- Vulkan® Guide
- 1. Logistics Overview
- 2. What is Vulkan?
- 3. What Vulkan Can Do
- 4. Vulkan Specification
- 5. Platforms
- 6. Checking For Vulkan Support
- 7. Versions
- 8. Vulkan Release Summary
- 9. What is SPIR-V
- 10. Portability Initiative
- 11. Vulkan CTS
- 12. Development Tools
- 13. Vulkan Validation Overview
- 14. Vulkan Decoder Ring
- 15. Using Vulkan
- 16. Loader
- 17. Layers
- 18. Querying Properties, Extensions, Features, Limits, and Formats
- 19. Enabling Extensions
- 20. Enabling Features
- 21. Using SPIR-V Extensions
- 22. Formats
- 23. Queues
- 24. Window System Integration (WSI)
- 25. pNext and sType
- 26. Synchronization
- 27. VK_KHR_synchronization2
- 27.1. Rethinking Pipeline Stages and Access Flags
- 27.2. Reusing the same pipeline stage and access flag names
- 27.3. VkSubpassDependency
- 27.4. Splitting up pipeline stages and access masks
- 27.5. VK_ACCESS_SHADER_WRITE_BIT alias
- 27.6. TOP_OF_PIPE and BOTTOM_OF_PIPE deprecation
- 27.7. Making use of new image layouts
- 27.8. New submission flow
- 27.9. Emulation Layer
- 28. Memory Allocation
- 29. Sparse Resources
- 30. Protected Memory
- 31. Pipeline Cache
- 32. Threading
- 33. Depth
- 34. Mapping Data to Shaders
- 35. Vertex Input Data Processing
- 36. Descriptor Dynamic Offset
- 37. Robustness
- 38. Pipeline Dynamic State
- 39. Subgroups
- 40. Shader Memory Layout
- 41. Atomics
- 42. Common Pitfalls for New Vulkan Developers
- 43. HLSL in Vulkan
- 44. When and Why to use Extensions
- 45. Cleanup Extensions
- 45.1. VK_KHR_driver_properties
- 45.2. VK_EXT_host_query_reset
- 45.3. VK_KHR_separate_depth_stencil_layouts
- 45.4. VK_KHR_depth_stencil_resolve
- 45.5. VK_EXT_separate_stencil_usage
- 45.6. VK_KHR_dedicated_allocation
- 45.7. VK_EXT_sampler_filter_minmax
- 45.8. VK_KHR_sampler_mirror_clamp_to_edge
- 45.9. VK_EXT_4444_formats and VK_EXT_ycbcr_2plane_444_formats
- 45.10. VK_KHR_format_feature_flags2
- 45.11. VK_EXT_rgba10x6_formats
- 45.12. Maintenance Extensions
- 45.13. pNext Expansions
- 46. Device Groups
- 47. External Memory and Synchronization
- 48. Ray Tracing
- 49. Shader Features
- 49.1. VK_KHR_spirv_1_4
- 49.2. VK_KHR_8bit_storage and VK_KHR_16bit_storage
- 49.3. VK_KHR_shader_float16_int8
- 49.4. VK_KHR_shader_float_controls
- 49.5. VK_KHR_storage_buffer_storage_class
- 49.6. VK_KHR_variable_pointers
- 49.7. VK_KHR_vulkan_memory_model
- 49.8. VK_EXT_shader_viewport_index_layer
- 49.9. VK_KHR_shader_draw_parameters
- 49.10. VK_EXT_shader_stencil_export
- 49.11. VK_EXT_shader_demote_to_helper_invocation
- 49.12. VK_KHR_shader_clock
- 49.13. VK_KHR_shader_non_semantic_info
- 49.14. VK_KHR_shader_terminate_invocation
- 49.15. VK_KHR_workgroup_memory_explicit_layout
- 49.16. VK_KHR_zero_initialize_workgroup_memory
- 50. Translation Layer Extensions
- 51. VK_EXT_descriptor_indexing
- 52. VK_EXT_inline_uniform_block
- 53. VK_EXT_memory_priority
- 54. VK_KHR_descriptor_update_template
- 55. VK_KHR_draw_indirect_count
- 56. VK_KHR_image_format_list
- 57. VK_KHR_imageless_framebuffer
- 58. VK_KHR_sampler_ycbcr_conversion
- 59. VK_KHR_shader_subgroup_uniform_control_flow
- 60. Contributing
- 61. License
- 62. Code of conduct
permalink: /Notes/004-3d-rendering/vulkan/guide.html layout: post
Vulkan® Guide
The Khronos® Vulkan Working Group :data-uri: :icons: font :toc2: :toclevels: 2 :max-width: 100% :numbered: :source-highlighter: rouge :rouge-style: github
The Vulkan Guide is designed to help developers get up and going with the world of Vulkan. It is aimed to be a light read that leads to many other useful links depending on what a developer is looking for. All information is intended to help better fill the gaps about the many nuances of Vulkan.
1. Logistics Overview
permalink: /Notes/004-3d-rendering/vulkan/chapters/what_is_vulkan.html layout: default ---
2. What is Vulkan?
| Note | Vulkan is a new generation graphics and compute API that provides high-efficiency, cross-platform access to modern GPUs used in a wide variety of devices from PCs and consoles to mobile phones and embedded platforms. |
Vulkan is not a company, nor language, but rather a way for developers to program their modern GPU hardware in a cross-platform and cross-vendor fashion. The Khronos Group is a member-driven consortium that created and maintains Vulkan.
2.1. Vulkan at its core
At the core, Vulkan is an API Specification that conformant hardware implementations follow. The public specification is generated from the ./xml/vk.xml Vulkan Registry file in the official public copy of the Vulkan Specification repo found at Vulkan-Doc. Documentation of the XML schema is also available.
The Khronos Group, along with the Vulkan Specification, releases C99 header files generated from the API Registry that developers can use to interface with the Vulkan API.
2.2. Vulkan and OpenGL
Some developers might be aware of the other Khronos Group standard OpenGL which is also a 3D Graphics API. Vulkan is not a direct replacement for OpenGL, but rather an explicit API that allows for more explicit control of the GPU.
Khronos' Vulkan Samples article on "How does Vulkan compare to OpenGL ES? What should you expect when targeting Vulkan? offers a more detailed comparison between the two APIs.
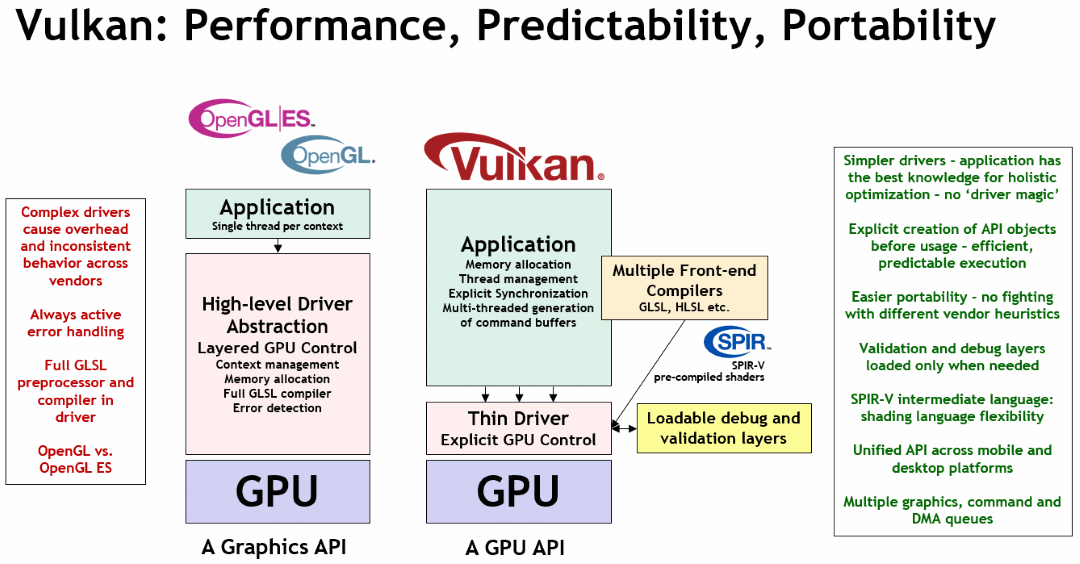
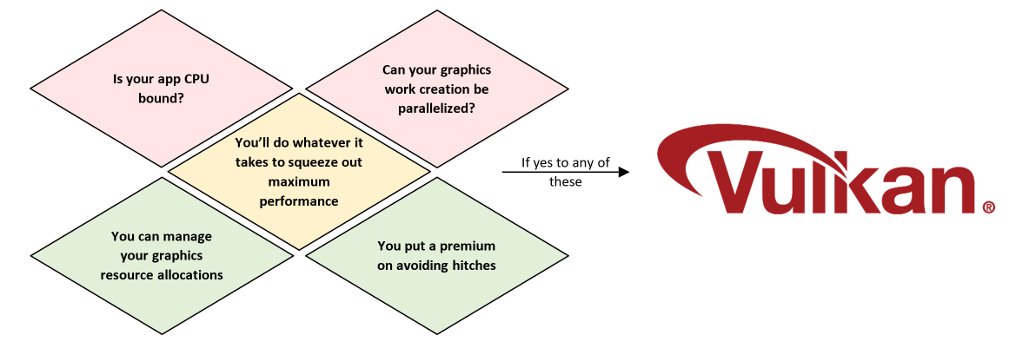
Vulkan puts more work and responsibility into the application. Not every developer will want to make that extra investment, but those that do so correctly can find power and performance improvements.
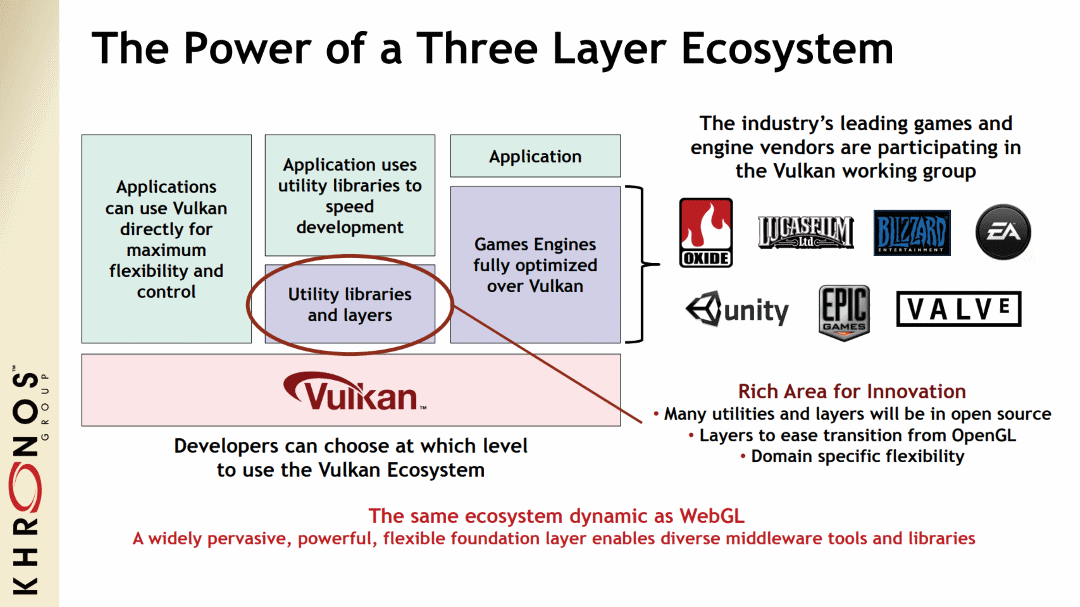
2.3. Using helping libraries
While some developers may want to try using Vulkan with no help, it is common to use some lighter libraries in your development flow to help abstract some of the more tedious aspect of Vulkan. Here are some libraries to help with development
2.4. Learning to use Vulkan
Vulkan is a tool for developers to create hardware accelerated applications. The Vulkan Guide tries to cover the more logistical material such as extensions, versions, spec, etc. For more information how to “use” Vulkan to create something such as the Hello World Triangle, please take a look at resources such as those found in Khronos' Vulkan “learn” page. If you want to get more hands-on help and knowledge, feel free to join the Khronos Developer Slack or the Khronos Community Forums as well!
permalink: /Notes/004-3d-rendering/vulkan/chapters/what_vulkan_can_do.html ---
3. What Vulkan Can Do
Vulkan can be used to develop applications for many use cases. While Vulkan applications can choose to use a subset of the functionality described below, it was designed so a developer could use all of them in a single API.
| Note | It is important to understand Vulkan is a box of tools and there are multiple ways of doing a task. |
3.1. Graphics
2D and 3D graphics are primarily what the Vulkan API is designed for. Vulkan is designed to allow developers to create hardware accelerated graphical applications.
| Note | All Vulkan implementations are required to support Graphics, but the WSI system is not required. |
3.2. Compute
Due to the parallel nature of GPUs, a new style of programming referred to as GPGPU can be used to exploit a GPU for computational tasks. Vulkan supports compute variations of VkQueues, VkPipelines, and more which allow Vulkan to be used for general computation.
| Note | All Vulkan implementations are required to support Compute. |
3.3. Ray Tracing
Ray tracing is an alternative rendering technique, based around the concept of simulating the physical behavior of light.
Cross-vendor API support for ray tracing was added to Vulkan as a set of extensions in the 1.2.162 specification. These are primarily VK_KHR_ray_tracing_pipeline, VK_KHR_ray_query, and VK_KHR_acceleration_structure.
| Note | There is also an older NVIDIA vendor extension exposing an implementation of ray tracing on Vulkan. This extension preceded the cross-vendor extensions. For new development, applications are recommended to prefer the more recent KHR extensions. |
3.4. Video
Vulkan Video has release a provisional specification as of the 1.2.175 spec release.
Vulkan Video adheres to the Vulkan philosophy of providing flexible, fine-grained control over video processing scheduling, synchronization, and memory utilization to the application.
| Note | feedback for the provisional specification is welcomed |
3.5. Machine Learning
Currently, the Vulkan Working Group is looking into how to make Vulkan a first class API for exposing ML compute capabilities of modern GPUs. More information was announced at Siggraph 2019.
| Note | As of now, there exists no public Vulkan API for machine learning. |
3.6. Safety Critical
Vulkan SC ("Safety Critical") aims to bring the graphics and compute capabilities of modern GPUs to safety-critical systems in the automotive, avionics, industrial and medical space. It was publicly launched on March 1st 2022 and the specification is available here.
| Note | Vulkan SC is based on Vulkan 1.2, but removed functionality that is not needed for safety-critical markets, increases the robustness of the specification by eliminating ignored parameters and undefined behaviors, and enables enhanced detection, reporting, and correction of run-time faults. |
permalink:/Notes/004-3d-rendering/vulkan/chapters/vulkan_spec.html layout: default ---
4. Vulkan Specification
The Vulkan Specification (usually referred to as the Vulkan Spec) is the official description of how the Vulkan API works and is ultimately used to decide what is and is not valid Vulkan usage. At first glance, the Vulkan Spec seems like an incredibly huge and dry chunk of text, but it is usually the most useful item to have open when developing.
| Note | Reference the Vulkan Spec early and often. |
4.1. Vulkan Spec Variations
The Vulkan Spec can be built for any version and with any permutation of extensions. The Khronos Group hosts the Vulkan Spec Registry which contains a few publicly available variations that most developers will find sufficient. Anyone can build their own variation of the Vulkan Spec from Vulkan-Docs.
When building the Vulkan Spec, you pass in what version of Vulkan to build for as well as what extensions to include. A Vulkan Spec without any extensions is also referred to as the core version as it is the minimal amount of Vulkan an implementation needs to support in order to be conformant.
4.2. Vulkan Spec Format
The Vulkan Spec can be built into different formats.
4.2.1. HTML Chunked
Due to the size of the Vulkan Spec, a chunked version is the default when you visit the default index.html page.
Prebuilt HTML Chunked Vulkan Spec
-
The Vulkan SDK comes packaged with the chunked version of the spec. Each Vulkan SDK version includes the corresponding spec version. See the Chunked Specification for the latest Vulkan SDK.
-
Vulkan 1.0 Specification
-
Vulkan 1.1 Specification
-
Vulkan 1.2 Specification
-
Vulkan 1.3 Specification
4.2.2. HTML Full
If you want to view the Vulkan Spec in its entirety as HTML, you just need to view the vkspec.html file.
Prebuilt HTML Full Vulkan Spec
-
The Vulkan SDK comes packaged with Vulkan Spec in its entirety as HTML for the version corresponding to the Vulkan SDK version. See the HTML version of the Specification for the latest Vulkan SDK. (Note: Slow to load. The advantage of the full HTML version is its searching capability).
-
Vulkan 1.0 Specification
-
Vulkan 1.1 Specification
-
Vulkan 1.2 Specification
-
Vulkan 1.3 Specification
4.2.3. PDF
To view the PDF format, visit the pdf/vkspec.pdf file.
Prebuilt PDF Vulkan Spec
-
Vulkan 1.0 Specification
-
Vulkan 1.1 Specification
-
Vulkan 1.2 Specification
-
Vulkan 1.3 Specification
4.2.4. Man pages
The Khronos Group currently only host the Vulkan Man Pages for the latest version of the 1.3 spec, with all extensions, on the online registry.
The Vulkan Man Pages can also be found in the VulkanSDK for each SDK version. See the Man Pages for the latest Vulkan SDK.
permalink:/Notes/004-3d-rendering/vulkan/chapters/platforms.html layout: default ---
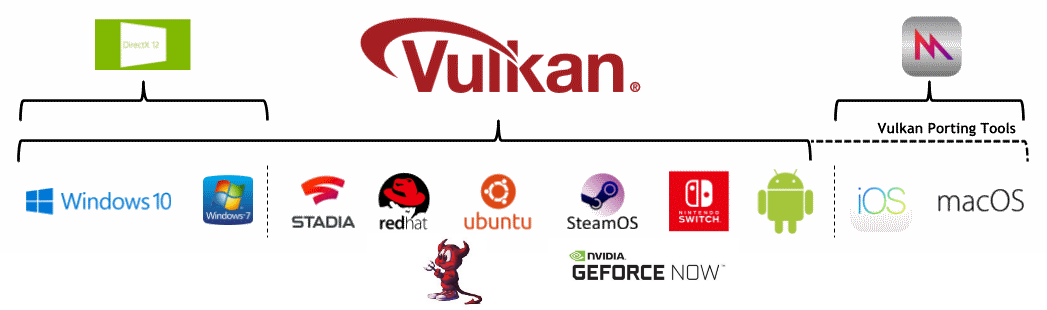
5. Platforms
While Vulkan runs on many platforms, each has small variations on how Vulkan is managed.
5.1. Android
The Vulkan API is available on any Android device starting with API level 24 (Android Nougat), however not all devices will have a Vulkan driver.
Android uses its Hardware Abstraction Layer (HAL) to find the Vulkan Driver in a predefined path.
All 64-bit devices that launch with API level 29 (Android Q) or later must include a Vulkan 1.1 driver.
5.2. BSD Unix
Vulkan is supported on many BSD Unix distributions.
5.3. Fuchsia
Vulkan is supported on the Fuchsia operation system.
5.4. iOS
Vulkan is not natively supported on iOS, but can still be targeted with Vulkan Portability Tools.
5.5. Linux
Vulkan is supported on many Linux distributions.
5.6. MacOS
Vulkan is not natively supported on MacOS, but can still be targeted with Vulkan Portability Tools.
5.7. Nintendo Switch
The Nintendo Switch runs an NVIDIA Tegra chipset that supports native Vulkan.
5.8. QNX
Vulkan is supported on QNX operation system.
5.9. Stadia
Google’s Stadia runs on AMD based Linux machines and Vulkan is the required graphics API.
5.10. Windows
Vulkan is supported on Windows 7, Windows 8, and Windows 10.
5.11. Others
Some embedded systems support Vulkan by allowing presentation directly-to-display.
permalink: /Notes/004-3d-rendering/vulkan/chapters/checking_for_support.html ---
6. Checking For Vulkan Support
Vulkan requires both a Vulkan Loader and a Vulkan Driver (also referred to as a Vulkan Implementation). The driver is in charge of translating Vulkan API calls into a valid implementation of Vulkan. The most common case is a GPU hardware vendor releasing a driver that is used to run Vulkan on a physical GPU. It should be noted that it is possible to have an entire implementation of Vulkan software based, though the performance impact would be very noticeable.
When checking for Vulkan Support it is important to distinguish the difference between platform support and device support.
6.1. Platform Support
The first thing to check is if your platform even supports Vulkan. Each platform uses a different mechanism to manage how the Vulkan Loader is implemented. The loader is then in charge of determining if a Vulkan Driver is exposed correctly.
6.1.1. Android
A simple way of grabbing info on Vulkan is to run the Vulkan Hardware Capability Viewer app developed by Sascha Willems. This app will not only show if Vulkan is supported, but also all the capabilities the device offers.
6.1.2. BSD Unix
Grab the Vulkan SDK. Build Vulkan SDK using the command ./vulkansdk.sh and then run the vulkaninfo executable to easily check for Vulkan support as well as all the capabilities the device offers.
6.1.3. iOS
A simple way of grabbing info on Vulkan is to run the iOS port of the Vulkan Hardware Capability Viewer provided by LunarG. This app will not only show if Vulkan is supported, but also all the capabilities the device offers.
6.1.4. Linux
Grab the Vulkan SDK and run the vulkaninfo executable to easily check for Vulkan support as well as all the capabilities the device offers.
6.1.5. MacOS
Grab the Vulkan SDK and run the vulkaninfo executable to easily check for Vulkan support as well as all the capabilities the device offers.
6.1.6. Windows
Grab the Vulkan SDK and run the vulkaninfo.exe executable to easily check for Vulkan support as well as all the capabilities the device offers.
6.2. Device Support
Just because the platform supports Vulkan does not mean there is device support. For device support, one will need to make sure a Vulkan Driver is available that fully implements Vulkan. There are a few different variations of a Vulkan Driver.
6.2.1. Hardware Implementation
A driver targeting a physical piece of GPU hardware is the most common case for a Vulkan implementation. It is important to understand that while a certain GPU might have the physical capabilities of running Vulkan, it still requires a driver to control it. The driver is in charge of getting the Vulkan calls mapped to the hardware in the most efficient way possible.
Drivers, like any software, are updated and this means there can be many variations of drivers for the same physical device and platform. There is a Vulkan Database, developed and maintained by Sascha Willems, which is the largest collection of recorded Vulkan implementation details
| Note | Just because a physical device or platform isn’t in the Vulkan Database doesn’t mean it couldn’t exist. |
6.2.2. Null Driver
The term “null driver” is given to any driver that accepts Vulkan API calls, but does not do anything with them. This is common for testing interactions with the driver without needing any working implementation backing it. Many uses cases such as creating CTS tests for new features, testing the Validation Layers, and more rely on the idea of a null driver.
Khronos provides the Mock ICD as one implementation of a null driver that works on various platforms.
6.2.3. Software Implementation
It is possible to create a Vulkan implementation that only runs on the CPU. This is useful if there is a need to test Vulkan that is hardware independent, but unlike the null driver, also outputs a valid result.
SwiftShader is an example of CPU-based implementation.
6.3. Ways of Checking for Vulkan
6.3.1. VIA (Vulkan Installation Analyzer)
Included in the Vulkan SDK is a utility to check the Vulkan installation on your computer. It is supported on Windows, Linux, and macOS. VIA can:
-
Determine the state of Vulkan components on your system
-
Validate that your Vulkan Loader and drivers are installed properly
-
Capture your system state in a form that can be used as an attachment when submitting bugs
View the SDK documentation on VIA for more information.
6.3.2. Hello Create Instance
A simple way to check for Vulkan support cross platform is to create a simple “Hello World” Vulkan application. The vkCreateInstance function is used to create a Vulkan Instance and is also the shortest way to write a valid Vulkan application.
The Vulkan SDK provides a minimal vkCreateInstance example 01-init_instance.cpp that can be used.
permalink:/Notes/004-3d-rendering/vulkan/chapters/versions.html layout: default ---
7. Versions
Vulkan works on a major, minor, patch versioning system. Currently, there are 3 minor version releases of Vulkan (1.0, 1.1, 1.2 and 1.3) which are backward compatible with each other. An application can use vkEnumerateInstanceVersion to check what version of a Vulkan instance is supported. There is also a white paper by LunarG on how to query and check for the supported version. While working across minor versions, there are some subtle things to be aware of.
7.1. Instance and Device
It is important to remember there is a difference between the instance-level version and device-level version. It is possible that the loader and implementations will support different versions.
The Querying Version Support section in the Vulkan Spec goes into details on how to query for supported versions at both the instance and device level.
7.2. Header
There is only one supported header for all major releases of Vulkan. This means that there is no such thing as “Vulkan 1.0 headers” as all headers for a minor and patch version are unified. This should not be confused with the ability to generate a 1.0 version of the Vulkan Spec, as the Vulkan Spec and header of the same patch version will match. An example would be that the generated 1.0.42 Vulkan Spec will match the 1.x.42 header.
It is highly recommended that developers try to keep up to date with the latest header files released. The Vulkan SDK comes in many versions which map to the header version it will have been packaged for.
7.3. Extensions
Between minor versions of Vulkan, some extensions get promoted to the core version. When targeting a newer minor version of Vulkan, an application will not need to enable the newly promoted extensions at the instance and device creation. However, if an application wants to keep backward compatibility, it will need to enable the extensions.
For a summary of what is new in each version, check out the Vulkan Release Summary
7.4. Structs and enums
Structs and enums are dependent on the header file being used and not the version of the instance or device queried. For example, the struct VkPhysicalDeviceFeatures2 used to be VkPhysicalDeviceFeatures2KHR before Vulkan 1.1 was released. Regardless of the 1.x version of Vulkan being used, an application should use VkPhysicalDeviceFeatures2 in its code as it matches the newest header version. For applications that did have VkPhysicalDeviceFeatures2KHR in the code, there is no need to worry as the Vulkan header also aliases any promoted structs and enums (typedef VkPhysicalDeviceFeatures2 VkPhysicalDeviceFeatures2KHR;).
The reason for using the newer naming is that the Vulkan Spec itself will only refer to VkPhysicalDeviceFeatures2 regardless of what version of the Vulkan Spec is generated. Using the newer naming makes it easier to quickly search for where the structure is used.
7.5. Functions
Since functions are used to interact with the loader and implementations, there needs to be a little more care when working between minor versions. As an example, let’s look at vkGetPhysicalDeviceFeatures2KHR which was promoted to core as vkGetPhysicalDeviceFeatures2 from Vulkan 1.0 to Vulkan 1.1. Looking at the Vulkan header both are declared.
typedef void (VKAPI_PTR *PFN_vkGetPhysicalDeviceFeatures2)(VkPhysicalDevice physicalDevice, VkPhysicalDeviceFeatures2* pFeatures);
// ...
typedef void (VKAPI_PTR *PFN_vkGetPhysicalDeviceFeatures2KHR)(VkPhysicalDevice physicalDevice, VkPhysicalDeviceFeatures2* pFeatures);The main difference is when calling vkGetInstanceProcAddr(instance, “vkGetPhysicalDeviceFeatures2”); a Vulkan 1.0 implementation may not be aware of vkGetPhysicalDeviceFeatures2 existence and vkGetInstanceProcAddr will return NULL. To be backward compatible with Vulkan 1.0 in this situation, the application should query for vkGetPhysicalDeviceFeatures2KHR as a 1.1 Vulkan implementation will likely have the function directly pointed to the vkGetPhysicalDeviceFeatures2 function pointer internally.
| Note | The |
7.6. Features
Between minor versions, it is possible that some feature bits are added, removed, made optional, or made mandatory. All details of features that have changed are described in the Core Revisions section.
The Feature Requirements section in the Vulkan Spec can be used to view the list of features that are required from implementations across minor versions.
7.7. Limits
Currently, all versions of Vulkan share the same minimum/maximum limit requirements, but any changes would be listed in the Limit Requirements section of the Vulkan Spec.
7.8. SPIR-V
Every minor version of Vulkan maps to a version of SPIR-V that must be supported.
-
Vulkan 1.0 supports SPIR-V 1.0
-
Vulkan 1.1 supports SPIR-V 1.3 and below
-
Vulkan 1.2 supports SPIR-V 1.5 and below
-
Vulkan 1.3 supports SPIR-V 1.6 and below
It is up to the application to make sure that the SPIR-V in VkShaderModule is of a valid version to the corresponding Vulkan version.
permalink:/Notes/004-3d-rendering/vulkan/chapters/vulkan_release_summary.html layout: default ---
8. Vulkan Release Summary
Each minor release version of Vulkan promoted a different set of extension to core. This means that it’s no longer necessary to enable an extensions to use it’s functionality if the application requests at least that Vulkan version (given that the version is supported by the implementation).
The following summary contains a list of the extensions added to the respective core versions and why they were added. This list is taken from the Vulkan spec, but links jump to the various spots in the Vulkan Guide
8.1. Vulkan 1.1
| Note |
Vulkan 1.1 was released on March 7, 2018
Besides the listed extensions below, Vulkan 1.1 introduced the subgroups, protected memory, and the ability to query the instance version.
