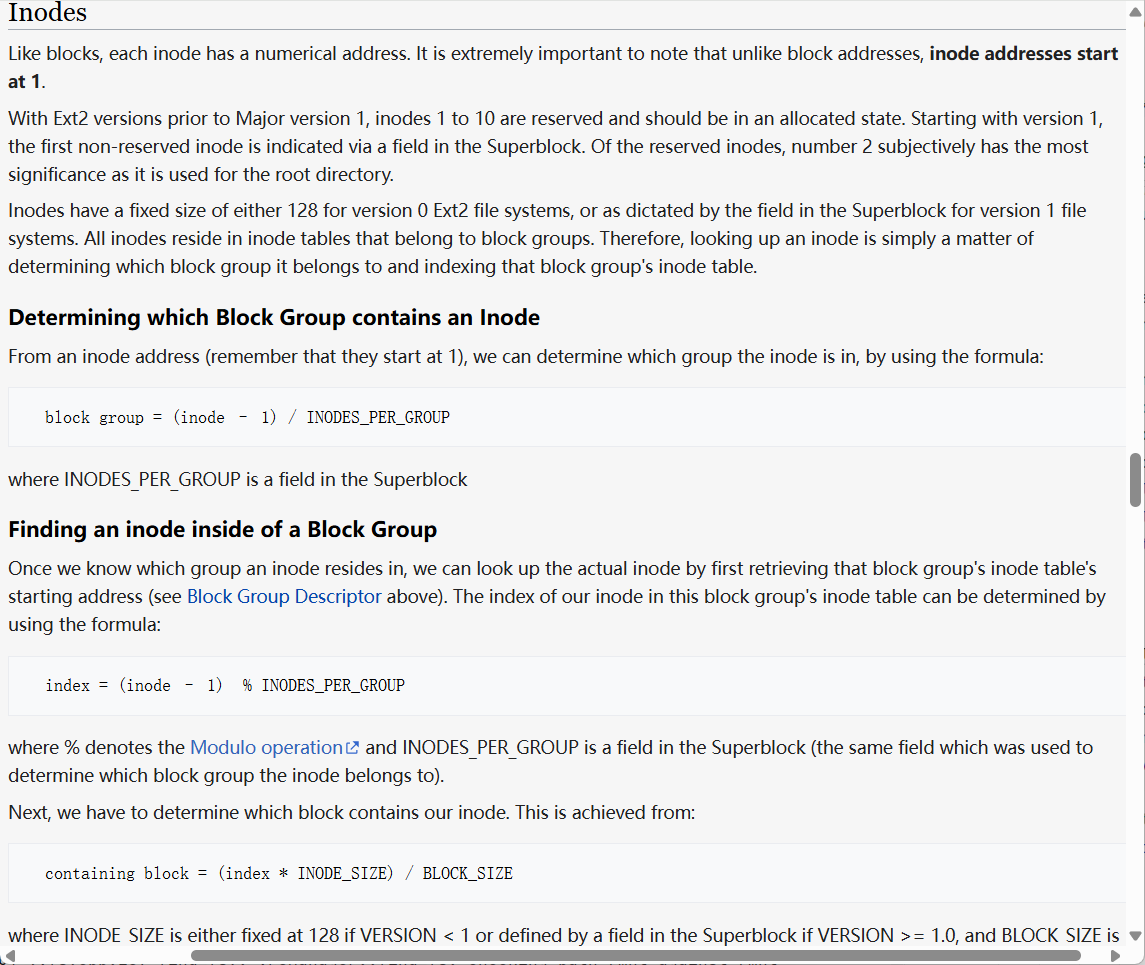
inode size我的是256,版本是1。first inode是11, 所以前10个也是保留的。
2. 数据块指针体系
- 直接块(Direct Blocks):
前 12 个指针(i_block[0..11])直接指向数据块,适合快速访问小文件(如 12 个块 × 4KB 块大小 = 48KB)。 - 间接块(Indirect Blocks):
i_block[12]指向一个块,该块存储 256 个数据块指针(单间接块),支持更大的文件(如 256 × 4KB = 1MB)。 - 双重间接块(Double Indirect Blocks):
i_block[13]指向一个块,该块存储 256 个单间接块指针,每个单间接块又指向 256 个数据块(总容量为 256 × 256 × 4KB = 256MB)。 - 三重间接块(Triple Indirect Blocks):
i_block[14]指向一个块,该块存储 256 个双重间接块指针,理论上支持的文件大小可达 2^32 块(受限于文件系统总块数)。
示例计算:
若块大小为 4KB,一个文件使用 12 个直接块 + 1 个单间接块 + 1 个双重间接块,其总大小为:
12×4KB + 256×4KB + 256×256×4KB = 48KB + 1MB + 256MB = 257.048MB。
二、inode 的功能与工作原理
1. 文件类型与权限控制
- 文件类型:
通过i_mode的高 4 位(S_IFMT掩码)判断文件类型,如:S_IFREG(0x8000):普通文件。S_IFDIR(0x4000):目录。S_IFLNK(0xA000):符号链接。
- 权限位:
i_mode的低 12 位(S_IRWXU/S_IRWXG/S_IRWXO)分别控制所有者、所属组、其他用户的读(r)、写(w)、执行(x)权限。
2. 数据存储与访问
- 小文件优化:
对于小于等于 12 个块的文件,数据直接存储在直接块中,无需额外寻址开销。 - 大文件支持:
通过多级间接块指针,ext2 理论上支持单个文件最大为 16TB(块大小 4KB 时)。 - 符号链接优化:
若符号链接的目标路径长度 ≤ 60 字节,路径直接存储在 inode 的i_block中,无需额外数据块。
3. 时间戳与元数据管理
- 访问时间(atime):
每次读取文件时更新,可通过mount选项noatime禁用以提升性能。 - 修改时间(mtime):
文件内容变更时更新。 - 变更时间(ctime):
inode 元数据(如权限、所有者)变更时更新。
三、inode 的存储与管理
1. 物理布局
- inode 表:
每个块组包含一个 inode 表,存储该组内所有 inode 的二进制数据。例如,一个块组包含 8192 个 inode,每个 inode 占 128 字节,则 inode 表大小为8192 × 128B = 1MB。 - inode 位图:
每个块组有一个 inode 位图,用每一位表示对应的 inode 是否被占用(0 表示空闲,1 表示已分配)。
2. 分配与回收
- 分配流程:
- 扫描 inode 位图,找到第一个空闲位。
- 标记该位为已使用,初始化 inode 元数据(如权限、所有者)。
- 若为目录,创建
.(当前目录)和..(父目录)的目录项。
- 回收流程:
- 减少
i_links_count,若为 0,则标记 inode 位图对应位为空闲。 - 释放所有关联的数据块(通过指针遍历直接、间接块)。
- 更新超级块中的空闲 inode 计数。
- 减少
3. 数量限制
- inode 总数:
格式化时由mke2fs根据分区大小和块组参数自动计算,公式为:
inode_count = (total_blocks / blocks_per_group) × inodes_per_group。 - inode 耗尽问题:
若文件系统包含大量小文件(如日志文件),可能耗尽 inode 而不是磁盘空间。可通过df -i查看 inode 使用情况。
四、inode 的查看与维护
1. 命令行工具
ls -i:
显示文件或目录的 inode 编号:$ ls -i /etc/passwd 262145 /etc/passwdstat:
查看 inode 元数据:$ stat /etc/passwd File: /etc/passwd Size: 2050 Blocks: 8 IO Block: 4096 regular file Device: 801h/2049d Inode: 262145 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2025-04-03 10:41:23.000000000 +0800 Modify: 2025-03-25 15:32:47.000000000 +0800 Change: 2025-03-25 15:32:47.000000000 +0800 Birth: -debugfs:
直接访问 inode 结构(需 root 权限):$ sudo debugfs -R 'stat <inode_number>' /dev/sda1 Inode: 262145 Type: regular Mode: 0644 Flags: 0x80000 Generation: 0 Version: 0x00000000 User: 0 Group: 0 Size: 2050 ...