8.2. Vulkan 1.2
| Note |
Vulkan 1.2 was released on January 15, 2020
8.3. Vulkan 1.3
| Note |
Vulkan 1.3 was released on January 25, 2022
permalink: /Notes/004-3d-rendering/vulkan/chapters/what_is_spirv.html layout: default ---
9. What is SPIR-V
| Note | Please read the SPIRV-Guide for more in detail information about SPIR-V |
SPIR-V is a binary intermediate representation for graphical-shader stages and compute kernels. With Vulkan, an application can still write their shaders in a high-level shading language such as GLSL or HLSL, but a SPIR-V binary is needed when using vkCreateShaderModule. Khronos has a very nice white paper about SPIR-V and its advantages, and a high-level description of the representation. There are also two great Khronos presentations from Vulkan DevDay 2016 here and here (video of both).
9.1. SPIR-V Interface and Capabilities
Vulkan has an entire section that defines how Vulkan interfaces with SPIR-V shaders. Most valid usages of interfacing with SPIR-V occur during pipeline creation when shaders are compiled together.
SPIR-V has many capabilities as it has other targets than just Vulkan. To see the supported capabilities Vulkan requires, one can reference the Appendix. Some extensions and features in Vulkan are just designed to check if some SPIR-V capabilities are supported or not.
9.2. Compilers
9.2.1. glslang
glslang is the Khronos reference front-end for GLSL, HLSL and ESSL, and sample SPIR-V generator. There is a standalone glslangValidator tool that is included that can be used to create SPIR-V from GLSL, HLSL and ESSL.
9.2.2. Shaderc
A collection of tools, libraries, and tests for Vulkan shader compilation hosted by Google. It contains glslc which wraps around core functionality in glslang and SPIRV-Tools. Shaderc also contains spvc which wraps around core functionality in SPIRV-Cross and SPIRV-Tools.
Shaderc builds both tools as a standalone command line tool (glslc) as well as a library to link to (libshaderc).
9.2.4. Clspv
Clspv is a prototype compiler for a subset of OpenCL C to SPIR-V to be used as Vulkan compute shaders.
9.3. Tools and Ecosystem
There is a rich ecosystem of tools to take advantage of SPIR-V. The Vulkan SDK gives an overview of all the SPIR-V tools that are built and packaged for developers.
9.3.1. SPIRV-Tools
The Khronos SPIRV-Tools project provides C and C++ APIs and a command line interface to work with SPIR-V modules. More information in the SPIRV-Guide.
9.3.2. SPIRV-Cross
The Khronos SPIRV-Cross project is a practical tool and library for performing reflection on SPIR-V and disassembling SPIR-V back to a desired high-level shading language. For more details, Hans Kristian, the main developer of SPIR-V Cross, has given two great presentations about what it takes to create a tool such as SPIR-V Cross from 2018 Vulkanised (video) and 2019 Vulkanised (video)
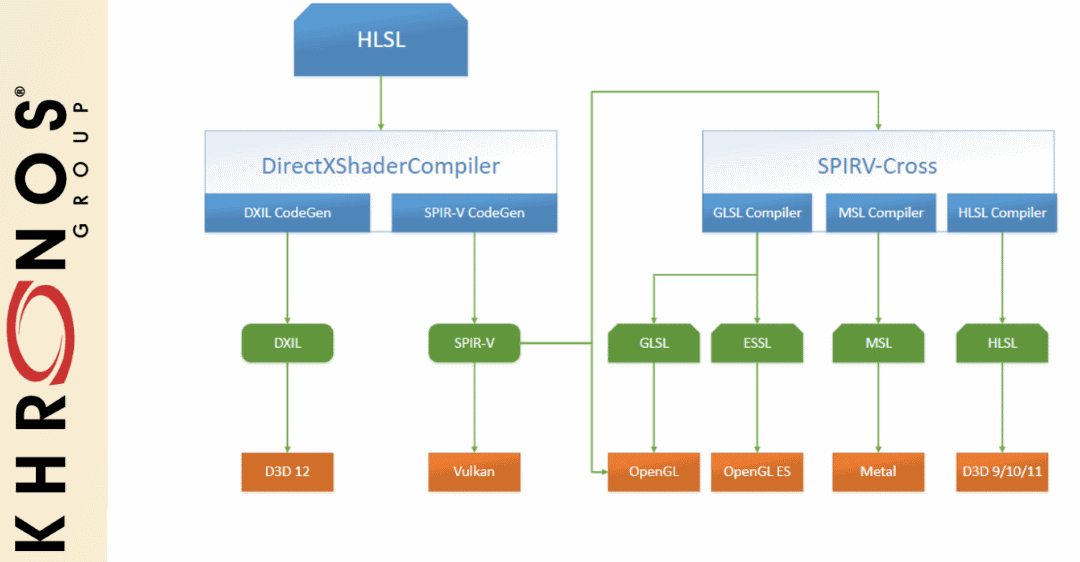
9.3.3. SPIRV-LLVM
The Khronos SPIRV-LLVM project is a LLVM framework with SPIR-V support. It’s intended to contain a bi-directional converter between LLVM and SPIR-V. It also serves as a foundation for LLVM-based front-end compilers targeting SPIR-V.
permalink:/Notes/004-3d-rendering/vulkan/chapters/portability_initiative.html layout: default ---
10. Portability Initiative
| Note | Notice Currently a provisional VK_KHR_portability_subset extension specification is available with the vulkan_beta.h headers. More information can found in the press release. |
The Vulkan Portability Initiative is an effort inside the Khronos Group to develop resources to define and evolve the subset of Vulkan capabilities that can be made universally available at native performance levels across all major platforms, including those not currently served by Vulkan native drivers. In a nutshell, this initiative is about making Vulkan viable on platforms that do not natively support the API (e.g MacOS and iOS).
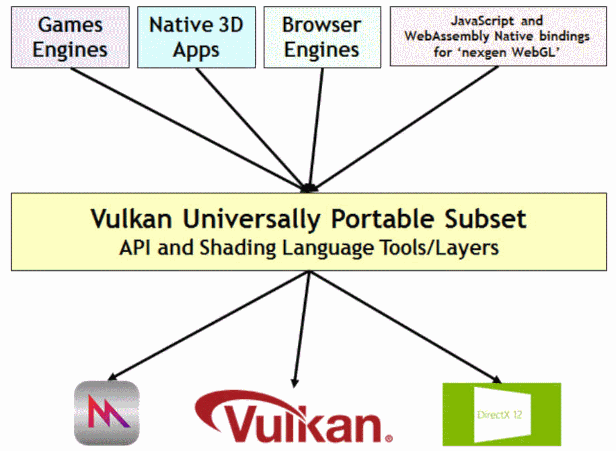
10.1. Translation Layer
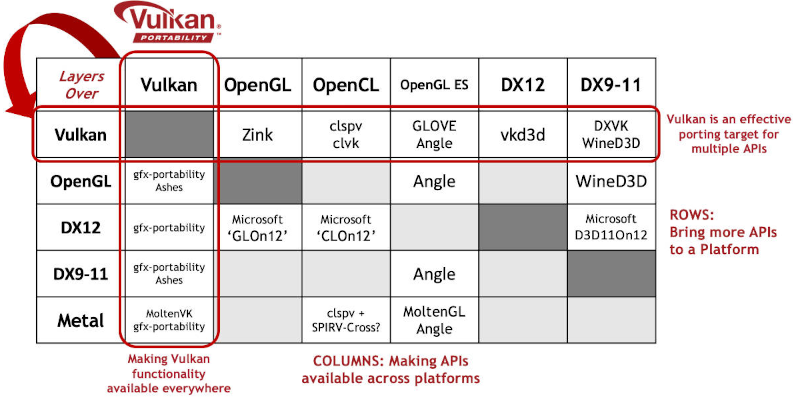
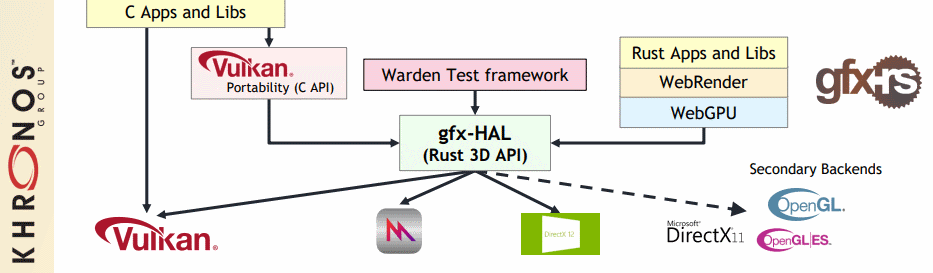
Layered implementations fight industry fragmentation by enabling more applications to run on more platforms, even in a fragmented industry API landscape. For example, the first row in the diagram below shows how Vulkan is being used as a porting target to bring additional APIs to platforms to enable more content without the need for additional kernel-level drivers. Layered API implementations have been used to successfully ship production applications on multiple platforms.
The columns in the figure show layering projects being used to make APIs available across additional platforms, even if no native drivers are available, giving application developers the deployment flexibility they need to develop with the graphics API of their choice and ship across multiple platforms. The first column in the diagram is the work of the Vulkan Portability Initiative, enabling layered implementations of Vulkan functionality across diverse platforms.
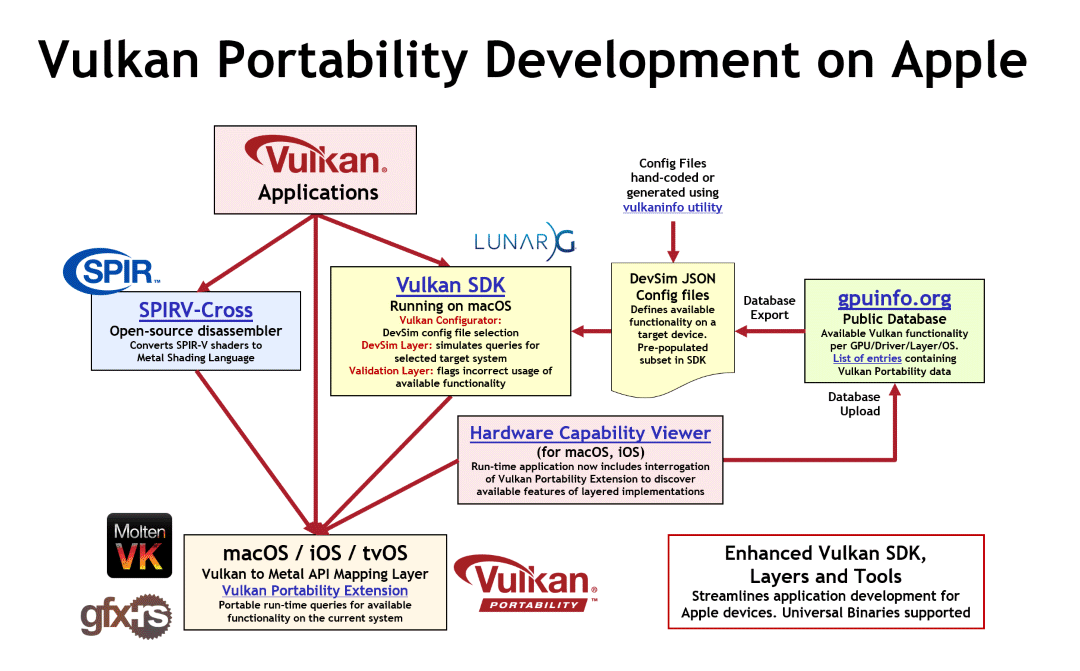
10.3. gfx-rs
Mozilla is currently helping drive gfx-rs portability to use gfx-hal as a way to interface with various other APIs.
permalink:/Notes/004-3d-rendering/vulkan/chapters/vulkan_cts.html layout: default ---
11. Vulkan CTS
The Vulkan Conformance Tests Suite (CTS) is a set of tests used to verify the conformance of an implementation. A conformant implementation shows that it has successfully passed CTS and it is a valid implementation of Vulkan. A list of conformant products is publicly available.
Any company with a conformant implementation may freely use the publicly released Vulkan specification to create a product. All implementations of the Vulkan API must be tested for conformance in the Khronos Vulkan Adopter Program before the Vulkan name or logo may be used in association with an implementation of the API.
The Vulkan CTS source code is freely available and anyone is free to create and add a new test to the Vulkan CTS as long as they follow the Contributing Wiki.
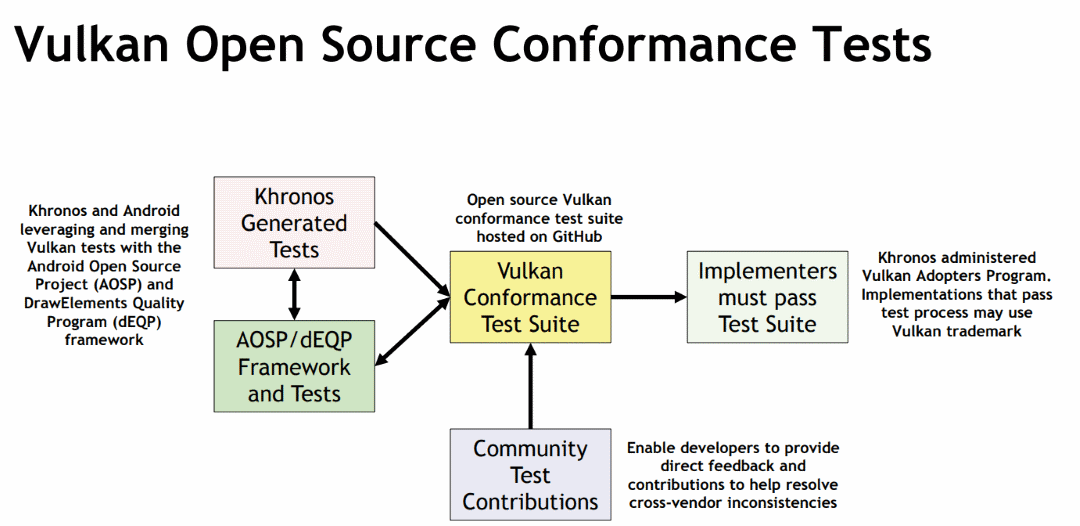
An application can query the version of CTS passed for an implementation using the VkConformanceVersion property via the VK_KHR_driver_properties extension (this was promoted to core in Vulkan 1.2).
permalink: /Notes/004-3d-rendering/vulkan/chapters/development_tools.html ---
12. Development Tools
The Vulkan ecosystem consists of many tools for development. This is not a full list and this is offered as a good starting point for many developers. Please continue to do your own research and search for other tools as the development ecosystem is much larger than what can reasonably fit on a single Markdown page.
Khronos hosts Vulkan Samples, a collection of code and tutorials that demonstrates API usage and explains the implementation of performance best practices.
LunarG is privately sponsored to develop and maintain Vulkan ecosystem components and is currently the curator for the Vulkan Loader and Vulkan Validation Layers Khronos Group repositories. In addition, LunarG delivers the Vulkan SDK and develops other key tools such as the Vulkan Configurator and GFXReconstruct.
12.1. Vulkan Layers
Layers are optional components that augment the Vulkan system. They can intercept, evaluate, and modify existing Vulkan functions on their way from the application down to the hardware. Layers are implemented as libraries that can be enabled and configured using Vulkan Configurator.
12.1.1. Khronos Layers
-
VK_LAYER_KHRONOS_validation, the Khronos Validation Layer. It is every developer’s first layer of defense when debugging their Vulkan application and this is the reason it is at the top of this list. Read the Validation Overview chapter for more details. The validation layer included multiple features:-
Synchronization Validation: Identify resource access conflicts due to missing or incorrect synchronization operations between actions (Draw, Copy, Dispatch, Blit) reading or writing the same regions of memory.
-
GPU-Assisted Validation: Instrument shader code to perform run-time checks for error conditions produced during shader execution.
-
Shader printf: Debug shader code by “printing” any values of interest to the debug callback or stdout.
-
Best Practices Warnings: Highlights potential performance issues, questionable usage patterns, common mistakes.
-
-
VK_LAYER_KHRONOS_synchronization2, the Khronos Synchronization2 layer. TheVK_LAYER_KHRONOS_synchronization2layer implements theVK_KHR_synchronization2extension. By default, it will disable itself if the underlying driver provides the extension.
12.1.2. Vulkan SDK layers
Besides the Khronos Layers, the Vulkan SDK included additional useful platform independent layers.
-
VK_LAYER_LUNARG_api_dump, a layer to log Vulkan API calls. The API dump layer prints API calls, parameters, and values to the identified output stream. -
VK_LAYER_LUNARG_gfxreconstruct, a layer for capturing frames created with Vulkan. This layer is a part of GFXReconstruct, a software for capturing and replaying Vulkan API calls. Full Android support is also available at https://github.com/LunarG/gfxreconstruct -
VK_LAYER_LUNARG_device_simulation, a layer to test Vulkan applications portability. The device simulation layer can be used to test whether a Vulkan application would run on a Vulkan device with lower capabilities. -
VK_LAYER_LUNARG_screenshot, a screenshot layer. Captures the rendered image of a Vulkan application to a viewable image. -
VK_LAYER_LUNARG_monitor, a framerate monitor layer. Display the Vulkan application FPS in the window title bar to give a hint about the performance.
12.1.3. Vulkan Third-party layers
There are also other publicly available layers that can be used to help in development.
-
VK_LAYER_ARM_mali_perf_doc, the ARM PerfDoc layer. Checks Vulkan applications for best practices on Arm Mali devices. -
VK_LAYER_IMG_powervr_perf_doc, the PowerVR PerfDoc layer. Checks Vulkan applications for best practices on Imagination Technologies PowerVR devices. -
VK_LAYER_adreno, the Vulkan Adreno Layer. Checks Vulkan applications for best practices on Qualcomm Adreno devices.
12.2. Debugging
Debugging something running on a GPU can be incredibly hard, luckily there are tools out there to help.
12.3. Profiling
With anything related to a GPU it is best to not assume and profile when possible. Here is a list of known profilers to aid in your development.
-
AMD Radeon GPU Profiler - Low-level performance analysis tool for AMD Radeon GPUs.
-
Arm Streamline Performance Analyzer - Visualize the performance of mobile games and applications for a broad range of devices, using Arm Mobile Studio.
-
Intel® GPA - Intel’s Graphics Performance Analyzers that supports capturing and analyzing multi-frame streams of Vulkan apps.
-
OCAT - The Open Capture and Analytics Tool (OCAT) provides an FPS overlay and performance measurement for D3D11, D3D12, and Vulkan.
-
Qualcomm Snapdragon Profiler - Profiling tool targeting Adreno GPU.
-
VKtracer - Cross-vendor and cross-platform profiler.
permalink:/Notes/004-3d-rendering/vulkan/chapters/validation_overview.html layout: default ---
13. Vulkan Validation Overview
| Note | The purpose of this section is to give a full overview of how Vulkan deals with valid usage of the API. |
13.1. Valid Usage (VU)
A VU is explicitly defined in the Vulkan Spec as:
| Note | set of conditions that must be met in order to achieve well-defined run-time behavior in an application. |
One of the main advantages of Vulkan, as an explicit API, is that the implementation (driver) doesn’t waste time checking for valid input. In OpenGL, the implementation would have to always check for valid usage which added noticeable overhead. There is no glGetError equivalent in Vulkan.
The valid usages will be listed in the spec after every function and structure. For example, if a VUID checks for an invalid VkImage at VkBindImageMemory then the valid usage in the spec is found under VkBindImageMemory. This is because the Validation Layers will only know about all the information at VkBindImageMemory during the execution of the application.
13.2. Undefined Behavior
When an application supplies invalid input, according to the valid usages in the spec, the result is undefined behavior. In this state, Vulkan makes no guarantees as anything is possible with undefined behavior.
VERY IMPORTANT: While undefined behavior might seem to work on one implementation, there is a good chance it will fail on another.
13.3. Valid Usage ID (VUID)
A VUID is an unique ID given to each valid usage. This allows a way to point to a valid usage in the spec easily.
Using VUID-vkBindImageMemory-memoryOffset-01046 as an example, it is as simple as adding the VUID to an anchor in the HMTL version of the spec (vkspec.html#VUID-vkBindImageMemory-memoryOffset-01046) and it will jump right to the VUID.
13.4. Khronos Validation Layer
Since Vulkan doesn’t do any error checking, it is very important, when developing, to enable the Validation Layers right away to help catch invalid behavior. Applications should also never ship the Validation Layers with their application as they noticeably reduce performance and are designed for the development phase.
| Note | The Khronos Validation Layer used to consist of multiple layers but now has been unified to a single |
13.4.1. Getting Validation Layers
The Validation Layers are constantly being updated and improved so it is always possible to grab the source and build it yourself. In case you want a prebuit version there are various options for all supported platforms:
-
Android - Binaries are released on GitHub with most up to date version. The NDK will also comes with the Validation Layers built and information on how to use them.
-
Linux - The Vulkan SDK comes with the Validation Layers built and instructions on how to use them on Linux.
-
MacOS - The Vulkan SDK comes with the Validation Layers built and instructions on how to use them on MacOS.
-
Windows - The Vulkan SDK comes with the Validation Layers built and instructions on how to use them on Windows.
13.5. Breaking Down a Validation Error Message
The Validation Layers attempt to supply as much useful information as possible when an error occurs. The following examples are to help show how to get the most information out of the Validation Layers
13.5.1. Example 1 - Implicit Valid Usage
This example shows a case where an implicit VU is triggered. There will not be a number at the end of the VUID.
Validation Error: [ VUID-vkBindBufferMemory-memory-parameter ] Object 0: handle =
0x20c8650, type = VK_OBJECT_TYPE_INSTANCE; | MessageID = 0xe9199965 | Invalid
VkDeviceMemory Object 0x60000000006. The Vulkan spec states: memory must be a valid
VkDeviceMemory handle (https://www.khronos.org/registry/vulkan/specs/1.1-extensions/
html/vkspec.html#VUID-vkBindBufferMemory-memory-parameter)-
The first thing to notice is the VUID is listed first in the message (
VUID-vkBindBufferMemory-memory-parameter)-
There is also a link at the end of the message to the VUID in the spec
-
-
The Vulkan spec states:is the quoted VUID from the spec. -
The
VK_OBJECT_TYPE_INSTANCEis the VkObjectType -
Invalid VkDeviceMemory Object 0x60000000006is the Dispatchable Handle to help show whichVkDeviceMemoryhandle was the cause of the error.
13.5.2. Example 2 - Explicit Valid Usage
This example shows an error where some VkImage is trying to be bound to 2 different VkDeviceMemory objects
Validation Error: [ VUID-vkBindImageMemory-image-01044 ] Object 0: handle =
0x90000000009, name = myTextureMemory, type = VK_OBJECT_TYPE_DEVICE_MEMORY; Object 1:
handle = 0x70000000007, type = VK_OBJECT_TYPE_IMAGE; Object 2: handle = 0x90000000006,
name = myIconMemory, type = VK_OBJECT_TYPE_DEVICE_MEMORY; | MessageID = 0x6f3eac96 |
In vkBindImageMemory(), attempting to bind VkDeviceMemory 0x90000000009[myTextureMemory]
to VkImage 0x70000000007[] which has already been bound to VkDeviceMemory
0x90000000006[myIconMemory]. The Vulkan spec states: image must not already be
backed by a memory object (https://www.khronos.org/registry/vulkan/specs/1.1-extensions/
html/vkspec.html#VUID-vkBindImageMemory-image-01044)-
Example 2 is about the same as Example 1 with the exception that the
namethat was attached to the object (name = myTextureMemory). This was done using the VK_EXT_debug_util extension (Sample of how to use the extension). Note that the old way of using VK_EXT_debug_report might be needed on legacy devices that don’t supportVK_EXT_debug_util. -
There were 3 objects involved in causing this error.
-
Object 0 is a
VkDeviceMemorynamedmyTextureMemory -
Object 1 is a
VkImagewith no name -
Object 2 is a
VkDeviceMemorynamedmyIconMemory
-
-
With the names it is easy to see “In
vkBindImageMemory(), themyTextureMemorymemory was attempting to bind to an image already been bound to themyIconMemorymemory”.
Each error message contains a uniform logging pattern. This allows information to be easily found in any error. The pattern is as followed:
-
Log status (ex.
Error:,Warning:, etc) -
The VUID
-
Array of objects involved
-
Index of array
-
Dispatch Handle value
-
Optional name
-
Object Type
-
-
Function or struct error occurred in
-
Message the layer has created to help describe the issue
-
The full Valid Usage from the spec
-
Link to the Valid Usage
13.6. Multiple VUIDs
| Note | The following is not ideal and is being looked into how to make it simpler |
Currently, the spec is designed to only show the VUIDs depending on the version and extensions the spec was built with. Simply put, additions of extensions and versions may alter the VU language enough (from new API items added) that a separate VUID is created.
An example of this from the Vulkan-Docs where the spec in generated from
* [[VUID-VkPipelineLayoutCreateInfo-pSetLayouts-00287]]
...What this creates is two very similar VUIDs
In this example, both VUIDs are very similar and the only difference is the fact VK_DESCRIPTOR_SET_LAYOUT_CREATE_UPDATE_AFTER_BIND_POOL_BIT is referenced in one and not this other. This is because the enum was added with the addition of VK_EXT_descriptor_indexing which is now part of Vulkan 1.2.
This means the 2 valid html links to the spec would look like
-
1.1/html/vkspec.html#VUID-VkPipelineLayoutCreateInfo-pSetLayouts-00287 -
1.2/html/vkspec.html#VUID-VkPipelineLayoutCreateInfo-descriptorType-03016
The Validation Layer uses the device properties of the application in order to decide which one to display. So in this case, if you are running on a Vulkan 1.2 implementation or a device that supports VK_EXT_descriptor_indexing it will display the VUID 03016.
13.7. Special Usage Tags
The Best Practices layer will produce warnings when an application tries to use any extension with special usage tags. An example of such an extension is VK_EXT_transform_feedback which is only designed for emulation layers. If an application’s intended usage corresponds to one of the special use cases, the following approach will allow you to ignore the warnings.
Ignoring Special Usage Warnings with VK_EXT_debug_report
VkBool32 DebugReportCallbackEXT(/* ... */ const char* pMessage /* ... */)
{
// If pMessage contains "specialuse-extension", then exit
if(strstr(pMessage, "specialuse-extension") != NULL) {
return VK_FALSE;
};
// Handle remaining validation messages
}Ignoring Special Usage Warnings with VK_EXT_debug_utils
VkBool32 DebugUtilsMessengerCallbackEXT(/* ... */ const VkDebugUtilsMessengerCallbackDataEXT* pCallbackData /* ... */)
{
// If pMessageIdName contains "specialuse-extension", then exit
if(strstr(pCallbackData->pMessageIdName, "specialuse-extension") != NULL) {
return VK_FALSE;
};
// Handle remaining validation messages
}permalink: /Notes/004-3d-rendering/vulkan/chapters/decoder_ring.html ---
14. Vulkan Decoder Ring
This section provides a mapping between the Vulkan term for a concept and the terminology used in other APIs. It is organized in alphabetical order by Vulkan term. If you are searching for the Vulkan equivalent of a concept used in an API you know, you can find the term you know in this list and then search the Vulkan specification for the corresponding Vulkan term.
| Note | Not everything will be a perfect 1:1 match, the goal is to give a rough idea where to start looking in the spec. |
| Vulkan | GL,GLES | DirectX | Metal |
|---|---|---|---|
buffer device address | GPU virtual address | ||
buffer view, texel buffer | texture buffer | typed buffer SRV, typed buffer UAV | texture buffer |
color attachments | color attachments | render target | color attachments or render target |
command buffer | part of context, display list, NV_command_list | command list | command buffer |
command pool | part of context | command allocator | command queue |
conditional rendering | conditional rendering | predication | |
depth/stencil attachment | depth Attachment and stencil Attachment | depth/stencil view | depth attachment and stencil attachment, depth render target and stencil render target |
descriptor | descriptor | argument | |
descriptor pool | descriptor heap | heap | |
descriptor set | descriptor table | argument buffer | |
descriptor set layout binding, push descriptor | root parameter | argument in shader parameter list | |
device group | implicit (E.g. SLI,CrossFire) | multi-adapter device | peer group |
device memory | heap | placement heap | |
event | split barrier | ||
fence | fence, sync |
| completed handler, |
fragment shader | fragment shader | pixel shader | fragment shader or fragment function |
fragment shader interlock | rasterizer order view (ROV) | raster order group | |
framebuffer | framebuffer object | collection of resources | |
heap | pool | ||
image | texture and renderbuffer | texture | texture |
image layout | resource state | ||
image tiling | image layout, swizzle | ||
image view | texture view | render target view, depth/stencil view, shader resource view, unordered access view | texture view |
interface matching ( | varying (removed in GLSL 4.20) | Matching semantics | |
invocation | invocation | thread, lane | thread, lane |
layer | slice | slice | |
logical device | context | device | device |
memory type | automatically managed, texture storage hint, buffer storage | heap type, CPU page property | storage mode, CPU cache mode |
multiview rendering | multiview rendering | view instancing | vertex amplification |
physical device | adapter, node | device | |
pipeline | state and program or program pipeline | pipeline state | pipeline state |
pipeline barrier, memory barrier | texture barrier, memory barrier | resource barrier | texture barrier, memory barrier |
pipeline layout | root signature | ||
queue | part of context | command queue | command queue |
semaphore | fence, sync | fence | fence, event |
shader module | shader object | resulting | shader library |
shading rate attachment | shading rate image | rasterization rate map | |
sparse block | sparse block | tile | sparse tile |
sparse image | sparse texture | reserved resource (D12), tiled resource (D11) | sparse texture |
storage buffer | shader storage buffer | raw or structured buffer UAV | buffer in |
subgroup | subgroup | wave | SIMD-group, quadgroup |
surface | HDC, GLXDrawable, EGLSurface | window | layer |
swapchain | Part of HDC, GLXDrawable, EGLSurface | swapchain | layer |
swapchain image | default framebuffer | drawable texture | |
task shader | amplification shader | ||
tessellation control shader | tessellation control shader | hull shader | tessellation compute kernel |
tessellation evaluation shader | tessellation evaluation shader | domain shader | post-tessellation vertex shader |
timeline semaphore | D3D12 fence | event | |
transform feedback | transform feedback | stream-out | |
uniform buffer | uniform buffer | constant buffer views (CBV) | buffer in |
workgroup | workgroup | threadgroup | threadgroup |
15. Using Vulkan
permalink: /Notes/004-3d-rendering/vulkan/chapters/loader.html ---
16. Loader
The loader is responsible for mapping an application to Vulkan layers and Vulkan installable client drivers (ICD).
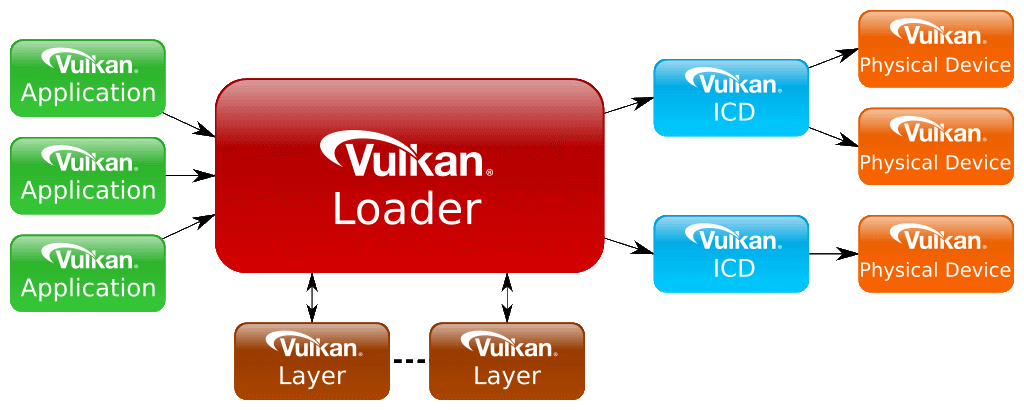
Anyone can create their own Vulkan Loader, as long as they follow the Loader Interface. One can build the reference loader as well or grab a built version from the Vulkan SDK for selected platforms.
16.1. Linking Against the Loader
The Vulkan headers only provide the Vulkan function prototypes. When building a Vulkan application you have to link it to the loader or you will get errors about undefined references to the Vulkan functions. There are two ways of linking the loader, directly and indirectly, which should not be confused with “static and dynamic linking”.
-
Directly linking at compile time
-
This requires having a built Vulkan Loader (either as a static or dynamic library) that your build system can find.
-
Build systems (Visual Studio, CMake, etc) have documentation on how to link to the library. Try searching “(InsertBuildSystem) link to external library” online.
-
-
Indirectly linking at runtime
-
Using dynamic symbol lookup (via system calls such as
dlsymanddlopen) an application can initialize its own dispatch table. This allows an application to fail gracefully if the loader cannot be found. It also provides the fastest mechanism for the application to call Vulkan functions. -
Volk is an open source implementation of a meta-loader to help simplify this process.
-
16.2. Platform Variations
Each platform can set its own rules on how to enforce the Vulkan Loader.
16.2.1. Android
Android devices supporting Vulkan provide a Vulkan loader already built into the OS.
A vulkan_wrapper.c/h file is provided in the Android NDK for indirectly linking. This is needed, in part, because the Vulkan Loader can be different across different vendors and OEM devices.
16.2.2. Linux
The Vulkan SDK provides a pre-built loader for Linux.
The Getting Started page in the Vulkan SDK explains how the loader is found on Linux.
16.2.3. MacOS
The Vulkan SDK provides a pre-built loader for MacOS
The Getting Started page in the Vulkan SDK explains how the loader is found on MacOS.
16.2.4. Windows
The Vulkan SDK provides a pre-built loader for Windows.
The Getting Started page in the Vulkan SDK explains how the loader is found on Windows.
permalink: /Notes/004-3d-rendering/vulkan/chapters/layers.html ---
17. Layers
Layers are optional components that augment the Vulkan system. They can intercept, evaluate, and modify existing Vulkan functions on their way from the application down to the hardware. Layer properties can be queried from an application with vkEnumerateInstanceLayerProperties.
17.1. Using Layers
Layers are packaged as shared libraries that get dynamically loaded in by the loader and inserted between it and the application. The two things needed to use layers are the location of the binary files and which layers to enable. The layers to use can be either explicitly enabled by the application or implicitly enabled by telling the loader to use them. More details about implicit and explicit layers can be found in the Loader and Layer Interface.
The Vulkan SDK contains a layer configuration document that is very specific to how to discover and configure layers on each of the platforms.
17.2. Vulkan Configurator Tool
Developers on Windows, Linux, and macOS can use the Vulkan Configurator, vkconfig, to enable explicit layers and disable implicit layers as well as change layer settings from a graphical user interface. Please see the Vulkan Configurator documentation in the Vulkan SDK for more information on using the Vulkan Configurator.
17.3. Device Layers Deprecation
There used to be both instance layers and device layers, but device layers were deprecated early in Vulkan’s life and should be avoided.
17.4. Creating a Layer
Anyone can create a layer as long as it follows the loader to layer interface which is how the loader and layers agree to communicate with each other.
LunarG provides a framework for layer creation called the Layer Factory to help develop new layers (Video presentation). The layer factory hides the majority of the loader-layer interface, layer boilerplate, setup and initialization, and complexities of layer development. During application development, the ability to easily create a layer to aid in debugging your application can be useful. For more information, see the Vulkan Layer Factory documentation.
17.5. Platform Variations
The way to load a layer in implicitly varies between loader and platform.
17.5.1. Android
As of Android P (Android 9 / API level 28), if a device is in a debuggable state such that getprop ro.debuggable returns 1, then the loader will look in /data/local/debug/vulkan.
Starting in Android P (Android 9 / API level 28) implicit layers can be pushed using ADB if the application was built in debug mode.
There is no way other than the options above to use implicit layers.
17.5.2. Linux
The Vulkan SDK explains how to use implicit layers on Linux.
17.5.3. MacOS
The Vulkan SDK explains how to use implicit layers on MacOS.
17.5.4. Windows
The Vulkan SDK explains how to use implicit layers on Windows.
permalink:/Notes/004-3d-rendering/vulkan/chapters/querying_extensions_features.html layout: default ---
18. Querying Properties, Extensions, Features, Limits, and Formats
One of Vulkan’s main features is that is can be used to develop on multiple platforms and devices. To make this possible, an application is responsible for querying the information from each physical device and then basing decisions on this information.
The items that can be queried from a physical device
-
Properties
-
Features
-
Extensions
-
Limits
-
Formats
18.1. Properties
There are many other components in Vulkan that are labeled as properties. The term “properties” is an umbrella term for any read-only data that can be queried.
18.2. Extensions
| Note | Check out the Enabling Extensions chapter for more information. There is a Registry with all available extensions. |
There are many times when a set of new functionality is desired in Vulkan that doesn’t currently exist. Extensions have the ability to add new functionality. Extensions may define new Vulkan functions, enums, structs, or feature bits. While all of these extended items are found by default in the Vulkan Headers, it is undefined behavior to use extended Vulkan if the extensions are not enabled.
18.3. Features
| Note | Checkout the Enabling Features chapter for more information. |
Features describe functionality which is not supported on all implementations. Features can be queried and then enabled when creating the VkDevice. Besides the list of all features, some features are mandatory due to newer Vulkan versions or use of extensions.
A common technique is for an extension to expose a new struct that can be passed through pNext that adds more features to be queried.
18.4. Limits
Limits are implementation-dependent minimums, maximums, and other device characteristics that an application may need to be aware of. Besides the list of all limits, some limits also have minimum/maximum required values guaranteed from a Vulkan implementation.
18.5. Formats
Vulkan provides many VkFormat that have multiple VkFormatFeatureFlags each holding a various VkFormatFeatureFlagBits bitmasks that can be queried.
Checkout the Format chapter for more information.
18.6. Tools
There are a few tools to help with getting all the information in a quick and in a human readable format.
vulkaninfo is a command line utility for Windows, Linux, and macOS that enables you to see all the available items listed above about your GPU. Refer to the Vulkaninfo documentation in the Vulkan SDK.
The Vulkan Hardware Capability Viewer app developed by Sascha Willems, is an Android app to display all details for devices that support Vulkan.
permalink: /Notes/004-3d-rendering/vulkan/chapters/enabling_extensions.html ---
19. Enabling Extensions
This section goes over the logistics for enabling extensions.
19.1. Two types of extensions
There are two groups of extensions, instance extensions and device extensions. Simply put, instance extensions are tied to the entire VkInstance while device extensions are tied to only a single VkDevice instance.
This information is documented under the “Extension Type” section of each extension reference page. Example below:

19.2. Check for support
An application can query the physical device first to check if the extension is supported with vkEnumerateInstanceExtensionProperties or vkEnumerateDeviceExtensionProperties.
// Simple example
uint32_t count = 0;
vkEnumerateDeviceExtensionProperties(physicalDevice, nullptr, &count, nullptr);
std::vector<VkExtensionProperties> extensions(count);
vkEnumerateDeviceExtensionProperties(physicalDevice, nullptr, &count, extensions.data());
// Checking for support of VK_KHR_bind_memory2
for (uint32_t i = 0; i < count; i++) {
if (strcmp(VK_KHR_BIND_MEMORY_2_EXTENSION_NAME, extensions[i].extensionName) == 0) {
break; // VK_KHR_bind_memory2 is supported
}
}19.3. Enable the Extension
Even if the extension is supported by the implementation, it is undefined behavior to use the functionality of the extension unless it is enabled at VkInstance or VkDevice creation time.
Here is an example of what is needed to enable an extension such as VK_KHR_driver_properties.

// VK_KHR_get_physical_device_properties2 is required to use VK_KHR_driver_properties
// since it's an instance extension it needs to be enabled before at VkInstance creation time
std::vector<const char*> instance_extensions;
instance_extensions.push_back(VK_KHR_GET_PHYSICAL_DEVICE_PROPERTIES_2_EXTENSION_NAME);
VkInstanceCreateInfo instance_create_info = {};
instance_create_info.enabledExtensionCount = static_cast<uint32_t>(instance_extensions.size());
instance_create_info.ppEnabledExtensionNames = instance_extensions.data();
vkCreateInstance(&instance_create_info, nullptr, &myInstance));
// ...
std::vector<const char*> device_extensions;
device_extensions.push_back(VK_KHR_DRIVER_PROPERTIES_EXTENSION_NAME);
VkDeviceCreateInfo device_create_info = {};
device_create_info.enabledExtensionCount = static_cast<uint32_t>(device_extensions.size());
device_create_info.ppEnabledExtensionNames = device_extensions.data();
vkCreateDevice(physicalDevice, &device_create_info, nullptr, &myDevice);19.4. Check for feature bits
It is important to remember that extensions add the existence of functionality to the Vulkan spec, but this doesn’t mean that all features of an extension are available if the extension is supported. An example is an extension such as VK_KHR_8bit_storage, which has 3 features it exposes in VkPhysicalDevice8BitStorageFeatures.
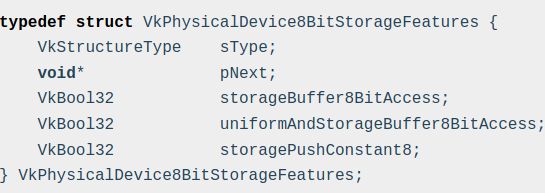
This means after enabling the extension, an application will still need to query and enable the features needed from an extension.
19.5. Promotion Process
When minor versions of Vulkan are released, some extensions are promoted as defined in the spec. The goal of promotion is to have extended functionality, that the Vulkan Working Group has decided is widely supported, to be in the core Vulkan spec. More details about Vulkan versions can be found in the version chapter.
An example would be something such as VK_KHR_get_physical_device_properties2 which is used for most other extensions. In Vulkan 1.0, an application has to query for support of VK_KHR_get_physical_device_properties2 before being able to call a function such as vkGetPhysicalDeviceFeatures2KHR. Starting in Vulkan 1.1, the vkGetPhysicalDeviceFeatures2 function is guaranteed to be supported.
Another way to look at promotion is with the VK_KHR_8bit_storage as an example again. Since Vulkan 1.0 some features, such as textureCompressionASTC_LDR, are not required to be supported, but are available to query without needing to enable any extensions. Starting in Vulkan 1.2 when VK_KHR_8bit_storage was promoted to core, all the features in VkPhysicalDevice8BitStorageFeatures can now be found in VkPhysicalDeviceVulkan12Features.
19.5.1. Promotion Change of Behavior
It is important to realize there is a subtle difference for some extension that are promoted. The spec describes how promotion can involve minor changes such as in the extension’s “Feature advertisement/enablement”. To best describe the subtlety of this, VK_KHR_8bit_storage can be used as a use case.
The Vulkan spec describes the change for VK_KHR_8bit_storage for Vulkan 1.2 where it states:
If the VK_KHR_8bit_storage extension is not supported, support for the SPIR-V StorageBuffer8BitAccess capability in shader modules is optional.
"not supported" here refers to the fact that an implementation might support Vulkan 1.2+, but if an application queries vkEnumerateDeviceExtensionProperties it is possible that VK_KHR_8bit_storage will not be in the result.
-
If
VK_KHR_8bit_storageis found invkEnumerateDeviceExtensionPropertiesthen thestorageBuffer8BitAccessfeature is guaranteed to be supported. -
If
VK_KHR_8bit_storageis not found invkEnumerateDeviceExtensionPropertiesthen thestorageBuffer8BitAccessfeature might be supported and can be checked by queryingVkPhysicalDeviceVulkan12Features::storageBuffer8BitAccess.
The list of all feature changes to promoted extensions can be found in the version appendix of the spec.
permalink: /Notes/004-3d-rendering/vulkan/chapters/enabling_features.html ---
20. Enabling Features
This section goes over the logistics for enabling features.
20.1. Category of Features
All features in Vulkan can be categorized/found in 3 sections
-
Core 1.0 Features
-
These are the set of features that were available from the initial 1.0 release of Vulkan. The list of features can be found in VkPhysicalDeviceFeatures
-
-
Future Core Version Features
-
With Vulkan 1.1+ some new features were added to the core version of Vulkan. To keep the size of
VkPhysicalDeviceFeaturesbackward compatible, new structs were created to hold the grouping of features.
-
-
Extension Features
20.2. How to Enable the Features
All features must be enabled at VkDevice creation time inside the VkDeviceCreateInfo struct.
| Note | Don’t forget to query first with |
For the Core 1.0 Features, this is as simple as setting VkDeviceCreateInfo::pEnabledFeatures with the features desired to be turned on.
VkPhysicalDeviceFeatures features = {};
vkGetPhysicalDeviceFeatures(physical_device, &features);
// Logic if feature is not supported
if (features.robustBufferAccess == VK_FALSE) {
}
VkDeviceCreateInfo info = {};
info.pEnabledFeatures = &features;For all features, including the Core 1.0 Features, use VkPhysicalDeviceFeatures2 to pass into VkDeviceCreateInfo.pNext
VkPhysicalDeviceShaderDrawParametersFeatures ext_feature = {};
VkPhysicalDeviceFeatures2 physical_features2 = {};
physical_features2.pNext = &ext_feature;
vkGetPhysicalDeviceFeatures2(physical_device, &physical_features2);
// Logic if feature is not supported
if (ext_feature.shaderDrawParameters == VK_FALSE) {
}
VkDeviceCreateInfo info = {};
info.pNext = &physical_features2;The same works for the “Future Core Version Features” too.
VkPhysicalDeviceVulkan11Features features11 = {};
VkPhysicalDeviceFeatures2 physical_features2 = {};
physical_features2.pNext = &features11;
vkGetPhysicalDeviceFeatures2(physical_device, &physical_features2);
// Logic if feature is not supported
if (features11.shaderDrawParameters == VK_FALSE) {
}
VkDeviceCreateInfo info = {};
info.pNext = &physical_features2;permalink:/Notes/004-3d-rendering/vulkan/chapters/spirv_extensions.html layout: default ---
21. Using SPIR-V Extensions
SPIR-V is the shader representation used at vkCreateShaderModule time. Just like Vulkan, SPIR-V also has extensions and a capabilities system.
It is important to remember that SPIR-V is an intermediate language and not an API, it relies on an API, such as Vulkan, to expose what features are available to the application at runtime. This chapter aims to explain how Vulkan, as a SPIR-V client API, interacts with the SPIR-V extensions and capabilities.
21.1. SPIR-V Extension Example
For this example, the VK_KHR_8bit_storage and SPV_KHR_8bit_storage will be used to expose the UniformAndStorageBuffer8BitAccess capability. The following is what the SPIR-V disassembled looks like:
OpCapability Shader
OpCapability UniformAndStorageBuffer8BitAccess
OpExtension "SPV_KHR_8bit_storage"21.1.1. Steps for using SPIR-V features:
-
Make sure the SPIR-V extension and capability are available in Vulkan.
-
Check if the required Vulkan extension, features or version are supported.
-
If needed, enable the Vulkan extension and features.
-
If needed, see if there is a matching extension for the high-level shading language (ex. GLSL or HLSL) being used.
Breaking down each step in more detail:
Check if SPIR-V feature is supported
Depending on the shader feature there might only be a OpExtension or OpCapability that is needed. For this example, the UniformAndStorageBuffer8BitAccess is part of the SPV_KHR_8bit_storage extension.
To check if the SPIR-V extension is supported take a look at the Supported SPIR-V Extension Table in the Vulkan Spec.
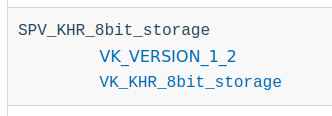
Also, take a look at the Supported SPIR-V Capabilities Table in the Vulkan Spec.

| Note | while it says |
Luckily if you forget to check, the Vulkan Validation Layers has an auto-generated validation in place. Both the Validation Layers and the Vulkan Spec table are all based on the ./xml/vk.xml file.
<spirvcapability name="UniformAndStorageBuffer8BitAccess">
<enable struct="VkPhysicalDeviceVulkan12Features" feature="uniformAndStorageBuffer8BitAccess" requires="VK_VERSION_1_2,VK_KHR_8bit_storage"/>
</spirvcapability>
<spirvextension name="SPV_KHR_8bit_storage">
<enable version="VK_VERSION_1_2"/>
<enable extension="VK_KHR_8bit_storage"/>
</spirvextension>Check for support then enable if needed
In this example, either VK_KHR_8bit_storage or a Vulkan 1.2 device is required.
If using a Vulkan 1.0 or 1.1 device, the VK_KHR_8bit_storage extension will need to be supported and enabled at device creation time.
Regardless of using the Vulkan extension or version, if required, an app still must make sure any matching Vulkan feature needed is supported and enabled at device creation time. Some SPIR-V extensions and capabilities don’t require a Vulkan feature, but this is all listed in the tables in the spec.
For this example, either the VkPhysicalDeviceVulkan12Features::uniformAndStorageBuffer8BitAccess or VkPhysicalDevice8BitStorageFeatures::uniformAndStorageBuffer8BitAccess feature must be supported and enabled.
Using high level shading language extensions
For this example, GLSL has a GL_EXT_shader_16bit_storage extension that includes the match GL_EXT_shader_8bit_storage extension in it.
Tools such as glslang and SPIRV-Tools will handle to make sure the matching OpExtension and OpCapability are used.
permalink: /Notes/004-3d-rendering/vulkan/chapters/formats.html ---
22. Formats
Vulkan formats are used to describe how memory is laid out. This chapter aims to give a high-level overview of the variations of formats in Vulkan and some logistical information for how to use them. All details are already well specified in both the Vulkan Spec format chapter and the Khronos Data Format Specification.
The most common use case for a VkFormat is when creating a VkImage. Because the VkFormats are well defined, they are also used when describing the memory layout for things such as a VkBufferView, vertex input attribute, mapping SPIR-V image formats, creating triangle geometry in a bottom-level acceleration structure, etc.
22.1. Feature Support
It is important to understand that "format support" is not a single binary value per format, but rather each format has a set of VkFormatFeatureFlagBits that each describes with features are supported for a format.
The supported formats may vary across implementations, but a minimum set of format features are guaranteed. An application can query for the supported format properties.
| Note | Both VK_KHR_get_physical_device_properties2 and VK_KHR_format_feature_flags2 expose another way to query for format features. |
22.1.1. Format Feature Query Example
In this example, the code will check if the VK_FORMAT_R8_UNORM format supports being sampled from a VkImage created with VK_IMAGE_TILING_LINEAR for VkImageCreateInfo::tiling. To do this, the code will query the linearTilingFeatures flags for VK_FORMAT_R8_UNORM to see if the VK_FORMAT_FEATURE_SAMPLED_IMAGE_BIT is supported by the implementation.
// Using core Vulkan 1.0
VkFormatProperties formatProperties;
vkGetPhysicalDeviceFormatProperties(physicalDevice, VK_FORMAT_R8_UNORM, &formatProperties);
if ((formatProperties.linearTilingFeatures & VK_FORMAT_FEATURE_SAMPLED_IMAGE_BIT) != 0) {
// supported
} else {
// not supported
}// Using core Vulkan 1.1 or VK_KHR_get_physical_device_properties2
VkFormatProperties2 formatProperties2;
formatProperties2.sType = VK_STRUCTURE_TYPE_FORMAT_PROPERTIES_2;
formatProperties2.pNext = nullptr; // used for possible extensions
vkGetPhysicalDeviceFormatProperties2(physicalDevice, VK_FORMAT_R8_UNORM, &formatProperties2);
if ((formatProperties2.formatProperties.linearTilingFeatures & VK_FORMAT_FEATURE_SAMPLED_IMAGE_BIT) != 0) {
// supported
} else {
// not supported
}// Using VK_KHR_format_feature_flags2
VkFormatProperties3KHR formatProperties3;
formatProperties2.sType = VK_STRUCTURE_TYPE_FORMAT_PROPERTIES_3_KHR;
formatProperties2.pNext = nullptr;
VkFormatProperties2 formatProperties2;
formatProperties2.sType = VK_STRUCTURE_TYPE_FORMAT_PROPERTIES_2;
formatProperties2.pNext = &formatProperties3;
vkGetPhysicalDeviceFormatProperties2(physicalDevice, VK_FORMAT_R8_UNORM, &formatProperties2);
if ((formatProperties3.linearTilingFeatures & VK_FORMAT_FEATURE_2_STORAGE_IMAGE_BIT_KHR) != 0) {
// supported
} else {
// not supported
}22.2. Variations of Formats
Formats come in many variations, most can be grouped by the name of the format. When dealing with images, the VkImageAspectFlagBits values are used to represent which part of the data is being accessed for operations such as clears and copies.
22.2.1. Color
Format with a R, G, B or A component and accessed with the VK_IMAGE_ASPECT_COLOR_BIT
22.2.2. Depth and Stencil
Formats with a D or S component. These formats are considered opaque and have special rules when it comes to copy to and from depth/stencil images.
Some formats have both a depth and stencil component and can be accessed separately with VK_IMAGE_ASPECT_DEPTH_BIT and VK_IMAGE_ASPECT_STENCIL_BIT.
| Note | VK_KHR_separate_depth_stencil_layouts and VK_EXT_separate_stencil_usage, which are both promoted to Vulkan 1.2, can be used to have finer control between the depth and stencil components. |
More information about depth format can also be found in the depth chapter.
22.2.3. Compressed
Compressed image formats representation of multiple pixels encoded interdependently within a region.
| Format | How to enable |
|---|---|
| |
| |
| |
22.2.4. Planar
VK_KHR_sampler_ycbcr_conversion and VK_EXT_ycbcr_2plane_444_formats add multi-planar formats to Vulkan. The planes can be accessed separately with VK_IMAGE_ASPECT_PLANE_0_BIT, VK_IMAGE_ASPECT_PLANE_1_BIT, and VK_IMAGE_ASPECT_PLANE_2_BIT.
22.2.5. Packed
Packed formats are for the purposes of address alignment. As an example, VK_FORMAT_A8B8G8R8_UNORM_PACK32 and VK_FORMAT_R8G8B8A8_UNORM might seem very similar, but when using the formula from the Vertex Input Extraction section of the spec
attribAddress = bufferBindingAddress + vertexOffset + attribDesc.offset;
For VK_FORMAT_R8G8B8A8_UNORM the attribAddress has to be a multiple of the component size (8 bits) while VK_FORMAT_A8B8G8R8_UNORM_PACK32 has to be a multiple of the packed size (32 bits).
22.2.6. External
Currently only supported with the VK_ANDROID_external_memory_android_hardware_buffer extension. This extension allows Android applications to import implementation-defined external formats to be used with a VkSamplerYcbcrConversion. There are many restrictions what are allowed with these external formats which are documented in the spec.
permalink:/Notes/004-3d-rendering/vulkan/chapters/queues.html layout: default ---
23. Queues
An application submits work to a VkQueue, normally in the form of VkCommandBuffer objects or sparse bindings.
Command buffers submitted to a VkQueue start in order, but are allowed to proceed independently after that and complete out of order.
Command buffers submitted to different queues are unordered relative to each other unless you explicitly synchronize them with a VkSemaphore.
You can only submit work to a VkQueue from one thread at a time, but different threads can submit work to a different VkQueue simultaneously.
How a VkQueue is mapped to the underlying hardware is implementation-defined. Some implementations will have multiple hardware queues and submitting work to multiple VkQueues will proceed independently and concurrently. Some implementations will do scheduling at a kernel driver level before submitting work to the hardware. There is no current way in Vulkan to expose the exact details how each VkQueue is mapped.
| Note | Not all applications will require or benefit from multiple queues. It is reasonable for an application to have a single “universal” graphics supported queue to submit all the work to the GPU. |
23.1. Queue Family
There are various types of operations a VkQueue can support. A “Queue Family” just describes a set of VkQueues that have common properties and support the same functionality, as advertised in VkQueueFamilyProperties.
The following are the queue operations found in VkQueueFlagBits:
-
VK_QUEUE_GRAPHICS_BITused forvkCmdDraw*and graphic pipeline commands. -
VK_QUEUE_COMPUTE_BITused forvkCmdDispatch*andvkCmdTraceRays*and compute pipeline related commands. -
VK_QUEUE_TRANSFER_BITused for all transfer commands.-
VK_PIPELINE_STAGE_TRANSFER_BIT in the Spec describes “transfer commands”.
-
Queue Families with only
VK_QUEUE_TRANSFER_BITare usually for using DMA to asynchronously transfer data between host and device memory on discrete GPUs, so transfers can be done concurrently with independent graphics/compute operations. -
VK_QUEUE_GRAPHICS_BITandVK_QUEUE_COMPUTE_BITcan always implicitly acceptVK_QUEUE_TRANSFER_BITcommands.
-
-
VK_QUEUE_SPARSE_BINDING_BITused for binding sparse resources to memory withvkQueueBindSparse. -
VK_QUEUE_PROTECTED_BITused for protected memory. -
VK_QUEUE_VIDEO_DECODE_BIT_KHRandVK_QUEUE_VIDEO_ENCODE_BIT_KHRused with Vulkan Video.