2. 修复工具
e2fsck:
检查并修复 inode 错误(需卸载文件系统):$ sudo umount /dev/sda1 $ sudo e2fsck -f /dev/sda1debugfs:
手动修复损坏的 inode(危险操作,需谨慎):$ sudo debugfs /dev/sda1 debugfs: clri <inode_number> # 清除 inode 内容 debugfs: write <file> <inode_number> # 从文件恢复 inode
五、inode 的高级特性与优化
1. 硬链接与软链接
- 硬链接:
多个文件名指向同一个 inode,i_links_count增加。删除其中一个文件名不会影响数据,直到i_links_count为 0。 - 软链接:
独立 inode,存储目标路径,不增加i_links_count。目标文件删除后,软链接失效。
2. 扩展属性(XATTR)
- 功能:
在 inode 中存储额外元数据(如文件分类、加密标记),通过setfattr/getfattr操作。 - 实现:
ext2 通过i_block存储扩展属性数据块,需在格式化时启用(mke2fs -O extent)。
3. 性能优化
- 预分配 inode:
mke2fs -N <number>可手动指定 inode 数量,避免自动计算导致的浪费。 - 碎片整理:
e4defrag工具可优化 inode 和数据块的物理布局,提升访问速度。
六、常见问题与解决方案
| 问题 | 现象 | 解决方案 | |————————|—————————————|—————————————| | inode 耗尽 | df -i 显示 100%,无法创建新文件 | 清理小文件或扩容分区 | | inode 元数据损坏 | 文件无法访问,stat 报错 | e2fsck -f 修复或从备份恢复 | | 间接块指针错误 | 文件读取失败,debugfs 提示无效块号 | 手动修复指针或使用 e2fsck 自动修复 | | 硬链接计数异常 | ls -l 显示 ?? 链接数 | e2fsck -l 重建链接计数 |
七、总结
inode 是 ext2 文件系统的"灵魂",其设计兼顾了小文件的快速访问和大文件的高效存储。通过理解 inode 的结构、指针体系和管理工具,管理员可深入排查文件系统问题,优化性能,并在数据恢复中发挥关键作用。在实际操作中,建议结合 ls、stat、debugfs 和 e2fsck 等工具,全面掌握 inode 的状态与行为。
根目录的inode在哪里
在 ext2 文件系统中,根目录的 inode 具有固定编号,并且可以通过特定的方式找到其在磁盘上的存储位置,以下为你详细介绍:
1. 根目录 inode 的编号
在 ext2 文件系统里,根目录的 inode 编号固定为 2。这是文件系统的约定,无论文件系统如何布局,根目录的 inode 编号都是 2。在代码中,若要获取根目录的 inode 相关信息,可直接使用这个编号。例如,在使用 debugfs 工具时,就可以通过该编号查看根目录 inode 的详细信息:
sudo debugfs -R 'stat <2>' /dev/sda1
上述命令会显示根目录 inode 的元数据,像权限、大小、时间戳等。
2. 根目录 inode 的物理存储位置
确定块组
根目录的 inode 存储在文件系统的第一个块组(块组编号为 0)的 inode 表中。每个块组都有自己的 inode 表,用于存储该块组内所有文件和目录的 inode。
计算偏移量
要找到根目录 inode 在磁盘上的具体位置,需要计算其在 inode 表中的偏移量。步骤如下:
- 计算每个块组的 inode 数量:可通过超级块中的
s_inodes_per_group字段获取该值。 - 计算 inode 表的起始块:在第一个块组中,inode 表紧跟在超级块和块组描述符表之后。
- 计算根目录 inode 的偏移量:由于根目录 inode 编号为
2,而 inode 编号从1开始,所以它是 inode 表中的第二个 inode。假设每个 inode 大小为128字节,那么根目录 inode 的偏移量为(2 - 1) * 128字节。
示例代码(伪代码)
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#define INODE_SIZE 128
#define ROOT_INODE_NUMBER 2
// 假设已经从超级块中读取了 s_inodes_per_group 和 inode_table_start_block
int s_inodes_per_group = 8192;
int inode_table_start_block = 2; // 假设 inode 表从第 2 个块开始
int main() {
int fd = open("/dev/sda1", O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
// 计算根目录 inode 的偏移量
off_t offset = (inode_table_start_block * 1024) + ((ROOT_INODE_NUMBER - 1) * INODE_SIZE);
// 定位到根目录 inode 的位置
if (lseek(fd, offset, SEEK_SET) == -1) {
perror("lseek");
close(fd);
return 1;
}
// 读取根目录 inode 的内容
char inode_buffer[INODE_SIZE];
if (read(fd, inode_buffer, INODE_SIZE) != INODE_SIZE) {
perror("read");
close(fd);
return 1;
}
// 处理根目录 inode 的内容
// ...