23.1.1. Knowing which Queue Family is needed
Each operation in the Vulkan Spec has a “Supported Queue Types” section generated from the vk.xml file. The following is 3 different examples of what it looks like in the Spec:
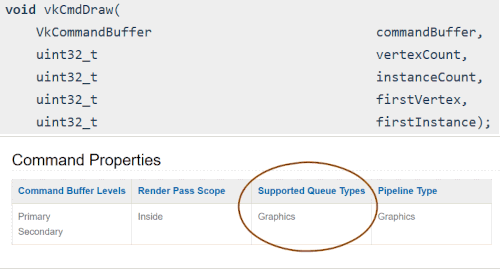
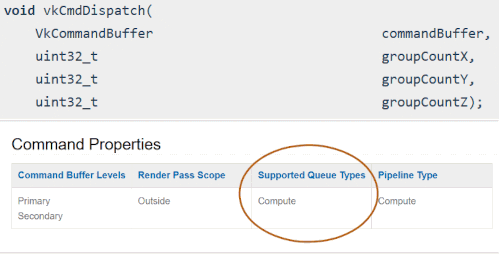
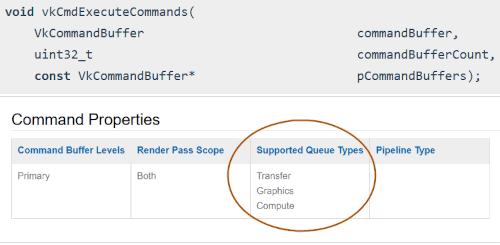
23.1.2. Querying for Queue Family
The following is the simplest logic needed if an application only wants a single graphics VkQueue
uint32_t count = 0;
vkGetPhysicalDeviceQueueFamilyProperties(physicalDevice, &count, nullptr);
std::vector<VkQueueFamilyProperties> properties(count);
vkGetPhysicalDeviceQueueFamilyProperties(physicalDevice, &count, properties.data());
// Vulkan requires an implementation to expose at least 1 queue family with graphics
uint32_t graphicsQueueFamilyIndex;
for (uint32_t i = 0; i < count; i++) {
if ((properties[i].queueFlags & VK_QUEUE_GRAPHICS_BIT) != 0) {
// This Queue Family support graphics
graphicsQueueFamilyIndex = i;
break;
}
}23.2. Creating and getting a Queue
Unlike other handles such as VkDevice, VkBuffer, VkDeviceMemory, there is no vkCreateQueue or vkAllocateQueue. Instead, the driver is in charge of creating and destroying the VkQueue handles during vkCreateDevice/vkDestroyDevice time.
The following examples will use the hypothetical implementation which support 3 VkQueues from 2 Queue Families:
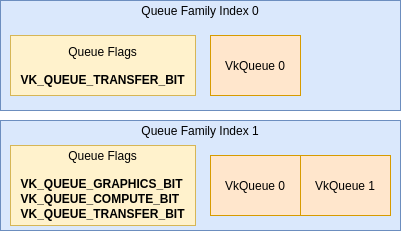
The following is an example how to create all 3 VkQueues with the logical device:
VkDeviceQueueCreateInfo queueCreateInfo[2];
queueCreateInfo[0].queueFamilyIndex = 0; // Transfer
queueCreateInfo[0].queueCount = 1;
queueCreateInfo[1].queueFamilyIndex = 1; // Graphics
queueCreateInfo[1].queueCount = 2;
VkDeviceCreateInfo deviceCreateInfo = {};
deviceCreateInfo.pQueueCreateInfos = queueCreateInfo;
deviceCreateInfo.queueCreateInfoCount = 2;
vkCreateDevice(physicalDevice, &deviceCreateInfo, nullptr, &device);After creating the VkDevice the application can use vkGetDeviceQueue to get the VkQueue handles
VkQueue graphicsQueue0 = VK_NULL_HANDLE;
VkQueue graphicsQueue1 = VK_NULL_HANDLE;
VkQueue transferQueue0 = VK_NULL_HANDLE;
// Can be obtained in any order
vkGetDeviceQueue(device, 0, 0, &transferQueue0); // family 0 - queue 0
vkGetDeviceQueue(device, 1, 1, &graphicsQueue1); // family 1 - queue 1
vkGetDeviceQueue(device, 1, 0, &graphicsQueue0); // family 1 - queue 0permalink: /Notes/004-3d-rendering/vulkan/chapters/wsi.html ---
24. Window System Integration (WSI)
Since the Vulkan API can be used without displaying results, WSI is provided through the use of optional Vulkan extensions. Most implementations will include WSI support. The WSI design was created to abstract each platform’s windowing mechanism from the core Vulkan API.
24.1. Surface
The VkSurfaceKHR object is platform agnostic and designed so the rest of the Vulkan API can use it for all WSI operations. It is enabled using the VK_KHR_surface extension.
Each platform that supports a Vulkan Surface has its own way to create a VkSurfaceKHR object from its respective platform-specific API.
-
Android - vkCreateAndroidSurfaceKHR
-
DirectFB - vkCreateDirectFBSurfaceEXT
-
Fuchsia - vkCreateImagePipeSurfaceFUCHSIA
-
Google Games - vkCreateStreamDescriptorSurfaceGGP
-
iOS - vkCreateIOSSurfaceMVK
-
macOS - vkCreateMacOSSurfaceMVK
-
Metal - vkCreateMetalSurfaceEXT
-
VI - vkCreateViSurfaceNN
-
Wayland - vkWaylandSurfaceCreateInfoKHR
-
QNX - vkCreateScreenSurfaceQNX
-
Windows - vkCreateWin32SurfaceKHR
-
XCB - vkCreateXcbSurfaceKHR
-
Xlib - vkCreateXlibSurfaceKHR
-
Direct-to-Display - vkCreateDisplayPlaneSurfaceKHR
Once a VkSurfaceKHR is created there are various capabilities, formats, and presentation modes to query for.
24.2. Swapchain
The VkSwapchainKHR object provides the ability to present rendering results to a surface through an array of VkImage objects. The swapchain’s various present modes determine how the presentation engine is implemented.
Khronos' sample and tutorial explain different considerations to make when creating a swapchain and selecting a presentation mode.
24.3. Pre-Rotation
Mobile devices can be rotated, therefore the logical orientation of the application window and the physical orientation of the display may not match. Applications need to be able to operate in two modes: portrait and landscape. The difference between these two modes can be simplified to just a change in resolution. However, some display subsystems always work on the “native” (or “physical”) orientation of the display panel. Since the device has been rotated, to achieve the desired effect the application output must also rotate.
In order for your application to get the most out of Vulkan on mobile platforms, such as Android, implementing pre-rotation is a must. There is a detailed blog post from Google that goes over how to handle the surface rotation by specifying the orientation during swapchain creation and also comes with a standalone example. The Vulkan-Samples also has both a great write up of why pre-rotation is a problem as well as a sample to run that shows a way to solve it in the shader. If using an Adreno GPU powered device, Qualcomm suggests making use of the VK_QCOM_render_pass_transform extension to implement pre-rotation.
permalink:/Notes/004-3d-rendering/vulkan/chapters/pnext_and_stype.html layout: default ---
25. pNext and sType
People new to Vulkan will start to notice the pNext and sType variables all around the Vulkan Spec. The void* pNext is used to allow for expanding the Vulkan Spec by creating a Linked List between structures. The VkStructureType sType is used by the loader, layers, and implementations to know what type of struct was passed in by pNext. pNext is mostly used when dealing with extensions that expose new structures.
25.1. Two Base Structures
The Vulkan API provides two base structures, VkBaseInStructure and VkBaseOutStructure, to be used as a convenient way to iterate through a structure pointer chain.
The In of VkBaseInStructure refers to the fact pNext is a const * and are read-only to loader, layers, and driver receiving them. The Out of VkBaseOutStructure refers the pNext being used to return data back to the application.
25.2. Setting pNext Structure Example
// An example with two simple structures, "a" and "b"
typedef struct VkA {
VkStructureType sType;
void* pNext;
uint32_t value;
} VkA;
typedef struct VkB {
VkStructureType sType;
void* pNext;
uint32_t value;
} VkB;
// A Vulkan Function that takes struct "a" as an argument
// This function is in charge of populating the values
void vkGetValue(VkA* pA);
// Define "a" and "b" and set their sType
struct VkB b = {};
b.sType = VK_STRUCTURE_TYPE_B;
struct VkA a = {};
a.sType = VK_STRUCTURE_TYPE_A;
// Set the pNext pointer from "a" to "b"
a.pNext = (void*)&b;
// Pass "a" to the function
vkGetValue(&a);
// Use the values which were both set from vkGetValue()
printf("VkA value = %u \n", a.value);
printf("VkB value = %u \n", b.value);25.3. Reading pNext Values Example
Underneath, the loader, layers, and driver are now able to find the chained pNext structures. Here is an example to help illustrate how one could implement pNext from the loader, layer, or driver point of view.
void vkGetValue(VkA* pA) {
VkBaseOutStructure* next = reinterpret_cast<VkBaseOutStructure*>(pA->pNext);
while (next != nullptr) {
switch (next->sType) {
case VK_STRUCTURE_TYPE_B:
VkB* pB = reinterpret_cast<VkB*>(next);
// This is where the "b.value" above got set
pB->value = 42;
break;
case VK_STRUCTURE_TYPE_C:
// Can chain as many structures as supported
VkC* pC = reinterpret_cast<VkC*>(next);
SomeFunction(pC);
break;
default:
LOG("Unsupported sType %d", next->sType);
}
// This works because the first two values of all chainable Vulkan structs
// are "sType" and "pNext" making the offsets the same for pNext
next = reinterpret_cast<VkBaseOutStructure*>(next->pNext);
}
// ...
}permalink:/Notes/004-3d-rendering/vulkan/chapters/synchronization.html layout: default ---
26. Synchronization
Synchronization is one of the most powerful but also most complex parts of using Vulkan. The application developer is now responsible for managing synchronization using the various Vulkan synchronization primitives. Improper use of synchronization can lead to hard-to-find bugs as well as poor performance in cases where the the GPU is unnecessarily idle.
There are a set of examples and a Understanding Vulkan Synchronization blog provided by Khronos on how to use some of the synchronization primitives. There are also presentations from Tobias Hector from past Vulkan talks: part 1 slides (video) and part 2 slides (video).
The following is an overview diagram of the difference between VkEvent, VkFence, and VkSemaphore
26.1. Validation
The Khronos Validation Layer has implemented some validation for synchronization. It can easily be enabled by the Vulkan Configurator included with the Vulkan SDK. A detailed whitepaper discussing the synchronization validation has been written as well and released as a Khronos Blog.
26.2. Pipeline Barriers
Pipeline Barriers give control over which pipeline stages need to wait on previous pipeline stages when a command buffer is executed.
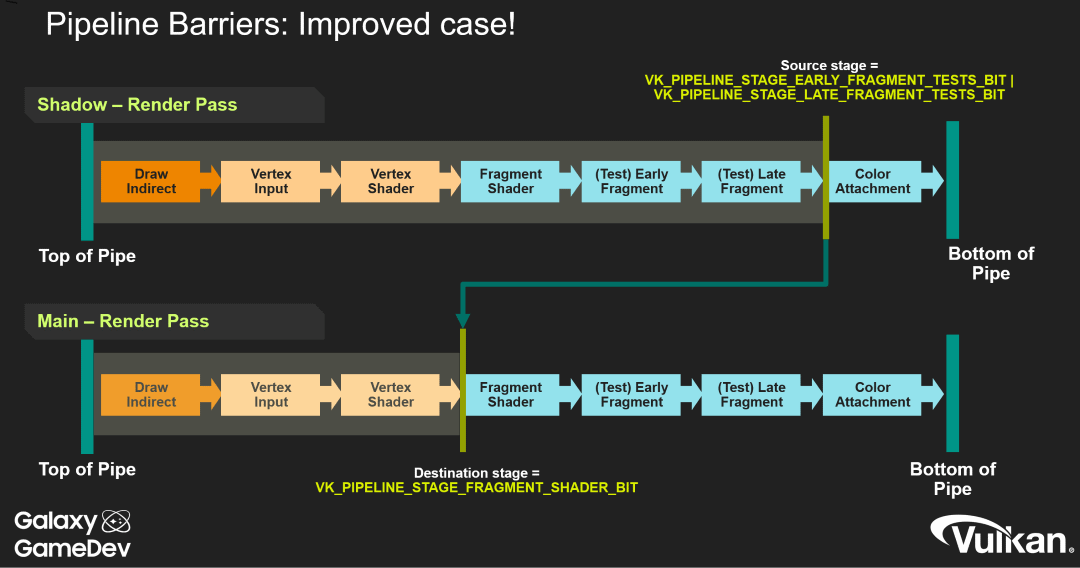
While Pipeline Barriers might be hard to understand at first, there are many great Khronos talks and other resources that go more in depth on the topic.
-
Vulkanised 2018 - Low-level mysteries of pipeline barriers (video)
-
Vulkanised 2019 - Live Long and Optimise (video) Pipeline Analysis starting slide 12
-
Vulkan barriers explained blog post
26.3. VK_KHR_synchronization2
The VK_KHR_synchronization2 extension overhauls the original core synchronization APIs to reduce complexity for application developers, as well as adding a few additional features not present in the original APIs.
Read the VK_KHR_synchronization2 chapter for more info about the difference in the synchronization APIs and how to port over to using the new extension
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_synchronization2.html layout: default ---
27. VK_KHR_synchronization2
| Note | Promoted to core in Vulkan 1.3 |
The VK_KHR_synchronization2 extension provides improvements to pipeline barriers, events, image layout transitions and queue submission. This document shows the difference between the original Vulkan synchronization operations and those provided by the extension. There are also examples of how to update application code to make use of the extension.
27.1. Rethinking Pipeline Stages and Access Flags
One main change with the extension is to have pipeline stages and access flags now specified together in memory barrier structures. This makes the connection between the two more obvious.
The only new type of structure needed is VkDependencyInfoKHR, which wraps all the barriers into a single location.

27.1.1. Adding barriers for setting events
Note that with the introduction of VkDependencyInfoKHR that vkCmdSetEvent2KHR, unlike vkCmdSetEvent, has the ability to add barriers. This was added to allow the VkEvent to be more useful. Because the implementation of a synchronization2 VkEvent is likely to be substantially different from a Vulkan 1.2 VkEvent, you must not mix extension and core api calls for a single VkEvent. For example, you must not call vkCmdSetEvent2KHR() and then vkCmdWaitEvents().
27.2. Reusing the same pipeline stage and access flag names
Due to running out of the 32 bits for VkAccessFlag the VkAccessFlags2KHR type was created with a 64-bit range. To prevent the same issue for VkPipelineStageFlags, the VkPipelineStageFlags2KHR type was also created with a 64-bit range.
64-bit enumeration types are not available in all C/C++ compilers, so the code for the new fields uses static const values instead of an enum. As a result of this, there are no equivalent types to VkPipelineStageFlagBits and VkAccessFlagBits. Some code, including Vulkan functions such as vkCmdWriteTimestamp(), used the Bits type to indicate that the caller could only pass in a single bit value, rather than a mask of multiple bits. These calls need to be converted to take the Flags type and enforce the “only 1-bit” limitation via Valid Usage or the appropriate coding convention for your own code, as was done for vkCmdWriteTimestamp2KHR().
The new flags include identical bits to the original synchronization flags, with the same base name and identical values. Old flags can be used directly in the new APIs, subject to any typecasting constraints of the coding environment. The following 2 examples show the naming differences:
-
VK_PIPELINE_STAGE_COMPUTE_SHADER_BITtoVK_PIPELINE_STAGE_2_COMPUTE_SHADER_BIT_KHR -
VK_ACCESS_SHADER_READ_BITtoVK_ACCESS_2_SHADER_READ_BIT_KHR
27.3. VkSubpassDependency
Updating the use of the pipeline stages and access flags in VkSubpassDependency requires simply using VkSubpassDependency2 which can have a VkMemoryBarrier2KHR passed in the pNext
Example would be taking
// Without VK_KHR_synchronization2
VkSubpassDependency dependency = {
.srcSubpass = 0,
.dstSubpass = 1,
.srcStageMask = VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT |
VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT,
.dstStageMask = VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT,
.srcAccessMask = VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT,
.dstAccessMask = VK_ACCESS_INPUT_ATTACHMENT_READ_BIT,
.dependencyFlags = VK_DEPENDENCY_BY_REGION_BIT
};and turning it into
// With VK_KHR_synchronization2
VkMemoryBarrier2KHR memoryBarrier = {
.sType = VK_STRUCTURE_TYPE_MEMORY_BARRIER_2_KHR,
.pNext = nullptr,
.srcStageMask = VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT_KHR |
VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT_KHR,
.dstStageMask = VK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BIT_KHR,
.srcAccessMask = VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT_KHR,
.dstAccessMask = VK_ACCESS_2_INPUT_ATTACHMENT_READ_BIT_KHR
}
// The 4 fields unset are ignored according to the spec
// When VkMemoryBarrier2KHR is passed into pNext
VkSubpassDependency2 dependency = {
.sType = VK_STRUCTURE_TYPE_SUBPASS_DEPENDENCY_2,
.pNext = &memoryBarrier,
.srcSubpass = 0,
.dstSubpass = 1,
.dependencyFlags = VK_DEPENDENCY_BY_REGION_BIT
};27.4. Splitting up pipeline stages and access masks
Some VkAccessFlags and VkPipelineStageFlags had values that were ambiguous to what it was targeting in hardware. The new VkAccessFlags2KHR and VkPipelineStageFlags2KHR break these up for some cases while leaving the old value for maintability.
27.4.1. Splitting up VK_PIPELINE_STAGE_VERTEX_INPUT_BIT
The VK_PIPELINE_STAGE_VERTEX_INPUT_BIT (now VK_PIPELINE_STAGE_2_VERTEX_INPUT_BIT_KHR) was split into 2 new stage flags which specify a dedicated stage for both the index input and the vertex input instead of having them combined into a single pipeline stage flag.
-
VK_PIPELINE_STAGE_2_INDEX_INPUT_BIT_KHR -
VK_PIPELINE_STAGE_2_VERTEX_ATTRIBUTE_INPUT_BIT_KHR
27.4.2. Splitting up VK_PIPELINE_STAGE_ALL_TRANSFER_BIT
The VK_PIPELINE_STAGE_ALL_TRANSFER_BIT (now VK_PIPELINE_STAGE_2_ALL_TRANSFER_BIT_KHR) was split into 4 new stage flags which specify a dedicated stage for the various staging commands instead of having them combined into a single pipeline stage flag.
-
VK_PIPELINE_STAGE_2_COPY_BIT_KHR -
VK_PIPELINE_STAGE_2_RESOLVE_BIT_KHR -
VK_PIPELINE_STAGE_2_BLIT_BIT_KHR -
VK_PIPELINE_STAGE_2_CLEAR_BIT_KHR
27.4.3. Splitting up VK_ACCESS_SHADER_READ_BIT
The VK_ACCESS_SHADER_READ_BIT (now VK_ACCESS_2_SHADER_READ_BIT_KHR) was split into 3 new access flags which specify a dedicated access for the various case instead of having them combined into a single access flag.
-
VK_ACCESS_2_UNIFORM_READ_BIT_KHR -
VK_ACCESS_2_SHADER_SAMPLED_READ_BIT_KHR -
VK_ACCESS_2_SHADER_STORAGE_READ_BIT_KHR
27.4.4. Combining shader stages for pre-rasterization
Besides splitting up flags, the VK_PIPELINE_STAGE_2_PRE_RASTERIZATION_SHADERS_BIT_KHR was added to combine shader stages that occurs before rasterization in a single, convenient flag.
27.5. VK_ACCESS_SHADER_WRITE_BIT alias
The VK_ACCESS_SHADER_WRITE_BIT (now VK_ACCESS_2_SHADER_WRITE_BIT_KHR) was given an alias of VK_ACCESS_2_SHADER_STORAGE_WRITE_BIT_KHR to better describe the scope of what resources in the shader are described by the access flag.
27.6. TOP_OF_PIPE and BOTTOM_OF_PIPE deprecation
The use of VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT and VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT are now deprecated and updating is simple as following the following 4 case with the new equivalents.
-
VK_PIPELINE_STAGE_TOP_OF_PIPE_BITin first synchronization scope// From .srcStageMask = VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT; // To .srcStageMask = VK_PIPELINE_STAGE_2_NONE_KHR; .srcAccessMask = VK_ACCESS_2_NONE_KHR; -
VK_PIPELINE_STAGE_TOP_OF_PIPE_BITin second synchronization scope// From .dstStageMask = VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT; // To .dstStageMask = VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT_KHR; .dstAccessMask = VK_ACCESS_2_NONE_KHR; -
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BITin first synchronization scope// From .srcStageMask = VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT; // To .srcStageMask = VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT_KHR; .srcAccessMask = VK_ACCESS_2_NONE_KHR; -
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BITin second synchronization scope// From .dstStageMask = VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT; // To .dstStageMask = VK_PIPELINE_STAGE_2_NONE_KHR; .dstAccessMask = VK_ACCESS_2_NONE_KHR;
27.7. Making use of new image layouts
VK_KHR_synchronization2 adds 2 new image layouts VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL_KHR and VK_IMAGE_LAYOUT_READ_ONLY_OPTIMAL_KHR to help with making layout transition easier.
The following uses the example of doing a draw thats writes to both a color attachment and depth/stencil attachment which then are both sampled in the next draw. Prior a developer needed to make sure they matched up the layouts and access mask correctly such as the following:
VkImageMemoryBarrier colorImageMemoryBarrier = {
.srcAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT,
.dstAccessMask = VK_ACCESS_SHADER_READ_BIT,
.oldLayout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL,
.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL
};
VkImageMemoryBarrier depthStencilImageMemoryBarrier = {
.srcAccessMask = VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT,,
.dstAccessMask = VK_ACCESS_SHADER_READ_BIT,
.oldLayout = VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL,
.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL
};but with VK_KHR_synchronization2 this is made simple
VkImageMemoryBarrier colorImageMemoryBarrier = {
.srcAccessMask = VK_ACCESS_2_COLOR_ATTACHMENT_WRITE_BIT_KHR,
.dstAccessMask = VK_ACCESS_2_SHADER_READ_BIT_KHR,
.oldLayout = VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL_KHR, // new layout from VK_KHR_synchronization2
.newLayout = VK_IMAGE_LAYOUT_READ_ONLY_OPTIMAL_KHR // new layout from VK_KHR_synchronization2
};
VkImageMemoryBarrier depthStencilImageMemoryBarrier = {
.srcAccessMask = VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT_KHR,,
.dstAccessMask = VK_ACCESS_2_SHADER_READ_BIT_KHR,
.oldLayout = VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL_KHR, // new layout from VK_KHR_synchronization2
.newLayout = VK_IMAGE_LAYOUT_READ_ONLY_OPTIMAL_KHR // new layout from VK_KHR_synchronization2
};In the new case VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL_KHR works by contextually appling itself based on the image format used. So as long as colorImageMemoryBarrier is used on a color format, VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL_KHR maps to VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL
Additionally, with VK_KHR_synchronization2, if oldLayout is equal to newLayout, no layout transition is performed and the image contents are preserved. The layout used does not even need to match the layout of an image, so the following barrier is valid:
VkImageMemoryBarrier depthStencilImageMemoryBarrier = {
// other fields omitted
.oldLayout = VK_IMAGE_LAYOUT_UNDEFINED,
.newLayout = VK_IMAGE_LAYOUT_UNDEFINED,
};27.8. New submission flow
VK_KHR_synchronization2 adds the vkQueueSubmit2KHR command which main goal is to clean up the syntax for the function to wrap command buffers and semaphores in extensible structures, which incorporate changes from Vulkan 1.1, VK_KHR_device_group, and VK_KHR_timeline_semaphore.
Taking the following example of a normal queue submission call
VkSemaphore waitSemaphore;
VkSemaphore signalSemaphore;
VkCommandBuffer commandBuffers[8];
// Possible pNext from VK_KHR_timeline_semaphore
VkTimelineSemaphoreSubmitInfo timelineSemaphoreSubmitInfo = {
// ...
.pNext = nullptr
};
// Possible pNext from VK_KHR_device_group
VkDeviceGroupSubmitInfo deviceGroupSubmitInfo = {
// ...
.pNext = &timelineSemaphoreSubmitInfo
};
// Possible pNext from Vulkan 1.1
VkProtectedSubmitInfo = protectedSubmitInfo {
// ...
.pNext = &deviceGroupSubmitInfo
};
VkSubmitInfo submitInfo = {
.pNext = &protectedSubmitInfo, // Chains all 3 extensible structures
.waitSemaphoreCount = 1,
.pWaitSemaphores = &waitSemaphore,
.pWaitDstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT
.commandBufferCount = 8,
.pCommandBuffers = commandBuffers,
.signalSemaphoreCount = 1,
.pSignalSemaphores = signalSemaphore
};
vkQueueSubmit(queue, 1, submitInfo, fence);this can now be transformed to vkQueueSubmit2KHR as
// Uses same semaphore and command buffer handles
VkSemaphore waitSemaphore;
VkSemaphore signalSemaphore;
VkCommandBuffer commandBuffers[8];
VkSemaphoreSubmitInfoKHR waitSemaphoreSubmitInfo = {
.semaphore = waitSemaphore,
.value = 1, // replaces VkTimelineSemaphoreSubmitInfo
.stageMask = VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT_KHR,
.deviceIndex = 0, // replaces VkDeviceGroupSubmitInfo
};
// Note this is allowing a stage to set the signal operation
VkSemaphoreSubmitInfoKHR signalSemaphoreSubmitInfo = {
.semaphore = waitSemaphore,
.value = 2, // replaces VkTimelineSemaphoreSubmitInfo
.stageMask = VK_PIPELINE_STAGE_2_VERTEX_SHADER_BIT_KHR, // when to signal semaphore
.deviceIndex = 0, // replaces VkDeviceGroupSubmitInfo
};
// Need one for each VkCommandBuffer
VkCommandBufferSubmitInfoKHR = commandBufferSubmitInfos[8] {
// ...
{
.commandBuffer = commandBuffers[i],
.deviceMask = 0 // replaces VkDeviceGroupSubmitInfo
},
};
VkSubmitInfo2KHR submitInfo = {
.pNext = nullptr, // All 3 struct above are built into VkSubmitInfo2KHR
.flags = VK_SUBMIT_PROTECTED_BIT_KHR, // also can be zero, replaces VkProtectedSubmitInfo
.waitSemaphoreInfoCount = 1,
.pWaitSemaphoreInfos = waitSemaphoreSubmitInfo,
.commandBufferInfoCount = 8,
.pCommandBufferInfos = commandBufferSubmitInfos,
.signalSemaphoreInfoCount = 1,
.pSignalSemaphoreInfos = signalSemaphoreSubmitInfo
}
vkQueueSubmit2KHR(queue, 1, submitInfo, fence);The difference between the two examples code snippets above is that the vkQueueSubmit2KHR will signal VkSemaphore signalSemaphore when the vertex shader stage is complete compared to the vkQueueSubmit call which will wait until the end of the submission.
To emulate the same behavior of semaphore signaling from vkQueueSubmit in vkQueueSubmit2KHR the stageMask can be set to VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT
// Waits until everything is done
VkSemaphoreSubmitInfoKHR signalSemaphoreSubmitInfo = {
// ...
.stageMask = VK_PIPELINE_STAGE_2_ALL_COMMANDS_BIT,
// ...
};27.9. Emulation Layer
For devices that do not natively support this extension, there is a portable implementation in the Vulkan-Extensionlayer repository. This layer should work with any Vulkan device. For more information see the layer documentation and the Sync2Compat.Vulkan10 test case.
| Note | The |
permalink:/Notes/004-3d-rendering/vulkan/chapters/memory_allocation.html layout: default ---
28. Memory Allocation
Managing the device memory in Vulkan is something some developers might be new to and it is important to understand some of the basics.
Two really great Khronos presentations on Vulkan Memory Management from Vulkan Dev Day Montreal (video) and 2018 Vulkanised (video) are great ways to learn some of the main concepts.
It is also worth noting that managing memory is not easy and developers might want to opt instead to use libraries such as Vulkan Memory Allocator to help.
28.1. Sub-allocation
Sub-allocation is considered to be a first-class approach when working in Vulkan. It is also important to realize there is a maxMemoryAllocationCount which creates a limit to the number of simultaneously active allocations an application can use at once. Memory allocation and deallocation at the OS/driver level is likely to be really slow which is another reason for sub-allocation. A Vulkan app should aim to create large allocations and then manage them itself.
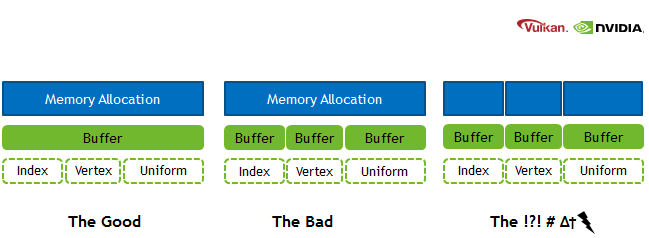
28.2. Transfer
The VkPhysicalDeviceType advertises two main different types of GPUs, discrete and integrated (also referred to as UMA (unified memory architecture). It is important for performance to understand the difference between the two.
Discrete graphics cards contain their own dedicated memory on the device. The data is transferred over a bus (such as PCIe) which is usually a bottleneck due to the physical speed limitation of transferring data. Some physical devices will advertise a queue with a VK_QUEUE_TRANSFER_BIT which allows for a dedicated queue for transferring data. The common practice is to create a staging buffer to copy the host data into before sending through a command buffer to copy over to the device local memory.
UMA systems share the memory between the device and host which is advertised with a VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT | VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT combination. The disadvantage of this is that system memory has to be shared with the GPU which requires being cautious of memory pressure. The main advantage is that there is no need to create a staging buffer and the transfer overhead is greatly reduced.
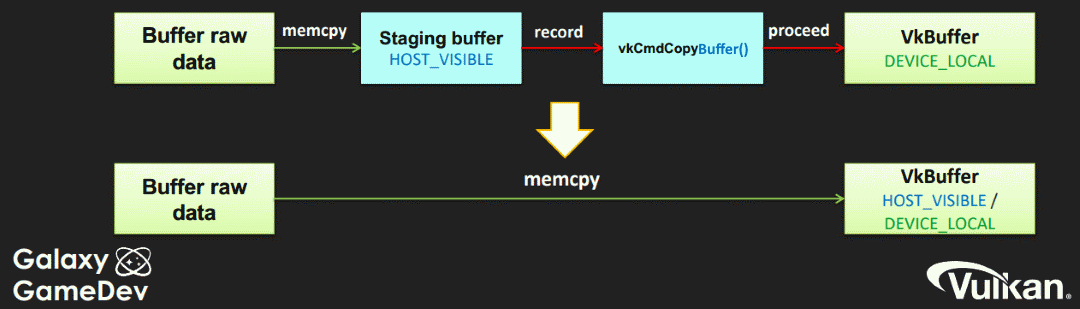
28.3. Lazily Allocated Memory
On tile-based architectures (virtually all mobile GPUs) the LAZILY_ALLOCATED_BIT memory type is not backed by actual memory. It can be used for attachments that can be held in tile memory, such as the G-buffer between subpasses, depth buffer, or multi-sampled images. This saves some significant bandwidth cost for writing the image back to memory. You can find more information in Khronos' tutorials on Render Passes and Subpasses.
permalink:/Notes/004-3d-rendering/vulkan/chapters/sparse_resources.html layout: default ---
29. Sparse Resources
Vulkan sparse resources are a way to create VkBuffer and VkImage objects which can be bound non-contiguously to one or more VkDeviceMemory allocations. There are many aspects and features of sparse resources which the spec does a good job explaining. As the implementation guidelines point out, most implementations use sparse resources to expose a linear virtual address range of memory to the application while mapping each sparse block to physical pages when bound.
29.1. Binding Sparse Memory
Unlike normal resources that call vkBindBufferMemory() or vkBindImageMemory(), sparse memory is bound via a queue operation vkQueueBindSparse(). The main advantage of this is that an application can rebind memory to a sparse resource throughout its lifetime.
It is important to notice that this requires some extra consideration from the application. Applications must use synchronization primitives to guarantee that other queues do not access ranges of memory concurrently with a binding change. Also, freeing a VkDeviceMemory object with vkFreeMemory() will not cause resources (or resource regions) bound to the memory object to become unbound. Applications must not access resources bound to memory that has been freed.
29.2. Sparse Buffers
The following example is used to help visually showcase how a sparse VkBuffer looks in memory. Note, it is not required, but most implementations will use sparse block sizes of 64 KB for VkBuffer (actual size is returned in VkMemoryRequirements::alignment).
Imagine a 256 KB VkBuffer where there are 3 parts that an application wants to update separately.
-
Section A - 64 KB
-
Section B - 128 KB
-
Section C - 64 KB
The following showcases how the application views the VkBuffer:
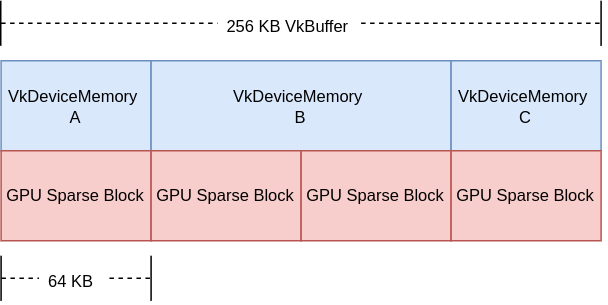
29.2.1. Sparse Images
Mip Tail Regions
Sparse images can be used to update mip levels separately which results in a mip tail region. The spec describes the various examples that can occur with diagrams.
Basic Sparse Resources Example
The following examples illustrate basic creation of sparse images and binding them to physical memory.
This basic example creates a normal VkImage object but uses fine-grained memory allocation to back the resource with multiple memory ranges.
VkDevice device;
VkQueue queue;
VkImage sparseImage;
VkAllocationCallbacks* pAllocator = NULL;
VkMemoryRequirements memoryRequirements = {};
VkDeviceSize offset = 0;
VkSparseMemoryBind binds[MAX_CHUNKS] = {}; // MAX_CHUNKS is NOT part of Vulkan
uint32_t bindCount = 0;
// ...
// Allocate image object
const VkImageCreateInfo sparseImageInfo =
{
VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO, // sType
NULL, // pNext
VK_IMAGE_CREATE_SPARSE_BINDING_BIT | ..., // flags
...
};
vkCreateImage(device, &sparseImageInfo, pAllocator, &sparseImage);
// Get memory requirements
vkGetImageMemoryRequirements(
device,
sparseImage,
&memoryRequirements);
// Bind memory in fine-grained fashion, find available memory ranges
// from potentially multiple VkDeviceMemory pools.
// (Illustration purposes only, can be optimized for perf)
while (memoryRequirements.size && bindCount < MAX_CHUNKS)
{
VkSparseMemoryBind* pBind = &binds[bindCount];
pBind->resourceOffset = offset;
AllocateOrGetMemoryRange(
device,
&memoryRequirements,
&pBind->memory,
&pBind->memoryOffset,
&pBind->size);
// memory ranges must be sized as multiples of the alignment
assert(IsMultiple(pBind->size, memoryRequirements.alignment));
assert(IsMultiple(pBind->memoryOffset, memoryRequirements.alignment));
memoryRequirements.size -= pBind->size;
offset += pBind->size;
bindCount++;
}
// Ensure entire image has backing
if (memoryRequirements.size)
{
// Error condition - too many chunks
}
const VkSparseImageOpaqueMemoryBindInfo opaqueBindInfo =
{
sparseImage, // image
bindCount, // bindCount
binds // pBinds
};
const VkBindSparseInfo bindSparseInfo =
{
VK_STRUCTURE_TYPE_BIND_SPARSE_INFO, // sType
NULL, // pNext
...
1, // imageOpaqueBindCount
&opaqueBindInfo, // pImageOpaqueBinds
...
};
// vkQueueBindSparse is externally synchronized per queue object.
AcquireQueueOwnership(queue);
// Actually bind memory
vkQueueBindSparse(queue, 1, &bindSparseInfo, VK_NULL_HANDLE);
ReleaseQueueOwnership(queue);Advanced Sparse Resources
This more advanced example creates an arrayed color attachment / texture image and binds only LOD zero and the required metadata to physical memory.
VkDevice device;
VkQueue queue;
VkImage sparseImage;
VkAllocationCallbacks* pAllocator = NULL;
VkMemoryRequirements memoryRequirements = {};
uint32_t sparseRequirementsCount = 0;
VkSparseImageMemoryRequirements* pSparseReqs = NULL;
VkSparseMemoryBind binds[MY_IMAGE_ARRAY_SIZE] = {};
VkSparseImageMemoryBind imageBinds[MY_IMAGE_ARRAY_SIZE] = {};
uint32_t bindCount = 0;
// Allocate image object (both renderable and sampleable)
const VkImageCreateInfo sparseImageInfo =
{
VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO, // sType
NULL, // pNext
VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT | ..., // flags
...
VK_FORMAT_R8G8B8A8_UNORM, // format
...
MY_IMAGE_ARRAY_SIZE, // arrayLayers
...
VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT |
VK_IMAGE_USAGE_SAMPLED_BIT, // usage
...
};
vkCreateImage(device, &sparseImageInfo, pAllocator, &sparseImage);
// Get memory requirements
vkGetImageMemoryRequirements(
device,
sparseImage,
&memoryRequirements);
// Get sparse image aspect properties
vkGetImageSparseMemoryRequirements(
device,
sparseImage,
&sparseRequirementsCount,
NULL);
pSparseReqs = (VkSparseImageMemoryRequirements*)
malloc(sparseRequirementsCount * sizeof(VkSparseImageMemoryRequirements));
vkGetImageSparseMemoryRequirements(
device,
sparseImage,
&sparseRequirementsCount,
pSparseReqs);
// Bind LOD level 0 and any required metadata to memory
for (uint32_t i = 0; i < sparseRequirementsCount; ++i)
{
if (pSparseReqs[i].formatProperties.aspectMask &
VK_IMAGE_ASPECT_METADATA_BIT)
{
// Metadata must not be combined with other aspects
assert(pSparseReqs[i].formatProperties.aspectMask ==
VK_IMAGE_ASPECT_METADATA_BIT);
if (pSparseReqs[i].formatProperties.flags &
VK_SPARSE_IMAGE_FORMAT_SINGLE_MIPTAIL_BIT)
{
VkSparseMemoryBind* pBind = &binds[bindCount];
pBind->memorySize = pSparseReqs[i].imageMipTailSize;
bindCount++;
// ... Allocate memory range
pBind->resourceOffset = pSparseReqs[i].imageMipTailOffset;
pBind->memoryOffset = /* allocated memoryOffset */;
pBind->memory = /* allocated memory */;
pBind->flags = VK_SPARSE_MEMORY_BIND_METADATA_BIT;
}
else
{
// Need a mip tail region per array layer.
for (uint32_t a = 0; a < sparseImageInfo.arrayLayers; ++a)
{
VkSparseMemoryBind* pBind = &binds[bindCount];
pBind->memorySize = pSparseReqs[i].imageMipTailSize;
bindCount++;
// ... Allocate memory range
pBind->resourceOffset = pSparseReqs[i].imageMipTailOffset +
(a * pSparseReqs[i].imageMipTailStride);
pBind->memoryOffset = /* allocated memoryOffset */;
pBind->memory = /* allocated memory */
pBind->flags = VK_SPARSE_MEMORY_BIND_METADATA_BIT;
}
}
}
else
{
// resource data
VkExtent3D lod0BlockSize =
{
AlignedDivide(
sparseImageInfo.extent.width,
pSparseReqs[i].formatProperties.imageGranularity.width);
AlignedDivide(
sparseImageInfo.extent.height,
pSparseReqs[i].formatProperties.imageGranularity.height);
AlignedDivide(
sparseImageInfo.extent.depth,
pSparseReqs[i].formatProperties.imageGranularity.depth);
}
size_t totalBlocks =
lod0BlockSize.width *
lod0BlockSize.height *
lod0BlockSize.depth;
// Each block is the same size as the alignment requirement,
// calculate total memory size for level 0
VkDeviceSize lod0MemSize = totalBlocks * memoryRequirements.alignment;
// Allocate memory for each array layer
for (uint32_t a = 0; a < sparseImageInfo.arrayLayers; ++a)
{
// ... Allocate memory range
VkSparseImageMemoryBind* pBind = &imageBinds[a];
pBind->subresource.aspectMask = pSparseReqs[i].formatProperties.aspectMask;
pBind->subresource.mipLevel = 0;
pBind->subresource.arrayLayer = a;
pBind->offset = (VkOffset3D){0, 0, 0};
pBind->extent = sparseImageInfo.extent;
pBind->memoryOffset = /* allocated memoryOffset */;
pBind->memory = /* allocated memory */;
pBind->flags = 0;
}
}
free(pSparseReqs);
}
const VkSparseImageOpaqueMemoryBindInfo opaqueBindInfo =
{
sparseImage, // image
bindCount, // bindCount
binds // pBinds
};
const VkSparseImageMemoryBindInfo imageBindInfo =
{
sparseImage, // image
sparseImageInfo.arrayLayers, // bindCount
imageBinds // pBinds
};
const VkBindSparseInfo bindSparseInfo =
{
VK_STRUCTURE_TYPE_BIND_SPARSE_INFO, // sType
NULL, // pNext
...
1, // imageOpaqueBindCount
&opaqueBindInfo, // pImageOpaqueBinds
1, // imageBindCount
&imageBindInfo, // pImageBinds
...
};
// vkQueueBindSparse is externally synchronized per queue object.
AcquireQueueOwnership(queue);
// Actually bind memory
vkQueueBindSparse(queue, 1, &bindSparseInfo, VK_NULL_HANDLE);
ReleaseQueueOwnership(queue);permalink:/Notes/004-3d-rendering/vulkan/chapters/protected.html layout: default ---
30. Protected Memory
Protected memory divides device memory into “protected device memory” and “unprotected device memory”.
In general, most OS don’t allow one application to access another application’s GPU memory unless explicitly shared (e.g. via external memory). A common example of protected memory is for containing DRM content, which a process might be allowed to modify (e.g. for image filtering, or compositing playback controls and closed captions) but shouldn' be able to extract into unprotected memory. The data comes in encrypted and remains encrypted until it reaches the pixels on the display.
The Vulkan Spec explains in detail what “protected device memory” enforces. The following is a breakdown of what is required in order to properly enable a protected submission using protected memory.
30.1. Checking for support
Protected memory was added in Vulkan 1.1 and there was no extension prior. This means any Vulkan 1.0 device will not be capable of supporting protected memory. To check for support, an application must query and enable the VkPhysicalDeviceProtectedMemoryFeatures::protectedMemory field.
30.2. Protected queues
A protected queue can read both protected and unprotected memory, but can only write to protected memory. If a queue can write to unprotected memory, then it can’t also read from protected memory.
| Note | Often performance counters and other timing measurement systems are disabled or less accurate for protected queues to prevent side-channel attacks. |
Using vkGetPhysicalDeviceQueueFamilyProperties to get the VkQueueFlags of each queue, an application can find a queue family with VK_QUEUE_PROTECTED_BIT flag exposed. This does not mean the queues from the family are always protected, but rather the queues can be a protected queue.
To tell the driver to make the VkQueue protected, the VK_DEVICE_QUEUE_CREATE_PROTECTED_BIT is needed in VkDeviceQueueCreateInfo during vkCreateDevice.
The following pseudo code is how an application could request for 2 protected VkQueue objects to be created from the same queue family:
VkDeviceQueueCreateInfo queueCreateInfo[1];
queueCreateInfo[0].flags = VK_DEVICE_QUEUE_CREATE_PROTECTED_BIT;
queueCreateInfo[0].queueFamilyIndex = queueFamilyFound;
queueCreateInfo[0].queueCount = 2; // assuming 2 queues are in the queue family
VkDeviceCreateInfo deviceCreateInfo = {};
deviceCreateInfo.pQueueCreateInfos = queueCreateInfo;
deviceCreateInfo.queueCreateInfoCount = 1;
vkCreateDevice(physicalDevice, &deviceCreateInfo, nullptr, &deviceHandle);It is also possible to split the queues in a queue family so some are protected and some are not. The following pseudo code is how an application could request for 1 protected VkQueue and 1 unprotected VkQueue objects to be created from the same queue family:
VkDeviceQueueCreateInfo queueCreateInfo[2];
queueCreateInfo[0].flags = VK_DEVICE_QUEUE_CREATE_PROTECTED_BIT;
queueCreateInfo[0].queueFamilyIndex = queueFamilyFound;
queueCreateInfo[0].queueCount = 1;
queueCreateInfo[1].flags = 0; // unprotected because the protected flag is not set
queueCreateInfo[1].queueFamilyIndex = queueFamilyFound;
queueCreateInfo[1].queueCount = 1;
VkDeviceCreateInfo deviceCreateInfo = {};
deviceCreateInfo.pQueueCreateInfos = queueCreateInfo;
deviceCreateInfo.queueCreateInfoCount = 2;
vkCreateDevice(physicalDevice, &deviceCreateInfo, nullptr, &deviceHandle);Now instead of using vkGetDeviceQueue an application has to use vkGetDeviceQueue2 in order to pass the VK_DEVICE_QUEUE_CREATE_PROTECTED_BIT flag when getting the VkQueue handle.
VkDeviceQueueInfo2 info = {};
info.queueFamilyIndex = queueFamilyFound;
info.queueIndex = 0;
info.flags = VK_DEVICE_QUEUE_CREATE_PROTECTED_BIT;
vkGetDeviceQueue2(deviceHandle, &info, &protectedQueue);30.3. Protected resources
When creating a VkImage or VkBuffer to make them protected is as simple as setting VK_IMAGE_CREATE_PROTECTED_BIT and VK_BUFFER_CREATE_PROTECTED_BIT respectively.
When binding memory to the protected resource, the VkDeviceMemory must have been allocated from a VkMemoryType with the VK_MEMORY_PROPERTY_PROTECTED_BIT bit.
30.4. Protected swapchain
When creating a swapchain the VK_SWAPCHAIN_CREATE_PROTECTED_BIT_KHR bit is used to make a protected swapchain.
All VkImage from vkGetSwapchainImagesKHR using a protected swapchain are the same as if the image was created with VK_IMAGE_CREATE_PROTECTED_BIT.
Sometimes it is unknown whether swapchains can be created with the VK_SWAPCHAIN_CREATE_PROTECTED_BIT_KHR flag set. The VK_KHR_surface_protected_capabilities extension is exposed on platforms where this might be unknown.
30.5. Protected command buffer
Using the protected VkQueue, an application can also use VK_COMMAND_POOL_CREATE_PROTECTED_BIT when creating a VkCommandPool
VkCommandPoolCreateInfo info = {};
info.flags = VK_COMMAND_POOL_CREATE_PROTECTED_BIT;
info.queueFamilyIndex = queueFamilyFound; // protected queue
vkCreateCommandPool(deviceHandle, &info, nullptr, &protectedCommandPool));All command buffers allocated from the protected command pool become “protected command buffers”
VkCommandBufferAllocateInfo info = {};
info.commandPool = protectedCommandPool;
vkAllocateCommandBuffers(deviceHandle, &info, &protectedCommandBuffers);30.6. Submitting protected work
When submitting work to be protected, all the VkCommandBuffer submitted must also be protected.
VkProtectedSubmitInfo protectedSubmitInfo = {};
protectedSubmitInfo.protectedSubmit = true;
VkSubmitInfo submitInfo = {};
submitInfo.pNext = &protectedSubmitInfo;
submitInfo.pCommandBuffers = protectedCommandBuffers;
vkQueueSubmit(protectedQueue, 1, &submitInfo, fence));or using VK_KHR_synchronization2
VkSubmitInfo2KHR submitInfo = {}
submitInfo.flags = VK_SUBMIT_PROTECTED_BIT_KHR;
vkQueueSubmit2KHR(protectedQueue, 1, submitInfo, fence);permalink:/Notes/004-3d-rendering/vulkan/chapters/pipeline_cache.html layout: default ---
31. Pipeline Cache
Pipeline caching is a technique used with VkPipelineCache objects to reuse pipelines that have already been created. Pipeline creation can be somewhat costly - it has to compile the shaders at creation time for example. The big advantage of a pipeline cache is that the pipeline state can be saved to a file to be used between runs of an application, eliminating some of the costly parts of creation. There is a great Khronos presentation on pipeline caching from SIGGRAPH 2016 (video) starting on slide 140.

While pipeline caches are an important tool, it is important to create a robust system for them which Arseny Kapoulkine talks about in his blog post.
To illustrate the performance gain and see a reference implementation of pipeline caches Khronos offers a sample and tutorial.
permalink:/Notes/004-3d-rendering/vulkan/chapters/threading.html layout: default ---
32. Threading
One of the big differences between Vulkan and OpenGL is that Vulkan is not limited to a single-threaded state machine system. Before running off to implement threads in an application, it is important to understand how threading works in Vulkan.
The Vulkan Spec Threading Behavior section explains in detail how applications are in charge of managing all externally synchronized elements of Vulkan. It is important to realize that multithreading in Vulkan only provides host-side scaling, as anything interacting with the device still needs to be synchronized correctly
Vulkan implementations are not supposed to introduce any multi-threading, so if an app wants multi-CPU performance, the app is in charge of managing the threading.
32.1. Command Pools
Command Pools are a system to allow recording command buffers across multiple threads. A single command pool must be externally synchronized; it must not be accessed simultaneously from multiple threads. By using a separate command pool in each host-thread the application can create multiple command buffers in parallel without any costly locks.
The idea is command buffers can be recorded on multiple threads while having a relatively light thread handle the submissions.
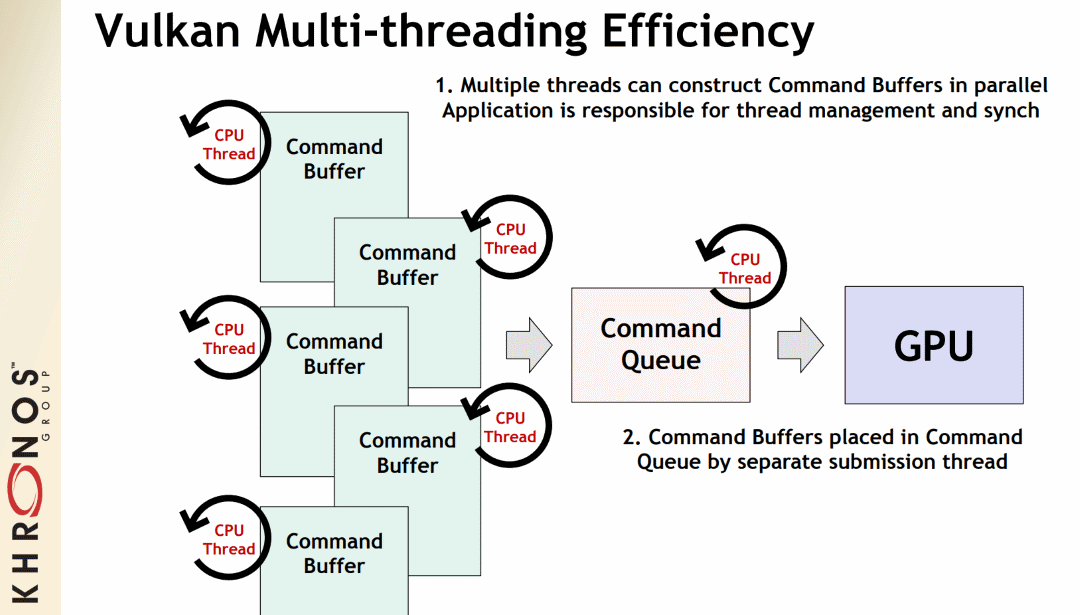
Khronos' sample and tutorial show in more detail how to record command buffers in parallel.
32.2. Descriptor Pools
Descriptor Pools are used to allocate, free, reset, and update descriptor sets. By creating multiple descriptor pools, each application host thread is able to manage a descriptor set in each descriptor pool at the same time.
permalink: /Notes/004-3d-rendering/vulkan/chapters/depth.html layout: default ---
33. Depth
The term depth is used in various spots in the Vulkan Spec. This chapter is aimed to give an overview of the various "depth" terminology used in Vulkan. Some basic knowledge of 3D graphics is needed to get the most out of this chapter.
| Note | While stencil is closely related depth, this chapter does not aim to cover it outside the realm of API names |
33.1. Graphics Pipeline
The concept of "depth" is only used for graphics pipelines in Vulkan and doesn’t take effect until a draw call is submitted.
Inside the VkGraphicsPipelineCreateInfo there are many different values related to depth that can be controlled. Some states are even dynamic as well.
33.2. Depth Formats
There are a few different depth formats and an implementation may expose support for in Vulkan.
For reading from a depth image only VK_FORMAT_D16_UNORM and VK_FORMAT_D32_SFLOAT are required to support being read via sampling or blit operations.
For writing to a depth image VK_FORMAT_D16_UNORM is required to be supported. From here at least one of (VK_FORMAT_X8_D24_UNORM_PACK32 or VK_FORMAT_D32_SFLOAT) and (VK_FORMAT_D24_UNORM_S8_UINT or VK_FORMAT_D32_SFLOAT_S8_UINT) must also be supported. This will involve some extra logic when trying to find which format to use if both the depth and stencil are needed in the same format.
// Example of query logic
VkFormatProperties properties;
vkGetPhysicalDeviceFormatProperties(physicalDevice, VK_FORMAT_D24_UNORM_S8_UINT, &properties);
bool d24s8_support = (properties.optimalTilingFeatures & VK_FORMAT_FEATURE_DEPTH_STENCIL_ATTACHMENT_BIT);
vkGetPhysicalDeviceFormatProperties(physicalDevice, VK_FORMAT_D32_SFLOAT_S8_UINT, &properties);
bool d32s8_support = (properties.optimalTilingFeatures & VK_FORMAT_FEATURE_DEPTH_STENCIL_ATTACHMENT_BIT);
assert(d24s8_support | d32s8_support); // will always support at least one33.3. Depth Buffer as a VkImage
The term "depth buffer" is used a lot when talking about graphics, but in Vulkan, it is just a VkImage/VkImageView that a VkFramebuffer can reference at draw time. When creating a VkRenderPass the pDepthStencilAttachment value points to the depth attachment in the framebuffer.
In order to use pDepthStencilAttachment the backing VkImage must have been created with VK_IMAGE_USAGE_DEPTH_STENCIL_ATTACHMENT_BIT.
When performing operations such as image barriers or clearing where the VkImageAspectFlags is required, the VK_IMAGE_ASPECT_DEPTH_BIT is used to reference the depth memory.
33.3.1. Layout
When selecting the VkImageLayout there are some layouts that allow for both reading and writing to the image:
-
VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL
-
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_STENCIL_READ_ONLY_OPTIMAL
-
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_OPTIMAL
as well as layouts that allow for only reading to the image:
-
VK_IMAGE_LAYOUT_DEPTH_STENCIL_READ_ONLY_OPTIMAL
-
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_STENCIL_ATTACHMENT_OPTIMAL
-
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_OPTIMAL
When doing the layout transition make sure to set the proper depth access masks needed for both reading and writing the depth image.
// Example of going from undefined layout to a depth attachment to be read and written to
// Core Vulkan example
srcAccessMask = 0;
dstAccessMask = VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_READ_BIT | VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
sourceStage = VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT;
destinationStage = VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT | VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT;
// VK_KHR_synchronization2
srcAccessMask = VK_ACCESS_2_NONE_KHR;
dstAccessMask = VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_READ_BIT_KHR | VK_ACCESS_2_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT_KHR;
sourceStage = VK_PIPELINE_STAGE_2_NONE_KHR;
destinationStage = VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT_KHR | VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT_KHR;| Note | If unsure to use only early or late fragment tests for your application, use both. |
33.3.2. Clearing
It is always better to clear a depth buffer at the start of the pass with loadOp set to VK_ATTACHMENT_LOAD_OP_CLEAR, but depth images can also be cleared outside a render pass using vkCmdClearDepthStencilImage.
When clearing, notice that VkClearValue is a union and VkClearDepthStencilValue depthStencil should be set instead of the color clear value.
33.4. Pre-rasterization
In the graphics pipeline, there are a series of pre-rasterization shader stages that generate primitives to be rasterized. Before reaching the rasterization step, the final vec4 position (gl_Position) of the last pre-rasterization stage runs through Fixed-Function Vertex Post-Processing.
The following gives a high level overview of the various coordinates name and operations that occur before rasterization.

33.4.1. Primitive Clipping
Clipping always occurs, unless using the depthClipEnable from VK_EXT_depth_clip_enable, if the primitive is outside the view volume. In Vulkan, this is expressed for depth as
0 <= Zc <= WcWhen the normalized device coordinates (NDC) are calculated, anything outside of [0, 1] is clipped.
A few examples where Zd is the result of Zc/Wc:
-
vec4(1.0, 1.0, 2.0, 2.0)- not clipped (Zd==1.0) -
vec4(1.0, 1.0, 0.0, 2.0)- not clipped (Zd==0.0) -
vec4(1.0, 1.0, -1.0, 2.0)- clipped (Zd==-0.5) -
vec4(1.0, 1.0, -1.0, -2.0)- not clipped (Zd==0.5)
User defined clipping and culling
Using ClipDistance and CullDistance built-in arrays the pre-rasterization shader stages can set user defined clipping and culling.
In the last pre-rasterization shader stage, these values will be linearly interpolated across the primitive and the portion of the primitive with interpolated distances less than 0 will be considered outside the clip volume. If ClipDistance or CullDistance are then used by a fragment shader, they contain these linearly interpolated values.
| Note |
|
Porting from OpenGL
In OpenGL the view volume is expressed as
-Wc <= Zc <= Wcand anything outside of [-1, 1] is clipped.
The VK_EXT_depth_clip_control extension was added to allow efficient layering of OpenGL over Vulkan. By setting the VkPipelineViewportDepthClipControlCreateInfoEXT::negativeOneToOne to VK_TRUE when creating the VkPipeline it will use the OpenGL [-1, 1] view volume.
If VK_EXT_depth_clip_control is not available, the workaround currently is to perform the conversion in the pre-rasterization shader
// [-1,1] to [0,1]
position.z = (position.z + position.w) * 0.5;33.4.2. Viewport Transformation
The viewport transformation is a transformation from normalized device coordinates to framebuffer coordinates, based on a viewport rectangle and depth range.
The list of viewports being used in the pipeline is expressed by VkPipelineViewportStateCreateInfo::pViewports and VkPipelineViewportStateCreateInfo::viewportCount sets the number of viewports being used. If VkPhysicalDeviceFeatures::multiViewport is not enabled, there must only be 1 viewport.
| Note | The viewport value can be set dynamically using |
Depth Range
Each viewport holds a VkViewport::minDepth and VkViewport::maxDepth value which sets the "depth range" for the viewport.
| Note | Despite their names, |
The minDepth and maxDepth are restricted to be set inclusively between 0.0 and 1.0. If the VK_EXT_depth_range_unrestricted is enabled, this restriction goes away.