close(fd);
return 0;
}
3. 使用工具查看
debugfs 工具
debugfs 是一个强大的 ext2/ext3/ext4 文件系统调试工具,可用于查看和修改文件系统的底层结构。通过以下命令可以查看根目录的 inode 信息:
sudo debugfs /dev/sda1
debugfs: stat <2>
该命令会输出根目录 inode 的详细元数据,包括文件类型、权限、大小、时间戳等。
e2fsck 工具
e2fsck 主要用于检查和修复 ext2/ext3/ext4 文件系统的错误,但也可以提供一些文件系统的元数据信息。虽然它不是专门用于查看 inode 信息的工具,但在检查文件系统时会涉及到 inode 的处理。
总之,根目录的 inode 编号固定为 2,其物理存储位置在第一个块组的 inode 表中。通过文件系统的超级块和块组描述符表,可以计算出其在磁盘上的具体偏移量。借助 debugfs 等工具,能方便地查看根目录 inode 的详细信息。
注意
struct ext2_inode的大小可能是128,但superblock->inode_size是256,这时计算偏移当然以superblock为准了。
第一个inode怎么找
在 ext2 文件系统中,超级块(superblock)的 s_first_data_block 字段表示第一个数据块的编号。该值是否为 0 取决于文件系统的 块大小(block size) 和 布局策略,具体分析如下:
一、常规布局与块大小的影响
1. 块大小为 1KB 或 2KB 的情况
- 默认值为 1:在块大小为 1KB 或 2KB 的 ext2 文件系统中,超级块位于 块 0,块组描述符表位于 块 1,数据块从 块 2 开始。此时,
s_first_data_block的值通常为 1,因为第一个数据块是块组描述符表之后的第一个可用块。 - 示例:若块大小为 1KB,文件系统的布局如下:
块 0: 超级块 块 1: 块组描述符表 块 2: 块位图 块 3: inode 位图 块 4: inode 表 块 5 及之后: 数据块此时,
s_first_data_block = 1表示数据块从块 2 开始(块组描述符表之后)。
2. 块大小为 4KB 的情况
- 允许值为 0:当块大小为 4KB 时,超级块仍位于 块 0,但块组描述符表可能直接紧跟在超级块之后,占据 块 1。此时,数据块从 块 2 开始,因此
s_first_data_block的值可以是 0。 - 示例:块大小为 4KB 时,布局如下:
块 0: 超级块 块 1: 块组描述符表 块 2: 块位图 块 3: inode 位图 块 4: inode 表 块 5 及之后: 数据块此时,
s_first_data_block = 0表示数据块从块 2 开始(块组描述符表之后)。
二、s_first_data_block 的作用
1. 计算块组描述符表的位置
s_first_data_block的值用于确定块组描述符表的起始块。例如,块组描述符表的起始块为s_first_data_block + 1。- 示例:
- 若
s_first_data_block = 0,块组描述符表位于 块 1。 - 若
s_first_data_block = 1,块组描述符表位于 块 2。
- 若
2. 数据块的起始位置
- 数据块的起始位置为块组描述符表之后的第一个可用块。例如:
- 当
s_first_data_block = 0时,数据块从 块 2 开始。 - 当
s_first_data_block = 1时,数据块从 块 3 开始。
- 当
三、s_first_data_block 为 0 的合法性
1. 合法情况
- 块大小为 4KB:在块大小为 4KB 的 ext2 文件系统中,
s_first_data_block = 0是合法的。此时,块组描述符表位于块 1,数据块从块 2 开始。 - 稀疏超级块(sparse superblock):在 ext2 的后续版本中,超级块的备份可能仅存于特定块组中。此时,
s_first_data_block的值可能根据布局调整为 0。
2. 异常情况
- 文件系统损坏:若
s_first_data_block被错误设置为 0(例如,块大小为 1KB 时),可能导致文件系统无法正确识别数据块的位置,进而无法挂载或访问数据。 - 工具报错:例如,
e2fsck工具可能提示"bad magic number in superblock",此时需要使用备份超级块进行修复。
四、验证与修复
1. 查看超级块信息
使用 dumpe2fs 工具查看超级块中的 s_first_data_block 值:
sudo dumpe2fs /dev/sda1 | grep "First Data Block"
- 正常输出示例(块大小为 4KB):
First Data Block: 0 - 异常输出示例(块大小为 1KB 但
s_first_data_block = 0):First Data Block: 0 # 可能导致文件系统无法正常工作
2. 修复文件系统
若 s_first_data_block 的值异常,可能需要使用备份超级块恢复:
sudo e2fsck -b <备份超级块号> /dev/sda1
- 备份超级块号:可通过
dumpe2fs查看,例如:sudo dumpe2fs /dev/sda1 | grep "Backup superblock"
五、总结
- 正常情况:当块大小为 4KB 时,
s_first_data_block = 0是合法的,数据块从块 2 开始。 - 异常情况:当块大小为 1KB 或 2KB 时,
s_first_data_block = 0通常表示文件系统布局异常或损坏,需要修复。 - 关键判断依据:结合块大小和文件系统布局,通过工具(如
dumpe2fs)验证s_first_data_block的值是否与实际块组结构一致。
建议在遇到 s_first_data_block = 0 的情况时,首先确认块大小和文件系统布局,若文件系统无法正常工作,应使用备份超级块或文件系统修复工具进行处理。