The framebuffer depth coordinate Zf is represented as:
Zf = Pz * Zd + Oz-
Zd=Zc/Wc(see Primitive Clipping) -
Oz=minDepth -
Pz=maxDepth-minDepth
33.5. Rasterization
33.5.1. Depth Bias
The depth values of all fragments generated by the rasterization of a polygon can be offset by a single value that is computed for that polygon. If VkPipelineRasterizationStateCreateInfo::depthBiasEnable is VK_FALSE at draw time, no depth bias is applied.
Using the depthBiasConstantFactor, depthBiasClamp, and depthBiasSlopeFactor in VkPipelineRasterizationStateCreateInfo the depth bias can be calculated.
| Note | Requires the |
| Note | The depth bias values can be set dynamically using |
33.6. Post-rasterization
33.6.1. Fragment Shader
The input built-in FragCoord is the framebuffer coordinate. The Z component is the interpolated depth value of the primitive. This Z component value will be written to FragDepth if the shader doesn’t write to it. If the shader dynamically writes to FragDepth, the DepthReplacing Execution Mode must be declared (This is done in tools such as glslang).
| Note |
|
| Note | When using |
Conservative depth
The DepthGreater, DepthLess, and DepthUnchanged Executation Mode allow for a possible optimization for implementations that relies on an early depth test to be run before the fragment. This can be easily done in GLSL by declaring gl_FragDepth with the proper layout qualifier.
// assume it may be modified in any way
layout(depth_any) out float gl_FragDepth;
// assume it may be modified such that its value will only increase
layout(depth_greater) out float gl_FragDepth;
// assume it may be modified such that its value will only decrease
layout(depth_less) out float gl_FragDepth;
// assume it will not be modified
layout(depth_unchanged) out float gl_FragDepth;Violating the condition yields undefined behavior.
33.6.2. Per-sample processing and coverage mask
The following post-rasterization occurs as a "per-sample" operation. This means when doing multisampling with a color attachment, any "depth buffer" VkImage used as well must also have been created with the same VkSampleCountFlagBits value.
Each fragment has a coverage mask based on which samples within that fragment are determined to be within the area of the primitive that generated the fragment. If a fragment operation results in all bits of the coverage mask being 0, the fragment is discarded.
Resolving depth buffer
It is possible in Vulkan using the VK_KHR_depth_stencil_resolve extension (promoted to Vulkan core in 1.2) to resolve multisampled depth/stencil attachments in a subpass in a similar manner as for color attachments.
33.6.3. Depth Bounds
| Note | Requires the |
If VkPipelineDepthStencilStateCreateInfo::depthBoundsTestEnable is used to take each Za in the depth attachment and check if it is within the range set by VkPipelineDepthStencilStateCreateInfo::minDepthBounds and VkPipelineDepthStencilStateCreateInfo::maxDepthBounds. If the value is not within the bounds, the coverage mask is set to zero.
| Note | The depth bound values can be set dynamically using |
33.6.4. Depth Test
The depth test compares the framebuffer depth coordinate Zf with the depth value Za in the depth attachment. If the test fails, the fragment is discarded. If the test passes, the depth attachment will be updated with the fragment’s output depth. The VkPipelineDepthStencilStateCreateInfo::depthTestEnable is used to enable/disable the test in the pipeline.
The following gives a high level overview of the depth test.
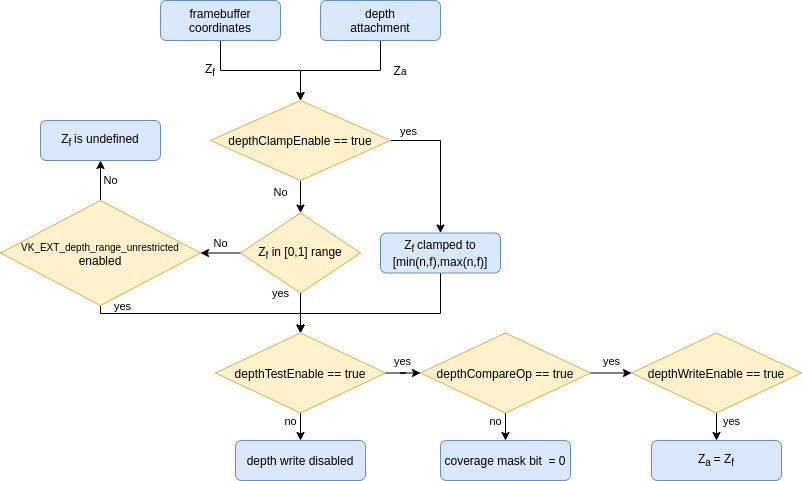
Depth Compare Operation
The VkPipelineDepthStencilStateCreateInfo::depthCompareOp provides the comparison function used for the depth test.
An example where depthCompareOp == VK_COMPARE_OP_LESS (Zf < Za)
-
Zf= 1.0 |Za= 2.0 | test passes -
Zf= 1.0 |Za= 1.0 | test fails -
Zf= 1.0 |Za= 0.0 | test fails
| Note | The |
Depth Buffer Writes
Even if the depth test passes, if VkPipelineDepthStencilStateCreateInfo::depthWriteEnable is set to VK_FALSE it will not write the value out to the depth attachment. The main reason for this is because the depth test itself will set the coverage mask which can be used for certain render techniques.
| Note | The |
Depth Clamping
| Note | Requires the |
Prior to the depth test, if VkPipelineRasterizationStateCreateInfo::depthClampEnable is enabled, before the sample's Zf is compared to Za, Zf is clamped to [min(n,f), max(n,f)], where n and f are the minDepth and maxDepth depth range values of the viewport used by this fragment, respectively.
permalink:/Notes/004-3d-rendering/vulkan/chapters/mapping_data_to_shaders.html layout: default ---
34. Mapping Data to Shaders
| Note | All SPIR-V assembly was generated with glslangValidator |
This chapter goes over how to interface Vulkan with SPIR-V in order to map data. Using the VkDeviceMemory objects allocated from vkAllocateMemory, it is up to the application to properly map the data from Vulkan such that the SPIR-V shader understands how to consume it correctly.
In core Vulkan, there are 5 fundamental ways to map data from your Vulkan application to interface with SPIR-V:
34.1. Input Attributes
The only shader stage in core Vulkan that has an input attribute controlled by Vulkan is the vertex shader stage (VK_SHADER_STAGE_VERTEX_BIT). This involves declaring the interface slots when creating the VkPipeline and then binding the VkBuffer before draw time with the data to map. Other shaders stages, such as a fragment shader stage, has input attributes, but the values are determined from the output of the previous stages ran before it.
Before calling vkCreateGraphicsPipelines a VkPipelineVertexInputStateCreateInfo struct will need to be filled out with a list of VkVertexInputAttributeDescription mappings to the shader.
An example GLSL vertex shader:
#version 450
layout(location = 0) in vec3 inPosition;
void main() {
gl_Position = vec4(inPosition, 1.0);
}There is only a single input attribute at location 0. This can also be seen in the generated SPIR-V assembly:
Name 18 "inPosition"
Decorate 18(inPosition) Location 0
17: TypePointer Input 16(fvec3)
18(inPosition): 17(ptr) Variable Input
19: 16(fvec3) Load 18(inPosition)In this example, the following could be used for the VkVertexInputAttributeDescription:
VkVertexInputAttributeDescription input = {};
input.location = 0;
input.binding = 0;
input.format = VK_FORMAT_R32G32B32_SFLOAT; // maps to vec3
input.offset = 0;The only thing left to do is bind the vertex buffer and optional index buffer prior to the draw call.
| Note | Using |
vkBeginCommandBuffer();
// ...
vkCmdBindVertexBuffer();
vkCmdDraw();
// ...
vkCmdBindVertexBuffer();
vkCmdBindIndexBuffer();
vkCmdDrawIndexed();
// ...
vkEndCommandBuffer();| Note | More information can be found in the Vertex Input Data Processing chapter |
34.2. Descriptors
A resource descriptor is the core way to map data such as uniform buffers, storage buffers, samplers, etc. to any shader stage in Vulkan. One way to conceptualize a descriptor is by thinking of it as a pointer to memory that the shader can use.
There are various descriptor types in Vulkan, each with their own detailed description in what they allow.
Descriptors are grouped together in descriptor sets which get bound to the shader. Even if there is only a single descriptor in the descriptor set, the entire VkDescriptorSet is used when binding to the shader.
34.2.1. Example
In this example, there are the following 3 descriptor sets:
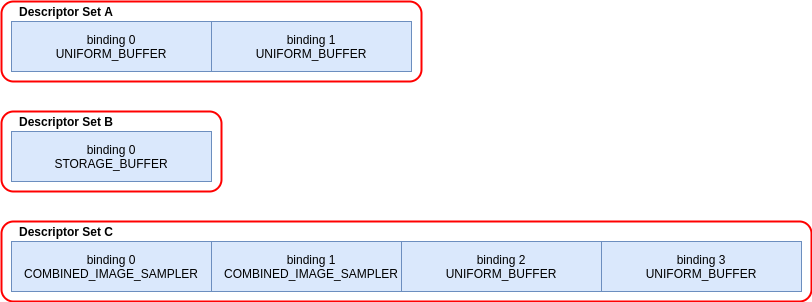
The GLSL of the shader:
// Note - only set 0 and 2 are used in this shader
layout(set = 0, binding = 0) uniform sampler2D myTextureSampler;
layout(set = 0, binding = 2) uniform uniformBuffer0 {
float someData;
} ubo_0;
layout(set = 0, binding = 3) uniform uniformBuffer1 {
float moreData;
} ubo_1;
layout(set = 2, binding = 0) buffer storageBuffer {
float myResults;
} ssbo;The corresponding SPIR-V assembly:
Decorate 19(myTextureSampler) DescriptorSet 0
Decorate 19(myTextureSampler) Binding 0
MemberDecorate 29(uniformBuffer0) 0 Offset 0
Decorate 29(uniformBuffer0) Block
Decorate 31(ubo_0) DescriptorSet 0
Decorate 31(ubo_0) Binding 2
MemberDecorate 38(uniformBuffer1) 0 Offset 0
Decorate 38(uniformBuffer1) Block
Decorate 40(ubo_1) DescriptorSet 0
Decorate 40(ubo_1) Binding 3
MemberDecorate 44(storageBuffer) 0 Offset 0
Decorate 44(storageBuffer) BufferBlock
Decorate 46(ssbo) DescriptorSet 2
Decorate 46(ssbo) Binding 0The binding of descriptors is done while recording the command buffer. The descriptors must be bound at the time of a draw/dispatch call. The following is some pseudo code to better represent this:
vkBeginCommandBuffer();
// ...
vkCmdBindPipeline(); // Binds shader
// One possible way of binding the two sets
vkCmdBindDescriptorSets(firstSet = 0, pDescriptorSets = &descriptor_set_c);
vkCmdBindDescriptorSets(firstSet = 2, pDescriptorSets = &descriptor_set_b);
vkCmdDraw(); // or dispatch
// ...
vkEndCommandBuffer();The following results would look as followed

34.2.2. Descriptor types
The Vulkan Spec has a Shader Resource and Storage Class Correspondence table that describes how each descriptor type needs to be mapped to in SPIR-V.
The following shows an example of what GLSL and SPIR-V mapping to each of the descriptor types looks like.
For GLSL, more information can be found in the GLSL Spec - 12.2.4. Vulkan Only: Samplers, Images, Textures, and Buffers
Storage Image
VK_DESCRIPTOR_TYPE_STORAGE_IMAGE
// VK_FORMAT_R32_UINT
layout(set = 0, binding = 0, r32ui) uniform uimage2D storageImage;
// example usage for reading and writing in GLSL
const uvec4 texel = imageLoad(storageImage, ivec2(0, 0));
imageStore(storageImage, ivec2(1, 1), texel);OpDecorate %storageImage DescriptorSet 0
OpDecorate %storageImage Binding 0
%r32ui = OpTypeImage %uint 2D 0 0 0 2 R32ui
%ptr = OpTypePointer UniformConstant %r32ui
%storageImage = OpVariable %ptr UniformConstantSampler and Sampled Image
VK_DESCRIPTOR_TYPE_SAMPLER and VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE
layout(set = 0, binding = 0) uniform sampler samplerDescriptor;
layout(set = 0, binding = 1) uniform texture2D sampledImage;
// example usage of using texture() in GLSL
vec4 data = texture(sampler2D(sampledImage, samplerDescriptor), vec2(0.0, 0.0));OpDecorate %sampledImage DescriptorSet 0
OpDecorate %sampledImage Binding 1
OpDecorate %samplerDescriptor DescriptorSet 0
OpDecorate %samplerDescriptor Binding 0
%image = OpTypeImage %float 2D 0 0 0 1 Unknown
%imagePtr = OpTypePointer UniformConstant %image
%sampledImage = OpVariable %imagePtr UniformConstant
%sampler = OpTypeSampler
%samplerPtr = OpTypePointer UniformConstant %sampler
%samplerDescriptor = OpVariable %samplerPtr UniformConstant
%imageLoad = OpLoad %image %sampledImage
%samplerLoad = OpLoad %sampler %samplerDescriptor
%sampleImageType = OpTypeSampledImage %image
%1 = OpSampledImage %sampleImageType %imageLoad %samplerLoad
%textureSampled = OpImageSampleExplicitLod %v4float %1 %coordinate Lod %float_0Combined Image Sampler
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER
| Note | On some implementations, it may be more efficient to sample from an image using a combination of sampler and sampled image that are stored together in the descriptor set in a combined descriptor. |
layout(set = 0, binding = 0) uniform sampler2D combinedImageSampler;
// example usage of using texture() in GLSL
vec4 data = texture(combinedImageSampler, vec2(0.0, 0.0));OpDecorate %combinedImageSampler DescriptorSet 0
OpDecorate %combinedImageSampler Binding 0
%imageType = OpTypeImage %float 2D 0 0 0 1 Unknown
%sampleImageType = OpTypeSampledImage imageType
%ptr = OpTypePointer UniformConstant %sampleImageType
%combinedImageSampler = OpVariable %ptr UniformConstant
%load = OpLoad %sampleImageType %combinedImageSampler
%textureSampled = OpImageSampleExplicitLod %v4float %load %coordinate Lod %float_0Uniform Buffer
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER
| Note | Uniform buffers can also have dynamic offsets at bind time (VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC) |
layout(set = 0, binding = 0) uniform uniformBuffer {
float a;
int b;
} ubo;
// example of reading from UBO in GLSL
int x = ubo.b + 1;
vec3 y = vec3(ubo.a);OpMemberDecorate %uniformBuffer 0 Offset 0
OpMemberDecorate %uniformBuffer 1 Offset 4
OpDecorate %uniformBuffer Block
OpDecorate %ubo DescriptorSet 0
OpDecorate %ubo Binding 0
%uniformBuffer = OpTypeStruct %float %int
%ptr = OpTypePointer Uniform %uniformBuffer
%ubo = OpVariable %ptr UniformStorage Buffer
VK_DESCRIPTOR_TYPE_STORAGE_BUFFER
| Note | Storage buffers can also have dynamic offsets at bind time (VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC) |
layout(set = 0, binding = 0) buffer storageBuffer {
float a;
int b;
} ssbo;
// example of reading and writing SSBO in GLSL
ssbo.a = ssbo.a + 1.0;
ssbo.b = ssbo.b + 1;| Note | Important
|
OpMemberDecorate %storageBuffer 0 Offset 0
OpMemberDecorate %storageBuffer 1 Offset 4
OpDecorate %storageBuffer Block
OpDecorate %ssbo DescriptorSet 0
OpDecorate %ssbo Binding 0
%storageBuffer = OpTypeStruct %float %int
%ptr = OpTypePointer StorageBuffer %storageBuffer
%ssbo = OpVariable %ptr StorageBufferUniform Texel Buffer
VK_DESCRIPTOR_TYPE_UNIFORM_TEXEL_BUFFER
layout(set = 0, binding = 0) uniform textureBuffer uniformTexelBuffer;
// example of reading texel buffer in GLSL
vec4 data = texelFetch(uniformTexelBuffer, 0);OpDecorate %uniformTexelBuffer DescriptorSet 0
OpDecorate %uniformTexelBuffer Binding 0
%texelBuffer = OpTypeImage %float Buffer 0 0 0 1 Unknown
%ptr = OpTypePointer UniformConstant %texelBuffer
%uniformTexelBuffer = OpVariable %ptr UniformConstantStorage Texel Buffer
VK_DESCRIPTOR_TYPE_STORAGE_TEXEL_BUFFER
// VK_FORMAT_R8G8B8A8_UINT
layout(set = 0, binding = 0, rgba8ui) uniform uimageBuffer storageTexelBuffer;
// example of reading and writing texel buffer in GLSL
int offset = int(gl_GlobalInvocationID.x);
vec4 data = imageLoad(storageTexelBuffer, offset);
imageStore(storageTexelBuffer, offset, uvec4(0));OpDecorate %storageTexelBuffer DescriptorSet 0
OpDecorate %storageTexelBuffer Binding 0
%rgba8ui = OpTypeImage %uint Buffer 0 0 0 2 Rgba8ui
%ptr = OpTypePointer UniformConstant %rgba8ui
%storageTexelBuffer = OpVariable %ptr UniformConstantInput Attachment
VK_DESCRIPTOR_TYPE_INPUT_ATTACHMENT
layout (input_attachment_index = 0, set = 0, binding = 0) uniform subpassInput inputAttachment;
// example loading the attachment data in GLSL
vec4 data = subpassLoad(inputAttachment);OpDecorate %inputAttachment DescriptorSet 0
OpDecorate %inputAttachment Binding 0
OpDecorate %inputAttachment InputAttachmentIndex 0
%subpass = OpTypeImage %float SubpassData 0 0 0 2 Unknown
%ptr = OpTypePointer UniformConstant %subpass
%inputAttachment = OpVariable %ptr UniformConstant34.3. Push Constants
A push constant is a small bank of values accessible in shaders. Push constants allow the application to set values used in shaders without creating buffers or modifying and binding descriptor sets for each update.
These are designed for small amount (a few dwords) of high frequency data to be updated per-recording of the command buffer.
From a shader perspective, it is similar to a uniform buffer.
#version 450
layout(push_constant) uniform myPushConstants {
vec4 myData;
} myData;Resulting SPIR-V assembly:
MemberDecorate 13(myPushConstants) 0 Offset 0
Decorate 13(myPushConstants) BlockWhile recording the command buffer the values of the push constants are decided.
vkBeginCommandBuffer();
// ...
vkCmdBindPipeline();
float someData[4] = {0.0, 1.0, 2.0, 3.0};
vkCmdPushConstants(sizeof(float) * 4, someData);
vkCmdDraw();
// ...
vkEndCommandBuffer();34.4. Specialization Constants
Specialization constants are a mechanism allowing a constant value in SPIR-V to be specified at VkPipeline creation time. This is powerful as it replaces the idea of doing preprocessor macros in the high level shading language (GLSL, HLSL, etc).
34.4.1. Example
If an application wants to create to VkPipeline where the color value is different for each, a naive approach is to have two shaders:
// shader_a.frag
#version 450
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(0.0);
}// shader_b.frag
#version 450
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(1.0);
}Using specialization constants, the decision can instead be made when calling vkCreateGraphicsPipelines to compile the shader. This means there only needs to be a single shader.
#version 450
layout (constant_id = 0) const float myColor = 1.0;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(myColor);
}Resulting SPIR-V assembly:
Decorate 9(outColor) Location 0
Decorate 10(myColor) SpecId 0
// 0x3f800000 as decimal which is 1.0 for a 32 bit float
10(myColor): 6(float) SpecConstant 1065353216With specialization constants, the value is still a constant inside the shader, but for example, if another VkPipeline uses the same shader, but wants to set the myColor value to 0.5f, it is possible to do so at runtime.
struct myData {
float myColor = 1.0f;
} myData;
VkSpecializationMapEntry mapEntry = {};
mapEntry.constantID = 0; // matches constant_id in GLSL and SpecId in SPIR-V
mapEntry.offset = 0;
mapEntry.size = sizeof(float);
VkSpecializationInfo specializationInfo = {};
specializationInfo.mapEntryCount = 1;
specializationInfo.pMapEntries = &mapEntry;
specializationInfo.dataSize = sizeof(myData);
specializationInfo.pData = &myData;
VkGraphicsPipelineCreateInfo pipelineInfo = {};
pipelineInfo.pStages[fragIndex].pSpecializationInfo = &specializationInfo;
// Create first pipeline with myColor as 1.0
vkCreateGraphicsPipelines(&pipelineInfo);
// Create second pipeline with same shader, but sets different value
myData.myColor = 0.5f;
vkCreateGraphicsPipelines(&pipelineInfo);The second VkPipeline shader disassembled has the new constant value for myColor of 0.5f.
34.4.2. 3 Types of Specialization Constants Usages
The typical use cases for specialization constants can be best grouped into three different usages.
-
Toggling features
-
Support for a feature in Vulkan isn’t known until runtime. This usage of specialization constants is to prevent writing two separate shaders, but instead embedding a constant runtime decision.
-
-
Improving backend optimizations
-
The “backend” here refers the implementation’s compiler that takes the resulting SPIR-V and lowers it down to some ISA to run on the device.
-
Constant values allow a set of optimizations such as constant folding, dead code elimination, etc. to occur.
-
-
Affecting types and memory sizes
-
It is possible to set the length of an array or a variable type used through a specialization constant.
-
It is important to notice that a compiler will need to allocate registers depending on these types and sizes. This means it is likely that a pipeline cache will fail if the difference is significant in registers allocated.
-
34.5. Physical Storage Buffer
The VK_KHR_buffer_device_address extension promoted to Vulkan 1.2 adds the ability to have “pointers in the shader”. Using the PhysicalStorageBuffer storage class in SPIR-V an application can call vkGetBufferDeviceAddress which will return the VkDeviceAddress to the memory.
While this is a way to map data to the shader, it is not a way to interface with the shader. For example, if an application wants to use this with a uniform buffer it would have to create a VkBuffer with both VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT and VK_BUFFER_USAGE_UNIFORM_BUFFER_BIT. From here in this example, Vulkan would use a descriptor to interface with the shader, but could then use the physical storage buffer to update the value after.
34.6. Limits
With all the above examples it is important to be aware that there are limits in Vulkan that expose how much data can be bound at a single time.
-
Input Attributes
-
maxVertexInputAttributes -
maxVertexInputAttributeOffset
-
-
Descriptors
-
maxBoundDescriptorSets -
Per stage limit
-
maxPerStageDescriptorSamplers -
maxPerStageDescriptorUniformBuffers -
maxPerStageDescriptorStorageBuffers -
maxPerStageDescriptorSampledImages -
maxPerStageDescriptorStorageImages -
maxPerStageDescriptorInputAttachments -
Per type limit
-
maxPerStageResources -
maxDescriptorSetSamplers -
maxDescriptorSetUniformBuffers -
maxDescriptorSetUniformBuffersDynamic -
maxDescriptorSetStorageBuffers -
maxDescriptorSetStorageBuffersDynamic -
maxDescriptorSetSampledImages -
maxDescriptorSetStorageImages -
maxDescriptorSetInputAttachments -
VkPhysicalDeviceDescriptorIndexingPropertiesif using Descriptor Indexing -
VkPhysicalDeviceInlineUniformBlockPropertiesEXTif using Inline Uniform Block
-
-
Push Constants
-
maxPushConstantsSize- guaranteed at least128bytes on all devices
-
permalink:/Notes/004-3d-rendering/vulkan/chapters/vertex_input_data_processing.html layout: default ---
35. Vertex Input Data Processing
This chapter is an overview of the Fixed-Function Vertex Processing chapter in the spec to help give a high level understanding of how an application can map data to the vertex shader when using a graphics pipeline.
It is also important to remember that Vulkan is a tool that can be used in different ways. The following are examples for educational purposes of how vertex data can be laid out.
35.1. Binding and Locations
A binding is tied to a position in the vertex buffer from which the vertex shader will start reading data out of during a vkCmdDraw* call. Changing the bindings does not require making any alterations to an app’s vertex shader source code.
As an example, the following code matches the diagram of how bindings work.
// Using the same buffer for both bindings in this example
VkBuffer buffers[] = { vertex_buffer, vertex_buffer };
VkDeviceSize offsets[] = { 8, 0 };
vkCmdBindVertexBuffers(
my_command_buffer, // commandBuffer
0, // firstBinding
2, // bindingCount
buffers, // pBuffers
offsets, // pOffsets
);
The following examples show various ways to set your binding and location values depending on your data input.
35.1.1. Example A - packed data
For the first example, the per-vertex attribute data will look like:
struct Vertex {
float x, y, z;
uint8_t u, v;
};
The pipeline create info code will look roughly like:
const VkVertexInputBindingDescription binding = {
0, // binding
sizeof(Vertex), // stride
VK_VERTEX_INPUT_RATE_VERTEX // inputRate
};
const VkVertexInputAttributeDescription attributes[] = {
{
0, // location
binding.binding, // binding
VK_FORMAT_R32G32B32_SFLOAT, // format
0 // offset
},
{
1, // location
binding.binding, // binding
VK_FORMAT_R8G8_UNORM, // format
3 * sizeof(float) // offset
}
};
const VkPipelineVertexInputStateCreateInfo info = {
1, // vertexBindingDescriptionCount
&binding, // pVertexBindingDescriptions
2, // vertexAttributeDescriptionCount
&attributes[0] // pVertexAttributeDescriptions
};The GLSL code that would consume this could look like
layout(location = 0) in vec3 inPos;
layout(location = 1) in uvec2 inUV;35.1.2. Example B - padding and adjusting offset
This example examines a case where the vertex data is not tightly packed and has extra padding.
struct Vertex {
float x, y, z, pad;
uint8_t u, v;
};The only change needed is to adjust the offset at pipeline creation
1, // location
binding.binding, // binding
VK_FORMAT_R8G8_UNORM, // format
- 3 * sizeof(float) // offset
+ 4 * sizeof(float) // offsetAs this will now set the correct offset for where u and v are read in from.

35.1.3. Example C - non-interleaved
Sometimes data is not interleaved, in this case, you might have the following
float position_data[] = { /*....*/ };
uint8_t uv_data[] = { /*....*/ };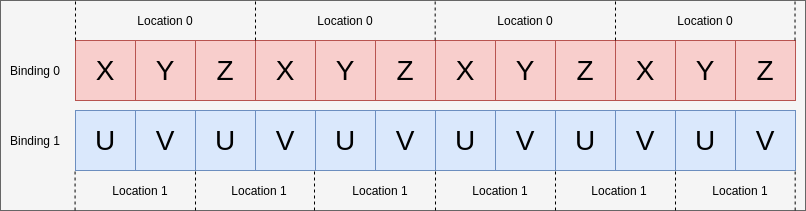
In this case, there will be 2 bindings, but still 2 locations
const VkVertexInputBindingDescription bindings[] = {
{
0, // binding
3 * sizeof(float), // stride
VK_VERTEX_INPUT_RATE_VERTEX // inputRate
},
{
1, // binding
2 * sizeof(uint8_t), // stride
VK_VERTEX_INPUT_RATE_VERTEX // inputRate
}
};
const VkVertexInputAttributeDescription attributes[] = {
{
0, // location
bindings[0].binding, // binding
VK_FORMAT_R32G32B32_SFLOAT, // format
0 // offset
},
{
1, // location
bindings[1].binding, // binding
VK_FORMAT_R8G8_UNORM, // format
0 // offset
}
};
const VkPipelineVertexInputStateCreateInfo info = {
2, // vertexBindingDescriptionCount
&bindings[0], // pVertexBindingDescriptions
2, // vertexAttributeDescriptionCount
&attributes[0] // pVertexAttributeDescriptions
};The GLSL code does not change from Example A
layout(location = 0) in vec3 inPos;
layout(location = 1) in uvec2 inUV;35.1.4. Example D - 2 bindings and 3 locations
This example is to help illustrate that the binding and location are independent of each other.
In this example, the data of the vertices is laid out in two buffers provided in the following format:
struct typeA {
float x, y, z; // position
uint8_t u, v; // UV
};
struct typeB {
float x, y, z; // normal
};
typeA a[] = { /*....*/ };
typeB b[] = { /*....*/ };and the shader being used has the interface of
layout(location = 0) in vec3 inPos;
layout(location = 1) in vec3 inNormal;
layout(location = 2) in uvec2 inUV;The following can still be mapped properly by setting the VkVertexInputBindingDescription and VkVertexInputAttributeDescription accordingly:
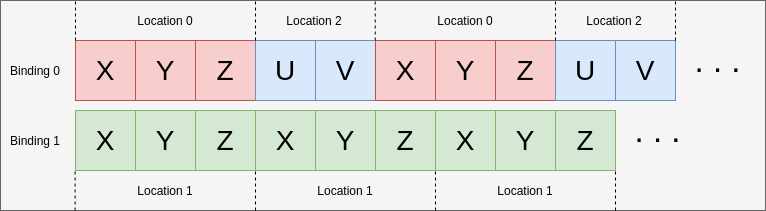
const VkVertexInputBindingDescription bindings[] = {
{
0, // binding
sizeof(typeA), // stride
VK_VERTEX_INPUT_RATE_VERTEX // inputRate
},
{
1, // binding
sizeof(typeB), // stride
VK_VERTEX_INPUT_RATE_VERTEX // inputRate
}
};
const VkVertexInputAttributeDescription attributes[] = {
{
0, // location
bindings[0].binding, // binding
VK_FORMAT_R32G32B32_SFLOAT, // format
0 // offset
},
{
1, // location
bindings[1].binding, // binding
VK_FORMAT_R32G32B32_SFLOAT, // format
0 // offset
},
{
2, // location
bindings[0].binding, // binding
VK_FORMAT_R8G8_UNORM, // format
3 * sizeof(float) // offset
}
};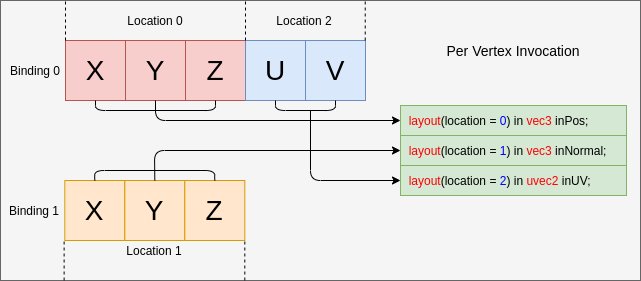
35.2. Example E - understanding input attribute format
The VkVertexInputAttributeDescription::format can be the cause of confusion. The format field just describes the size and type of the data the shader should read in.
The reason for using the VkFormat values is they are well defined and match the input layouts of the vertex shader.
For this example the vertex data is just four floats:
struct Vertex {
float a, b, c, d;
};The data being read will be overlapped from how the format and offset is set
const VkVertexInputBindingDescription binding = {
0, // binding
sizeof(Vertex), // stride
VK_VERTEX_INPUT_RATE_VERTEX // inputRate
};
const VkVertexInputAttributeDescription attributes[] = {
{
0, // location
binding.binding, // binding
VK_FORMAT_R32G32_SFLOAT, // format - Reads in two 32-bit signed floats ('a' and 'b')
0 // offset
},
{
1, // location
binding.binding, // binding
VK_FORMAT_R32G32B32_SFLOAT, // format - Reads in three 32-bit signed floats ('b', 'c', and 'd')
1 * sizeof(float) // offset
}
};When reading in the data in the shader the value will be the same where it overlaps
layout(location = 0) in vec2 in0;
layout(location = 1) in vec2 in1;
// in0.y == in1.x
It is important to notice that in1 is a vec2 while the input attribute is VK_FORMAT_R32G32B32_SFLOAT which doesn’t fully match. According to the spec:
If the vertex shader has fewer components, the extra components are discarded.
So in this case, the last component of location 1 (d) is discarded and would not be read in by the shader.
35.3. Components Assignment
The spec explains more in detail about the Component assignment. The following is a general overview of the topic.
35.3.1. Filling in components
Each location in the VkVertexInputAttributeDescription has 4 components. The example above already showed that extra components from the format are discarded when the shader input has fewer components.
| Note | Example
|
For the opposite case, the spec says:
If the format does not include G, B, or A components, then those are filled with (0,0,1) as needed (using either 1.0f or integer 1 based on the format) for attributes that are not 64-bit data types.
This means the example of
layout(location = 0) in vec3 inPos;
layout(location = 1) in uvec2 inUV;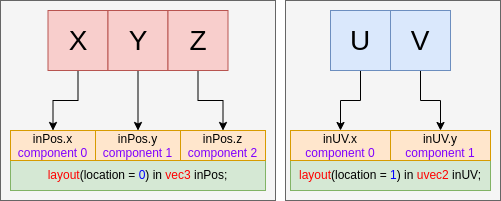
would fill the examples above with the following
layout(location = 0) in vec4 inPos;
layout(location = 1) in uvec4 inUV;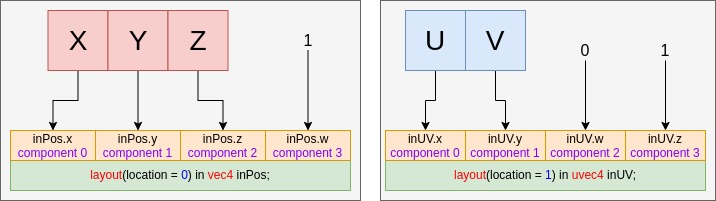
permalink: /Notes/004-3d-rendering/vulkan/chapters/descriptor_dynamic_offset.html ---
36. Descriptor Dynamic Offset
Vulkan offers two types of descriptors that allow adjusting the offset at bind time as defined in the spec.
-
dynamic uniform buffer (
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC) -
dynamic storage buffer (
VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC)
36.1. Example
This example will have buffer of 32 bytes and 16 of the bytes will be set at vkUpdateDescriptorSets time. In this first example, we will not add any dynamic offset.
VkDescriptorSet descriptorSet; // allocated
VkBuffer buffer; // size of 32 bytes
VkDescriptorBufferInfo bufferInfo = {
buffer,
4, // offset
16 // range
};
VkWriteDescriptorSet writeInfo = {
.dstSet = descriptorSet,
.descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC,
.pBufferInfo = bufferInfo
};
vkUpdateDescriptorSets(
1, // descriptorWriteCount,
&writeInfo // pDescriptorWrites,
);
// No dynamic offset
vkCmdBindDescriptorSets(
1, // descriptorSetCount,
&descriptorSet, // pDescriptorSets,
0, // dynamicOffsetCount
NULL // pDynamicOffsets
);Our buffer now currently looks like the following:

Next, a 8 byte dynamic offset will applied at bind time.
uint32_t offsets[1] = { 8 };
vkCmdBindDescriptorSets(
1, // descriptorSetCount,
&descriptorSet, // pDescriptorSets,
1, // dynamicOffsetCount
offsets // pDynamicOffsets
);Our buffer currently looks like the following:

36.2. Example with VK_WHOLE_SIZE
This time the VK_WHOLE_SIZE value will be used for the range. Everything looks the same as the above example except the VkDescriptorBufferInfo::range
VkDescriptorSet descriptorSet; // allocated
VkBuffer buffer; // size of 32 bytes
VkDescriptorBufferInfo info = {
buffer,
4, // offset
VK_WHOLE_SIZE // range
};
VkWriteDescriptorSet writeInfo = {
.dstSet = descriptorSet,
.descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC,
.pBufferInfo = bufferInfo
};
vkUpdateDescriptorSets(
1, // descriptorWriteCount,
&writeInfo // pDescriptorWrites,
);
// No dynamic offset
vkCmdBindDescriptorSets(
1, // descriptorSetCount,
&descriptorSet, // pDescriptorSets,
0, // dynamicOffsetCount
NULL // pDynamicOffsets
);Our buffer currently looks like the following:

This time, if we attempt to apply a dynamic offset it will be met with undefined behavior and the validation layers will give an error
// Invalid
uint32_t offsets[1] = { 8 };
vkCmdBindDescriptorSets(
1, // descriptorSetCount,
&descriptorSet, // pDescriptorSets,
1, // dynamicOffsetCount
offsets // pDynamicOffsets
);This is what it looks like with the invalid dynamic offset
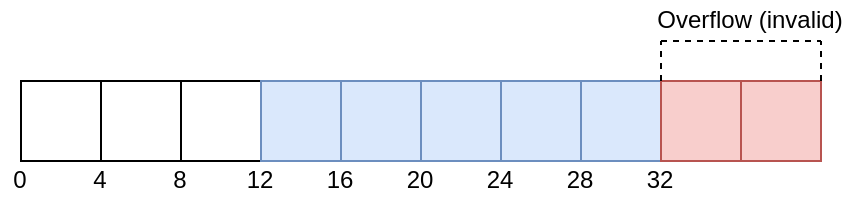
36.3. Limits
It is important to also check the minUniformBufferOffsetAlignment and minStorageBufferOffsetAlignment as both the base offset and dynamic offset must be multiples of these limits.
permalink:/Notes/004-3d-rendering/vulkan/chapters/robustness.html layout: default ---
37. Robustness
37.1. What does robustness mean
When a Vulkan application tries to access (load, store, or perform an atomic on) memory it doesn’t have access to, the implementation must react somehow. In the case where there is no robustness, it is undefined behavior and the implementation is even allowed to terminate the program. If robustness is enabled for the type of memory accessed, then the implementation must behave a certain way as defined by the spec.
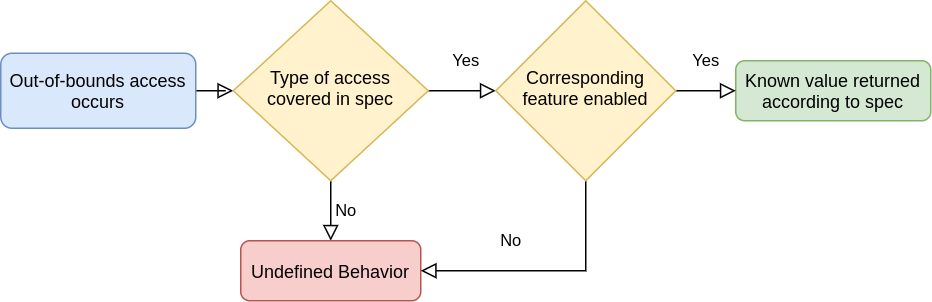
37.2. When to use
The nature of some Vulkan applications requires the ability run shader code that cannot be guaranteed to avoid bad memory accesses. Robustness is needed for these applications.
| Note | Important Turning on robustness may incur a runtime performance cost. Application writers should carefully consider the implications of enabling robustness. |
37.3. What Vulkan provides in core
All Vulkan implementations are required to support the robustBufferAccess feature. The spec describes what is considered out-of-bounds and also how it should be handled. Implementations are given some amount of flexibility for robustBufferAccess. An example would be accessing a vec4(x,y,z,w) where the w value is out-of-bounds as the spec allows the implementation to decide if the x, y, and z are also considered out-of-bounds or not.
If dealing with the update after bind functionality found in VK_EXT_descriptor_indexing (which is core as of Vulkan 1.2) it is important to be aware of the robustBufferAccessUpdateAfterBind which indicates if an implementation can support both robustBufferAccess and the ability to update the descriptor after binding it.
The robustBufferAccess feature has some limitations as it only covers buffers and not images. It also allows out-of-bounds writes and atomics to modify the data of the buffer being accessed. For applications looking for a stronger form of robustness, there is VK_EXT_robustness2.
When images are out-of-bounds core Vulkan provides the guarantee that stores and atomics have no effect on the memory being accessed.
37.4. VK_EXT_image_robustness
37.4.1. robustImageAccess
The robustImageAccess feature in VK_EXT_image_robustness enables out-of-bounds checking against the dimensions of the image view being accessed. If there is an out-of-bounds access to any image it will return (0, 0, 0, 0) or (0, 0, 0, 1).
The robustImageAccess feature provides no guarantees about the values returned for access to an invalid LOD, it is still undefined behavior.
37.5. VK_EXT_robustness2
Some applications, such as those being ported from other APIs such as D3D12, require stricter guarantees than robustBufferAccess and robustImageAccess provide. The VK_EXT_robustness2 extension adds this by exposing 3 new robustness features, described in the following sections. For some implementations these extra guarantees can come at a performance cost. Applications that don’t need the extra robustness are recommended to use robustBufferAccess and/or robustImageAccess instead where possible.
37.5.1. robustBufferAccess2
The robustBufferAccess2 feature can be seen as a superset of robustBufferAccess.
With the feature enabled, it prevents all out-of-bounds writes and atomic from modifying any memory backing buffers. The robustBufferAccess2 feature also enforces the values that must be returned for the various types of buffers when accessed out-of-bounds as described in the spec.
It is important to query the robustUniformBufferAccessSizeAlignment and robustStorageBufferAccessSizeAlignment from VkPhysicalDeviceRobustness2PropertiesEXT as the alignment of where buffers are bound-checked is different between implementations.
37.5.2. robustImageAccess2
The robustImageAccess2 feature can be seen as a superset of robustImageAccess. It builds on the out-of-bounds checking against the dimensions of the image view being accessed, adding stricter requirements on which values may be returned.
With robustImageAccess2 an out-of-bounds access to an R, RG, or RGB format will return (0, 0, 0, 1). For an RGBA format, such as VK_FORMAT_R8G8B8A8_UNORM, it will return (0, 0, 0, 0).
For the case of accessing an image LOD outside the supported range, with robustImageAccess2 enabled, it will be considered out of bounds.
37.5.3. nullDescriptor
Without the nullDescriptor feature enabled, when updating a VkDescriptorSet, all the resources backing it must be non-null, even if the descriptor is statically not used by the shader. This feature allows descriptors to be backed by null resources or views. Loads from a null descriptor return zero values and stores and atomics to a null descriptor are discarded.
The nullDescriptor feature also allows accesses to vertex input bindings where vkCmdBindVertexBuffers::pBuffers is null.
permalink: /Notes/004-3d-rendering/vulkan/chapters/dynamic_state.html layout: default ---
38. Pipeline Dynamic State
| Note |
38.1. Overview
When creating a graphics VkPipeline object the logical flow for setting state is:
// Using viewport state as an example
VkViewport viewport = {0.0, 0.0, 32.0, 32.0, 0.0, 1.0};
// Set value of state
VkPipelineViewportStateCreateInfo viewportStateCreateInfo;
viewportStateCreateInfo.pViewports = &viewport;
viewportStateCreateInfo.viewportCount = 1;
// Create the pipeline with the state value set
VkGraphicsPipelineCreateInfo pipelineCreateInfo;
pipelineCreateInfo.pViewportState = &viewportStateCreateInfo;
vkCreateGraphicsPipelines(pipelineCreateInfo, &pipeline);
vkBeginCommandBuffer();
// Select the pipeline and draw with the state's static value
vkCmdBindPipeline(pipeline);
vkCmdDraw();
vkEndCommandBuffer();When the VkPipeline uses dynamic state, some pipeline information can be omitted at creation time and instead set during recording of the command buffer. The new logical flow is:
// Using viewport state as an example
VkViewport viewport = {0.0, 0.0, 32.0, 32.0, 0.0, 1.0};
VkDynamicState dynamicState = VK_DYNAMIC_STATE_VIEWPORT;
// not used now
VkPipelineViewportStateCreateInfo viewportStateCreateInfo;
viewportStateCreateInfo.pViewports = nullptr;
// still need to say how many viewports will be used here
viewportStateCreateInfo.viewportCount = 1;
// Set the state as being dynamic
VkPipelineDynamicStateCreateInfo dynamicStateCreateInfo;
dynamicStateCreateInfo.dynamicStateCount = 1;
dynamicStateCreateInfo.pDynamicStates = &dynamicState;
// Create the pipeline with state value not known
VkGraphicsPipelineCreateInfo pipelineCreateInfo;
pipelineCreateInfo.pViewportState = &viewportStateCreateInfo;
pipelineCreateInfo.pDynamicState = &dynamicStateCreateInfo;
vkCreateGraphicsPipelines(pipelineCreateInfo, &pipeline);
vkBeginCommandBuffer();
vkCmdBindPipeline(pipeline);
// Set the state for the pipeline at recording time
vkCmdSetViewport(viewport);
vkCmdDraw();
viewport.height = 64.0;
// set a new state value between draws
vkCmdSetViewport(viewport);
vkCmdDraw();
vkEndCommandBuffer();38.2. When to use dynamic state
| Note | Vulkan is a tool, so as with most things, and there is no single answer for this. |
Some implementations might have a performance loss using some certain VkDynamicState state over a static value, but dynamic states might prevent an application from having to create many permutations of pipeline objects which might be a bigger desire for the application.
38.3. What states are dynamic
The full list of possible dynamic states can be found in VkDynamicState.
The VK_EXT_extended_dynamic_state, VK_EXT_extended_dynamic_state2, VK_EXT_vertex_input_dynamic_state, and VK_EXT_color_write_enable extensions were added with the goal to support applications that need to reduce the number of pipeline state objects they compile and bind.
permalink:/Notes/004-3d-rendering/vulkan/chapters/subgroups.html layout: default ---
39. Subgroups
The Vulkan Spec defines subgroups as:
| Note | A set of shader invocations that can synchronize and share data with each other efficiently. In compute shaders, the local workgroup is a superset of the subgroup. |
For many implementations, a subgroup is the groups of invocations that run the same instruction at once. Subgroups allow for a shader writer to work at a finer granularity than a single workgroup.
39.1. Resources
For more detailed information about subgroups there is a great Khronos blog post as well as a presentation from Vulkan Developer Day 2018 (slides and video). GLSL support can be found in the GL_KHR_shader_subgroup extension.
39.2. Subgroup size
It is important to also realize the size of a subgroup can be dynamic for an implementation. Some implementations may dispatch shaders with a varying subgroup size for different subgroups. As a result, they could implicitly split a large subgroup into smaller subgroups or represent a small subgroup as a larger subgroup, some of whose invocations were inactive on launch.
39.2.1. VK_EXT_subgroup_size_control
| Note | Promoted to core in Vulkan 1.3 |
This extension was created due to some implementation having more than one subgroup size and Vulkan originally only exposing a single subgroup size.
For example, if an implementation has both support for subgroups of size 4 and 16 before they would have had to expose only one size, but now can expose both. This allows applications to potentially control the hardware at a finer granularity for implementations that expose multiple subgroup sizes. If an device does not support this extension, it most likely means there is only one supported subgroup size to expose.
39.3. Checking for support
With Vulkan 1.1, all the information for subgroups is found in VkPhysicalDeviceSubgroupProperties
VkPhysicalDeviceSubgroupProperties subgroupProperties;
VkPhysicalDeviceProperties2KHR deviceProperties2;
deviceProperties2.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_PROPERTIES_2;
deviceProperties2.pNext = &subgroupProperties;
vkGetPhysicalDeviceProperties2(physicalDevice, &deviceProperties2);
// Example of checking if supported in fragment shader
if ((subgroupProperties.supportedStages & VK_SHADER_STAGE_FRAGMENT_BIT) != 0) {
// fragment shaders supported
}
// Example of checking if ballot is supported
if ((subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_BALLOT_BIT) != 0) {
// ballot subgroup operations supported
}39.3.1. Guaranteed support
For supported stages, the Vulkan Spec guarantees the following support:
| Note | supportedStages will have the VK_SHADER_STAGE_COMPUTE_BIT bit set if any of the physical device’s queues support VK_QUEUE_COMPUTE_BIT. |
For supported operations, the Vulkan Spec guarantees the following support:
| Note | supportedOperations will have the VK_SUBGROUP_FEATURE_BASIC_BIT bit set if any of the physical device’s queues support VK_QUEUE_GRAPHICS_BIT or VK_QUEUE_COMPUTE_BIT. |
39.4. VK_KHR_shader_subgroup_extended_types
| Note | Promoted to core in Vulkan 1.2 |
This extension allows subgroup operations to use 8-bit integer, 16-bit integer, 64-bit integer, 16-bit floating-point, and vectors of these types in group operations with subgroup scope if the implementation supports the types already.
For example, if an implementation supports 8-bit integers an application can now use the GLSL genI8Type subgroupAdd(genI8Type value); call which will get mapped to OpGroupNonUniformFAdd in SPIR-V.
39.5. VK_EXT_shader_subgroup_ballot and VK_EXT_shader_subgroup_vote
VK_EXT_shader_subgroup_ballot and VK_EXT_shader_subgroup_vote were the original efforts to expose subgroups in Vulkan. If an application is using Vulkan 1.1 or greater, there is no need to use these extensions and should instead use the core API to query for subgroup support.
permalink:/Notes/004-3d-rendering/vulkan/chapters/shader_memory_layout.html layout: default ---
40. Shader Memory Layout
When an implementation accesses memory from an interface, it needs to know how the memory layout. This includes things such as offsets, stride, and alignments. While the Vulkan Spec has a section dedicated to this, it can be hard to parse due to the various extensions that add extra complexity to the spec language. This chapter aims to help explain all the memory layout concepts Vulkan uses with some high level shading language (GLSL) examples.
40.1. Alignment Requirements
Vulkan has 3 alignment requirements that interface objects can be laid out in.
-
extended alignment (also know as
std140) -
base alignment (also know as
std430) -
scalar alignment
The spec language for alignment breaks down the rule for each of the following block member types.
-
scalar (
float,int,char, etc) -
vector (
float2,vec3, ’uvec4' etc) -
matrix
-
array
-
struct
40.2. VK_KHR_uniform_buffer_standard_layout
| Note | Promoted to core in Vulkan 1.2 |
This extension allows the use of std430 memory layout in UBOs. Vulkan Standard Buffer Layout Interface can be found outside this guide. These memory layout changes are only applied to Uniforms as other storage items such as Push Constants and SSBO already allow for std430 style layouts.
One example of when the uniformBufferStandardLayout feature is needed is when an application doesn’t want the array stride for a UBO to be restricted to extended alignment
layout(std140, binding = 0) uniform ubo140 {
float array140[8];
};
layout(std430, binding = 1) uniform ubo430 {
float array430[8];
};Which translates in SPIR-V to
// extended alignment for array is rounded up to multiple of 16
OpDecorate %array140 ArrayStride 16
// base alignment is 4 bytes (OpTypeFloat 32)
// only valid with uniformBufferStandardLayout feature enabled
OpDecorate %array430 ArrayStride 4Make sure to set --uniform-buffer-standard-layout when running the SPIR-V Validator.
40.3. VK_KHR_relaxed_block_layout
| Note | Promoted to core in Vulkan 1.1 There was never a feature bit added for this extension, so all Vulkan 1.1+ devices support relaxed block layout. |
This extension allows implementations to indicate they can support more variation in block Offset decorations. This comes up when using std430 memory layout where a vec3 (which is 12 bytes) is still defined as a 16 byte alignment. With relaxed block layout an application can fit a float on either side of the vec3 and maintain the 16 byte alignment between them.
// SPIR-V offsets WITHOUT relaxed block layout
layout (set = 0, binding = 0) buffer block {
float b; // Offset: 0
vec3 a; // Offset: 16
} ssbo;
// SPIR-V offsets WITH relaxed block layout
layout (set = 0, binding = 0) buffer block {
float b; // Offset: 0
vec3 a; // Offset: 4
} ssbo;VK_KHR_relaxed_block_layout can also be seen as a subset of VK_EXT_scalar_block_layout
| Note | Make sure to set |
| Note | Currently there is no way in GLSL to legally express relaxed block layout, but an developer can use the |
40.4. VK_EXT_scalar_block_layout
| Note | Promoted to core in Vulkan 1.2 |
This extension allows most storage types to be aligned in scalar alignment. A big difference is being able to straddle the 16-byte boundary.
In GLSL this can be used with scalar keyword and extension
#extension GL_EXT_scalar_block_layout : enable
layout (scalar, binding = 0) buffer block { }| Note | Make sure to set |
| Note | The |
40.5. Alignment Examples
The following are some GLSL to SPIR-V examples to help better understand the difference in the alignments supported.
40.5.1. Alignment Example 1
layout(binding = 0) buffer block {
vec2 a[4];
vec4 b;
};Which translates in SPIR-V to
// extended alignment (std140)
OpDecorate %vec2array ArrayStride 16
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 64
// scalar alignment and base alignment (std430)
OpDecorate %vec2array ArrayStride 8
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 3240.5.2. Alignment Example 2
layout(binding = 0) buffer block {
float a;
vec2 b;
vec2 c;
};Which translates in SPIR-V to
// extended alignment (std140) and base alignment (std430)
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 8
OpMemberDecorate %block 2 Offset 16
// scalar alignment
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 4
OpMemberDecorate %block 2 Offset 1240.5.3. Alignment Example 3
layout(binding = 0) buffer block {
vec3 a;
vec2 b;
vec4 c;
};Which translates in SPIR-V to
// extended alignment (std140) and base alignment (std430)
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 16
OpMemberDecorate %block 2 Offset 32
// scalar alignment
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 12
OpMemberDecorate %block 2 Offset 2040.5.4. Alignment Example 4
layout (binding = 0) buffer block {
vec3 a;
vec2 b;
vec2 c;
vec3 d;
};Which translates in SPIR-V to
// extended alignment (std140) and base alignment (std430)
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 16
OpMemberDecorate %block 2 Offset 24
OpMemberDecorate %block 3 Offset 32
// scalar alignment
OpMemberDecorate %block 0 Offset 0
OpMemberDecorate %block 1 Offset 12
OpMemberDecorate %block 2 Offset 20
OpMemberDecorate %block 3 Offset 28permalink: /Notes/004-3d-rendering/vulkan/chapters/atomics.html ---
41. Atomics
The purpose of this chapter is to help users understand the various features Vulkan exposes for atomic operations.
41.1. Variations of Atomics
To better understand the different extensions, it is first important to be aware of the various types of atomics exposed.
-
Type
-
float -
int
-
-
Width
-
16 bit -
32 bit -
64 bit
-
-
Operations
-
loads
-
stores
-
exchange
-
add
-
min
-
max
-
etc.
-
-
Storage Class
-
StorageBufferorUniform(buffer) -
Workgroup(shared memory) -
Image(image or sparse image)
-
41.2. Baseline Support
With Vulkan 1.0 and no extensions, an application is allowed to use 32-bit int type for atomics. This can be used for all supported SPIR-V operations (load, store, exchange, etc). SPIR-V contains some atomic operations that are guarded with the Kernel capability and are not currently allowed in Vulkan.
41.2.1. Atomic Counters
While both GLSL and SPIR-V support the use of atomic counters, Vulkan does not expose the AtomicStorage SPIR-V capability needed to use the AtomicCounter storage class. It was decided that an app can just use OpAtomicIAdd and OpAtomicISub with the value 1 to achieve the same results.
41.2.2. Expanding Atomic support
The current extensions that expose additional support for atomics are:
Each explained in more details below.
41.3. VK_KHR_shader_atomic_int64
| Note | Promoted to core in Vulkan 1.2 |
This extension allows for 64-bit int atomic operations for buffers and shared memory. If the Int64Atomics SPIR-V capability is declared, all supported SPIR-V operations can be used with 64-bit int.
The two feature bits, shaderBufferInt64Atomics and shaderSharedInt64Atomics, are used to query what storage classes are supported for 64-bit int atomics.
-
shaderBufferInt64Atomics- buffers -
shaderSharedInt64Atomics- shared memory
The shaderBufferInt64Atomics is always guaranteed to be supported if using Vulkan 1.2+ or the extension is exposed.
41.4. VK_EXT_shader_image_atomic_int64
This extension allows for 64-bit int atomic operations for images and sparse images. If the Int64Atomics and Int64ImageEXT SPIR-V capability is declared, all supported SPIR-V operations can be used with 64-bit int on images.
41.4.1. Image vs Sparse Image support
This extension exposes both a shaderImageInt64Atomics and sparseImageInt64Atomics feature bit. The sparseImage* feature is an additional feature bit and is only allowed to be used if the shaderImage* bit is enabled as well. Some hardware has a hard time doing atomics on images with sparse resources, therefor the atomic feature is split up to allow sparse images as an additional feature an implementation can expose.
41.5. VK_EXT_shader_atomic_float
This extension allows for float atomic operations for buffers, shared memory, images, and sparse images. Only a subset of operations is supported for float types with this extension.
The extension lists many feature bits. One way to group them is by *Float*Atomics and *Float*AtomicAdd:
-
The
*Float*Atomicsfeatures allow for the use ofOpAtomicStore,OpAtomicLoad, andOpAtomicExchangeforfloattypes.-
Note the
OpAtomicCompareExchange“exchange” operation is not included as the SPIR-V spec only allowsinttypes for it.
-
-
The
*Float*AtomicAddfeatures allow the use of the two extended SPIR-V operationsAtomicFloat32AddEXTandAtomicFloat64AddEXT.
From here the rest of the permutations of features fall into the grouping of 32-bit float support:
-
shaderBufferFloat32*- buffers -
shaderSharedFloat32*- shared memory -
shaderImageFloat32*- images -
sparseImageFloat32*- sparse images
and 64-bit float support:
-
shaderBufferFloat64*- buffers -
shaderSharedFloat64*- shared memory
| Note | OpenGLES OES_shader_image_atomic allowed the use of atomics on |
41.6. VK_EXT_shader_atomic_float2
| Note |
This extension adds 2 additional sets of features missing in VK_EXT_shader_atomic_float
First, it adds 16-bit floats for both buffers and shared memory in the same fashion as found above for VK_EXT_shader_atomic_float.
-
shaderBufferFloat16*- buffers -
shaderSharedFloat16*- shared memory
Second, it adds float support for min and max atomic operations (OpAtomicFMinEXT and OpAtomicFMaxEXT)
For 16-bit float support (with AtomicFloat16MinMaxEXT capability):
-
shaderBufferFloat16AtomicMinMax- buffers -
shaderSharedFloat16AtomicMinMax- shared memory
For 32-bit float support (with AtomicFloat32MinMaxEXT capability):
-
shaderBufferFloat32AtomicMinMax- buffers -
shaderSharedFloat32AtomicMinMax- shared memory -
shaderImageFloat32AtomicMinMax- images -
sparseImageFloat32AtomicMinMax- sparse images
For 64-bit float support (with AtomicFloat64MinMaxEXT capability):
-
shaderBufferFloat64AtomicMinMax- buffers -
shaderSharedFloat64AtomicMinMax- shared memory
permalink: /Notes/004-3d-rendering/vulkan/chapters/common_pitfalls.html ---
42. Common Pitfalls for New Vulkan Developers
This is a short list of assumptions, traps, and anti-patterns in the Vulkan API. It is not a list of “best practices”, rather it covers the common mistakes that developers new to Vulkan could easily make.
42.1. Validation Layers
During development, ensure that the Validation Layers are enabled. They are an invaluable tool for catching mistakes while using the Vulkan API. Parameter checking, object lifetimes, and threading violations all are part of the provided error checks. A way to reassure that they are enabled is to verify if the text “Debug Messenger Added” is in the output stream. More info can be found in the Vulkan SDK layer documentation.
42.2. Vulkan Is a Box of Tools
In Vulkan, most problems can be tackled with multiple methods, each with their own benefits and drawbacks. There is rarely a “perfect” solution and obsessing over finding one is often a fruitless effort. When faced with a problem, try to create an adequate solution that meets the current needs and isn’t overly convoluted. While the specification for Vulkan can be useful, it isn’t the best source for how to use Vulkan in practice. Instead, reference external sources, like this guide, hardware best practice guides, tutorials, and other articles for more in-depth information. Finally, profiling various solutions is an important part of discovering which solution to use.
42.3. Recording Command Buffers
Many early Vulkan tutorials and documents recommended writing a command buffer once and re-using it wherever possible. In practice however re-use rarely has the advertized performance benefit while incurring a non-trivial development burden due to the complexity of implementation. While it may appear counterintuitive, as re-using computed data is a common optimization, managing a scene with objects being added and removed as well as techniques such as frustum culling which vary the draw calls issued on a per frame basis make reusing command buffers a serious design challenge. It requires a caching scheme to manage command buffers and maintaining state for determining if and when re-recording becomes necessary. Instead, prefer to re-record fresh command buffers every frame. If performance is a problem, recording can be multithreaded as well as using secondary command buffers for non-variable draw calls, like post processing.
42.4. Multiple Pipelines
A graphics VkPipeline contains the combination of state needed to perform a draw call. Rendering a scene with different shaders, blending modes, vertex layouts, etc, will require a pipeline for each possibility. Because pipeline creation and swapping them between draw calls have an associated cost, it is a good practice to create and swap pipelines only as needed. However, by using various techniques and features to further reduce creation and swapping beyond the simple cases can be counterproductive, as it adds complexity with no guarantee of benefit. For large engines this may be necessary, but otherwise it is unlikely to be a bottleneck. Using the pipeline cache can further reduce the costs without resorting to more complex schemes.
42.5. Resource Duplication per Swapchain Image
Pipelining frames is a common way to improve performance. By having multiple frames rendering at the same time, each using their own copy of the required resources, it reduces latency by removing resource contention. A simple implementation of this will duplicate the resources needed by each image in the swapchain. The issue is that this leads to assuming rendering resources must be duplicated once for each swapchain image. While practical for some resources, like the command buffers and semaphores used for each frame, the one-to-one duplication with swapchain images isn’t often necessary. Vulkan offers a large amount of flexibility, letting the developer choose what level of duplication is right for their situation. Many resources may only need two copies, for example, uniform buffers or data which is updated once per frame, and others may not need any duplication at all.
42.6. Multiple Queues per Queue Family
Several hardware platforms have more than one VkQueue per queue family. This can be useful by being able to submit work to the same queue family from separate queues. While there can be advantages, it isn’t necessarily better to create or use the extra queues. For specific performance recommendations, refer to hardware vendors' best practices guides.
42.7. Descriptor Sets
Descriptor Sets are designed to facilitate grouping data used in shaders by usage and update frequency. The Vulkan Spec mandates that hardware supports using at least 4 Descriptor Sets at a time, with most hardware supporting at least 8. Therefore there is very little reason not to use more than one where it is sensible.
42.8. Correct API usage practices
While the Validation Layers can catch many types of errors, they are not perfect. Below is a short list of good habits and possible sources of error when encountering odd behavior.
-
Initialize all variables and structs.
-
Use the correct
sTypefor each structure. -
Verify correct
pNextchain usage, nulling it out when not needed. -
There are no default values in Vulkan.
-
Use correct enum,
VkFlag, and bitmask values. -
Consider using a type-safe Vulkan wrapper, eg. Vulkan.hpp for C++
-
Check function return values, eg
VkResult. -
Call cleanup functions where appropriate.
permalink: /Notes/004-3d-rendering/vulkan/chapters/hlsl.html ---
43. HLSL in Vulkan
Vulkan does not directly consume shaders in a human-readable text format, but instead uses SPIR-V as an intermediate representation. This opens the option to use shader languages other than e.g. GLSL, as long as they can target the Vulkan SPIR-V environment.
One such language is the High Level Shading Language (HLSL) by Microsoft, used by DirectX. Thanks to recent additions to Vulkan 1.2 it is now considered a first class shading language for Vulkan that can be used just as easily as GLSL.
With a few exceptions, all Vulkan features and shader stages available with GLSL can be used with HLSL too, including recent Vulkan additions like hardware accelerated ray tracing. On the other hand, HLSL to SPIR-V supports Vulkan exclusive features that are not (yet) available in DirectX.
43.1. From the application’s point-of-view
From the application’s point-of-view, using HLSL is exactly the same as using GLSL. As the application always consumes shaders in the SPIR-V format, the only difference is in the tooling to generate the SPIR-V shaders from the desired shading language.
43.2. HLSL to SPIR-V feature mapping manual
A great starting point on using HLSL in Vulkan via SPIR-V is the HLSL to SPIR-V feature mapping manual. It contains detailed information on semantics, syntax, supported features and extensions and much more and is a must-read. The decoder ring also has a translation table for concepts and terms used in Vulkan an DirectX.
43.3. The Vulkan HLSL namespace
To make HLSL compatible with Vulkan, an implicit namespace has been introduced that provides an interface for for Vulkan-specific features.
43.4. Syntax comparison
Similar to regular programming languages, HLSL and GLSL differ in their syntax. While GLSL is more procedural (like C), HLSL is more object-oriented (like C++).
Here is the same shader written in both languages to give quick comparison on how they basically differ, including the aforementioned namespace that e.g. adds explicit locations:
43.4.1. GLSL
#version 450
layout (location = 0) in vec3 inPosition;
layout (location = 1) in vec3 inColor;
layout (binding = 0) uniform UBO
{
mat4 projectionMatrix;
mat4 modelMatrix;
mat4 viewMatrix;
} ubo;
layout (location = 0) out vec3 outColor;
void main()
{
outColor = inColor * float(gl_VertexIndex);
gl_Position = ubo.projectionMatrix * ubo.viewMatrix * ubo.modelMatrix * vec4(inPosition.xyz, 1.0);
}43.4.2. HLSL
struct VSInput
{
[[vk::location(0)]] float3 Position : POSITION0;
[[vk::location(1)]] float3 Color : COLOR0;
};
struct UBO
{
float4x4 projectionMatrix;
float4x4 modelMatrix;
float4x4 viewMatrix;
};
cbuffer ubo : register(b0, space0) { UBO ubo; }
struct VSOutput
{
float4 Pos : SV_POSITION;
[[vk::location(0)]] float3 Color : COLOR0;
};
VSOutput main(VSInput input, uint VertexIndex : SV_VertexID)
{
VSOutput output = (VSOutput)0;
output.Color = input.Color * float(VertexIndex);
output.Position = mul(ubo.projectionMatrix, mul(ubo.viewMatrix, mul(ubo.modelMatrix, float4(input.Position.xyz, 1.0))));
return output;
}Aside from the syntax differences, built-ins use HLSL names. E.g. gl_vertex becomes VertexIndex in HLSL. A list of GLSL to HLSL built-in mappings can be found here.
43.5. DirectXShaderCompiler (DXC)
As is the case with GLSL to SPIR-V, to use HLSL with Vulkan, a shader compiler is required. Whereas glslang is the reference GLSL to SPIR-V compiler, the DirectXShaderCompiler (DXC) is the reference HLSL to SPIR-V compiler. Thanks to open source contributions, the SPIR-V backend of DXC is now supported and enabled in official release builds and can be used out-of-the box. While other shader compiling tools like glslang also offer HLSL support, DXC has the most complete and up-to-date support and is the recommended way of generating SPIR-V from HLSL.
43.5.1. Where to get
The LunarG Vulkan SDK includes pre-compiled DXC binaries, libraries and headers to get you started. If you’re looking for the latest releases, check the official DXC repository.
43.5.2. Offline compilation using the stand-alone compiler
Compiling a shader offline via the pre-compiled dxc binary is similar to compiling with glslang:
dxc.exe -spirv -T vs_6_0 -E main .\triangle.vert -Fo .\triangle.vert.spv-T selects the profile to compile the shader against (vs_6_0 = Vertex shader model 6, ps_6_0 = Pixel/fragment shader model 6, etc.).
-E selects the main entry point for the shader.
Extensions are implicitly enabled based on feature usage, but can also be explicitly specified:
dxc.exe -spirv -T vs_6_1 -E main .\input.vert -Fo .\output.vert.spv -fspv-extension=SPV_EXT_descriptor_indexingThe resulting SPIR-V can then be directly loaded, same as SPIR-V generated from GLSL.
43.5.3. Runtime compilation using the library
DXC can also be integrated into a Vulkan application using the DirectX Compiler API. This allows for runtime compilation of shaders. Doing so requires you to include the dxcapi.h header and link against the dxcompiler library. The easiest way is using the dynamic library and distributing it with your application (e.g. dxcompiler.dll on Windows).
Compiling HLSL to SPIR-V at runtime then is pretty straight-forward:
#include "include/dxc/dxcapi.h"
...
HRESULT hres;
// Initialize DXC library
CComPtr<IDxcLibrary> library;
hres = DxcCreateInstance(CLSID_DxcLibrary, IID_PPV_ARGS(&library));
if (FAILED(hres)) {
throw std::runtime_error("Could not init DXC Library");
}
// Initialize the DXC compiler
CComPtr<IDxcCompiler> compiler;
hres = DxcCreateInstance(CLSID_DxcCompiler, IID_PPV_ARGS(&compiler));
if (FAILED(hres)) {
throw std::runtime_error("Could not init DXC Compiler");
}
// Load the HLSL text shader from disk
uint32_t codePage = CP_UTF8;
CComPtr<IDxcBlobEncoding> sourceBlob;
hres = library->CreateBlobFromFile(filename.c_str(), &codePage, &sourceBlob);
if (FAILED(hres)) {
throw std::runtime_error("Could not load shader file");
}
// Set up arguments to be passed to the shader compiler
// Tell the compiler to output SPIR-V
std::vector<LPCWSTR> arguments;
arguments.push_back(L"-spirv");
// Select target profile based on shader file extension
LPCWSTR targetProfile{};
size_t idx = filename.rfind('.');
if (idx != std::string::npos) {
std::wstring extension = filename.substr(idx + 1);
if (extension == L"vert") {
targetProfile = L"vs_6_1";
}
if (extension == L"frag") {
targetProfile = L"ps_6_1";
}
// Mapping for other file types go here (cs_x_y, lib_x_y, etc.)
}
// Compile shader
CComPtr<IDxcOperationResult> resultOp;
hres = compiler->Compile(
sourceBlob,
nullptr,
L"main",
targetProfile,
arguments.data(),
(uint32_t)arguments.size(),
nullptr,
0,
nullptr,
&resultOp);
if (SUCCEEDED(hres)) {
resultOp->GetStatus(&hres);
}
// Output error if compilation failed
if (FAILED(hres) && (resultOp)) {
CComPtr<IDxcBlobEncoding> errorBlob;
hres = resultOp->GetErrorBuffer(&errorBlob);
if (SUCCEEDED(hres) && errorBlob) {
std::cerr << "Shader compilation failed :\n\n" << (const char*)errorBlob->GetBufferPointer();
throw std::runtime_error("Compilation failed");
}
}
// Get compilation result
CComPtr<IDxcBlob> code;
resultOp->GetResult(&code);
// Create a Vulkan shader module from the compilation result
VkShaderModuleCreateInfo shaderModuleCI{};
shaderModuleCI.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
shaderModuleCI.codeSize = code->GetBufferSize();
shaderModuleCI.pCode = (uint32_t*)code->GetBufferPointer();
VkShaderModule shaderModule;
vkCreateShaderModule(device, &shaderModuleCI, nullptr, &shaderModule);43.5.4. Vulkan shader stage to HLSL target shader profile mapping
When compiling HLSL with DXC you need to select a target shader profile. The name for a profile consists of the shader type and the desired shader model.
| Vulkan shader stage | HLSL target shader profile | Remarks |
|---|---|---|
|
| |
|
| Hull shader in HLSL terminology |
|
| Domain shader in HLSL terminology |
|
| |
|
| Pixel shader in HLSL terminology |
|
| |
|
| All raytracing related shaders are built using the |
|
| Amplification shader in HLSL terminology. Must use at least shader model 6.5 (e.g. |
|
| Must use at least shader model 6.5 (e.g. |
So if you for example you want to compile a compute shader targeting shader model 6.6 features, the target shader profile would be cs_6_6. For a ray tracing any hit shader it would be lib_6_3.
43.6. Shader model coverage
DirectX and HLSL use a fixed shader model notion to describe the supported feature set. This is different from Vulkan and SPIR-V’s flexible extension based way of adding features to shaders. The following table tries to list Vulkan’s coverage for the HLSL shader models without guarantee of completeness:
| Shader Model | Supported | Remarks |
|---|---|---|
Shader Model 5.1 and below | ✔ | Excluding features without Vulkan equivalent |
✔ | Wave intrinsics, 64-bit integers | |
✔ | SV_ViewID, SV_Barycentrics | |
✔ | 16-bit types, Denorm mode | |
✔ | Hardware accelerated ray tracing | |
✔ | Shader integer dot product, SV_ShadingRate | |
❌ (partially) | DXR1.1 (KHR ray tracing), Mesh and Amplification shaders, additional Wave intrinsics | |
❌ (partially) | VK_NV_compute_shader_derivatives, VK_KHR_shader_atomic_int64 |
44. When and Why to use Extensions
| Note | These are supplemental references for the various Vulkan Extensions. Please consult the Vulkan Spec for further details on any extension |
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/cleanup.html layout: default ---
45. Cleanup Extensions
| Note | These are extensions that are unofficially called “cleanup extension”. The Vulkan Guide defines them as cleanup extensions due to their nature of only adding a small bit of functionality or being very simple, self-explanatory extensions in terms of their purpose. |
45.1. VK_KHR_driver_properties
| Note | Promoted to core in Vulkan 1.2 |
This extension adds more information to query about each implementation. The VkDriverId will be a registered vendor’s ID for the implementation. The VkConformanceVersion displays which version of the Vulkan Conformance Test Suite the implementation passed.
45.2. VK_EXT_host_query_reset
| Note | Promoted to core in Vulkan 1.2 |
This extension allows an application to call vkResetQueryPool from the host instead of needing to setup logic to submit vkCmdResetQueryPool since this is mainly just a quick write to memory for most implementations.
45.3. VK_KHR_separate_depth_stencil_layouts
| Note | Promoted to core in Vulkan 1.2 |
This extension allows an application when using a depth/stencil format to do an image translation on each the depth and stencil separately. Starting in Vulkan 1.2 this functionality is required for all implementations.
45.4. VK_KHR_depth_stencil_resolve
| Note | Promoted to core in Vulkan 1.2 |
This extension adds support for automatically resolving multisampled depth/stencil attachments in a subpass in a similar manner as for color attachments.
45.5. VK_EXT_separate_stencil_usage
| Note | Promoted to core in Vulkan 1.2 |
There are formats that express both the usage of depth and stencil, but there was no way to list a different usage for them. The VkImageStencilUsageCreateInfo now lets an application pass in a separate VkImageUsageFlags for the stencil usage of an image. The depth usage is the original usage passed into VkImageCreateInfo::usage and without using VkImageStencilUsageCreateInfo the stencil usage will be the same as well.
A good use case of this is when using the VK_KHR_image_format_list extension. This provides a way for the application to more explicitly describe the possible image views of their VkImage at creation time. This allows some implementations to possibly do implementation dependent optimization depending on the usages set.
45.6. VK_KHR_dedicated_allocation
| Note | Promoted to core in Vulkan 1.1 |
Normally applications allocate large chunks for VkDeviceMemory and then suballocate to various buffers and images. There are times where it might be better to have a dedicated allocation for VkImage or VkBuffer. An application can pass VkMemoryDedicatedRequirements into vkGetBufferMemoryRequirements2 or vkGetImageMemoryRequirements2 to find out if a dedicated allocation is preferred or required. When dealing with external memory it will often require a dedicated allocation.
45.7. VK_EXT_sampler_filter_minmax
| Note | Promoted to core in Vulkan 1.2 |
By default, Vulkan samplers using linear filtering return a filtered texel value produced by computing a weighted average of a collection of texels in the neighborhood of the texture coordinate provided. This extension provides a new sampler parameter which allows applications to produce a filtered texel value by computing a component-wise minimum (VK_SAMPLER_REDUCTION_MODE_MIN) or maximum (VK_SAMPLER_REDUCTION_MODE_MAX) of the texels that would normally be averaged. This is similar to GL EXT_texture_filter_minmax.
45.8. VK_KHR_sampler_mirror_clamp_to_edge
| Note | Promoted to core in Vulkan 1.2 |
This extension adds a new sampler address mode (VK_SAMPLER_ADDRESS_MODE_MIRROR_CLAMP_TO_EDGE) that effectively uses a texture map twice as large as the original image in which the additional half of the new image is a mirror image of the original image. This new mode relaxes the need to generate images whose opposite edges match by using the original image to generate a matching “mirror image”. This mode allows the texture to be mirrored only once in the negative s, t, and r directions.
45.9. VK_EXT_4444_formats and VK_EXT_ycbcr_2plane_444_formats
| Note | Promoted to core in Vulkan 1.3 |
These extensions add new VkFormat that were not originally in the spec
45.10. VK_KHR_format_feature_flags2
| Note | Promoted to core in Vulkan 1.3 |
This extension adds a new VkFormatFeatureFlagBits2KHR 64bits format feature flag type to extend the existing VkFormatFeatureFlagBits which is limited to 31 flags.
45.11. VK_EXT_rgba10x6_formats
This extension adds an exception for VK_FORMAT_R10X6G10X6B10X6A10X6_UNORM_4PACK16 in the validation layers to allow being able to render to the format.
45.12. Maintenance Extensions
The maintenance extensions add a collection of minor features that were intentionally left out or overlooked from the original Vulkan 1.0 release.
Currently, there are 4 maintenance extensions. The first 3 were bundled in Vulkan 1.1 as core. All the details for each are well defined in the extension appendix page.
-
VK_KHR_maintenance1 - core in Vulkan 1.1
-
VK_KHR_maintenance2 - core in Vulkan 1.1
-
VK_KHR_maintenance3 - core in Vulkan 1.1
-
VK_KHR_maintenance4 - core in Vulkan 1.3
45.13. pNext Expansions
There have been a few times where the Vulkan Working Group realized that some structs in the original 1.0 Vulkan spec were missing the ability to be extended properly due to missing sType/pNext.
Keeping backward compatibility between versions is very important, so the best solution was to create an extension to amend the mistake. These extensions are mainly new structs, but also need to create new function entry points to make use of the new structs.
The current list of extensions that fit this category are:
-
VK_KHR_get_memory_requirements2-
Added to core in Vulkan 1.1
-
-
VK_KHR_get_physical_device_properties2-
Added to core in Vulkan 1.1
-
-
VK_KHR_bind_memory2-
Added to core in Vulkan 1.1
-
-
VK_KHR_create_renderpass2-
Added to core in Vulkan 1.2
-
-
VK_KHR_copy_commands2-
Added to core in Vulkan 1.3
-
All of these are very simple extensions and were promoted to core in their respective versions to make it easier to use without having to query for their support.
| Note |
|
45.13.1. Example
Using VK_KHR_bind_memory2 as an example, instead of using the standard vkBindImageMemory
// VkImage images[3]
// VkDeviceMemory memories[2];
vkBindImageMemory(myDevice, images[0], memories[0], 0);
vkBindImageMemory(myDevice, images[1], memories[0], 64);
vkBindImageMemory(myDevice, images[2], memories[1], 0);They can now be batched together
// VkImage images[3];
// VkDeviceMemory memories[2];
VkBindImageMemoryInfo infos[3];
infos[0] = {VK_STRUCTURE_TYPE_BIND_IMAGE_MEMORY_INFO, NULL, images[0], memories[0], 0};
infos[1] = {VK_STRUCTURE_TYPE_BIND_IMAGE_MEMORY_INFO, NULL, images[1], memories[0], 64};
infos[2] = {VK_STRUCTURE_TYPE_BIND_IMAGE_MEMORY_INFO, NULL, images[2], memories[1], 0};
vkBindImageMemory2(myDevice, 3, infos);Some extensions such as VK_KHR_sampler_ycbcr_conversion expose structs that can be passed into the pNext
VkBindImagePlaneMemoryInfo plane_info[2];
plane_info[0] = {VK_STRUCTURE_TYPE_BIND_IMAGE_PLANE_MEMORY_INFO, NULL, VK_IMAGE_ASPECT_PLANE_0_BIT};
plane_info[1] = {VK_STRUCTURE_TYPE_BIND_IMAGE_PLANE_MEMORY_INFO, NULL, VK_IMAGE_ASPECT_PLANE_1_BIT};
// Can now pass other extensions structs into the pNext missing from vkBindImagemMemory()
VkBindImageMemoryInfo infos[2];
infos[0] = {VK_STRUCTURE_TYPE_BIND_IMAGE_MEMORY_INFO, &plane_info[0], image, memories[0], 0};
infos[1] = {VK_STRUCTURE_TYPE_BIND_IMAGE_MEMORY_INFO, &plane_info[1], image, memories[1], 0};
vkBindImageMemory2(myDevice, 2, infos);45.13.2. It is fine to not use these
Unless an application need to make use of one of the extensions that rely on the above extensions, it is normally ok to use the original function/structs still.
One possible way to handle this is as followed:
void HandleVkBindImageMemoryInfo(const VkBindImageMemoryInfo* info) {
// ...
}
//
// Entry points into tool/implementation
//
void vkBindImageMemory(VkDevice device,
VkImage image,
VkDeviceMemory memory,
VkDeviceSize memoryOffset)
{
VkBindImageMemoryInfo info;
// original call doesn't have a pNext or sType
info.sType = VK_STRUCTURE_TYPE_BIND_IMAGE_MEMORY_INFO;
info.pNext = nullptr;
// Match the rest of struct the same
info.image = image;
info.memory = memory;
info.memoryOffset = memoryOffset;
HandleVkBindImageMemoryInfo(&info);
}
void vkBindImageMemory2(VkDevice device,
uint32_t bindInfoCount, const
VkBindImageMemoryInfo* pBindInfos)
{
for (uint32_t i = 0; i < bindInfoCount; i++) {
HandleVkBindImageMemoryInfo(pBindInfos[i]);
}
}permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/device_groups.html layout: default ---
46. Device Groups
| Note | Promoted to core in Vulkan 1.1 |
Device groups are a way to have multiple physical devices (single-vendor) represented as a single logical device. If for example, an application have two of the same GPU, connected by some vendor-provided bridge interface, in a single system, one approach is to create two logical devices in Vulkan. The issue here is that there are limitations on what can be shared and synchronized between two VkDevice objects which is not a bad thing, but there are use cases where an application might want to combine the memory between two GPUs. Device Groups were designed for this use case by having an application create “sub-devices” to a single VkDevice. With device groups, objects like VkCommandBuffers and VkQueue are not tied to a single “sub-device” but instead, the driver will manage which physical device to run it on. Another usage of device groups is an alternative frame presenting system where every frame is displayed by a different “sub-device”.
There are two extensions, VK_KHR_device_group and VK_KHR_device_group_creation. The reason for two separate extensions is that extensions are either “instance level extensions” or “device level extensions”. Since device groups need to interact with instance level calls as well as device level calls, two extensions were created. There is also a matching SPV_KHR_device_group extension adding the DeviceGroup scope and a new DeviceIndex built-in type to shaders that allow shaders to control what to do for each logical device. If using GLSL there is also a GL_EXT_device_group extension that introduces a highp int gl_DeviceIndex; built-in variable for all shader types.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/external.html layout: default ---
47. External Memory and Synchronization
Sometimes not everything an application does related to the GPU is done in Vulkan. There are various situations where memory is written or read outside the scope of Vulkan. To support these use cases a set of external memory and synchronization functions was created
The list of extensions involved are:
-
VK_KHR_external_fence-
Promoted to core in 1.1
-
-
VK_KHR_external_fence_capabilities-
Promoted to core in 1.1
-
-
VK_KHR_external_memory-
Promoted to core in 1.1
-
-
VK_KHR_external_memory_capabilities-
Promoted to core in 1.1
-
-
VK_KHR_external_semaphore-
Promoted to core in 1.1
-
-
VK_KHR_external_semaphore_capabilities-
Promoted to core in 1.1
-
-
VK_KHR_external_fence_fd -
VK_KHR_external_fence_win32 -
VK_KHR_external_memory_fd -
VK_KHR_external_memory_win32 -
VK_KHR_external_semaphore_fd -
VK_KHR_external_semaphore_win32 -
VK_ANDROID_external_memory_android_hardware_buffer
This seems like a lot so let’s break it down little by little.
47.1. Capabilities
The VK_KHR_external_fence_capabilities, VK_KHR_external_semaphore_capabilities, and VK_KHR_external_memory_capabilities are simply just ways to query information about what external support an implementation provides.
47.2. Memory vs Synchronization
There is a set of extensions to handle the importing/exporting of just the memory itself. The other set extensions are for the synchronization primitives (VkFence and VkSemaphore) used to control internal Vulkan commands. It is common practice that for each piece of memory imported/exported there is also a matching fence/semaphore to manage the memory access.
47.2.1. Memory
The VK_KHR_external_memory extension is mainly to provide the VkExternalMemoryHandleTypeFlagBits enum which describes the type of memory being used externally.
There are currently 3 supported ways to import/export memory
-
VK_KHR_external_memory_fdfor memory in a POSIX file descriptor -
VK_KHR_external_memory_win32for memory in a Windows handle -
VK_ANDROID_external_memory_android_hardware_bufferfor memory in a AHardwareBuffer
Each of these methods has their own detailed descriptions about limitations, requirements, ownership, etc.
Importing Memory
To import memory, there is a VkImport*Info struct provided by the given external memory extension. This is passed into vkAllocateMemory where Vulkan will now have a VkDeviceMemory handle that maps to the imported memory.
Exporting Memory
To export memory, there is a VkGetMemory* function provided by the given external memory extension. This function will take in a VkDeviceMemory handle and then map that to the extension exposed object.
47.2.2. Synchronization
External synchronization can be used in Vulkan for both VkFence and VkSemaphores. There is almost no difference between the two with regards to how it is used to import and export them.
The VK_KHR_external_fence and VK_KHR_external_semaphore extension both expose a Vk*ImportFlagBits enum and VkExport*CreateInfo struct to describe the type a synchronization being imported/exported.
There are currently 2 supported ways to import/export synchronization
-
VK_KHR_external_fence_fd/VK_KHR_external_semaphore_fd -
VK_KHR_external_fence_win32/VK_KHR_external_semaphore_win32
Each extension explains how it manages ownership of the synchronization primitives.
Importing and Exporting Synchronization Primitives
There is a VkImport* function for importing and a VkGet* function for exporting. These both take the VkFence/VkSemaphores handle passed in along with the extension’s method of defining the external synchronization object.
47.3. Example
Here is a simple diagram showing the timeline of events between Vulkan and some other API talking to the GPU. This is used to represent a common use case for these external memory and synchronization extensions.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/ray_tracing.html layout: default ---
48. Ray Tracing
A set of five interrelated extensions provide ray tracing support in the Vulkan API.
Additional SPIR-V and GLSL extensions also expose the necessary programmable functionality for shaders:
| Note | Many ray tracing applications require large contiguous memory allocations. Due to the limited size of the address space, this can prove challenging on 32-bit systems. Whilst implementations are free to expose ray tracing extensions on 32-bit systems, applications may encounter intermittent memory-related issues such as allocation failures due to fragmentation. Additionally, some implementations may opt not to expose ray tracing extensions on 32-bit drivers. |
48.1. VK_KHR_acceleration_structure
Acceleration structures are an implementation-dependent opaque representation of geometric objects, which are used for ray tracing. By building objects into acceleration structures, ray tracing can be performed against a known data layout, and in an efficient manner. The VK_KHR_acceleration_structure extension introduces functionality to build and copy acceleration structures, along with functionality to support serialization to/from memory.
Acceleration structures are required for both ray pipelines (VK_KHR_ray_tracing_pipeline) and ray queries (VK_KHR_ray_query).
To create an acceleration structure:
-
Populate an instance of
VkAccelerationStructureBuildGeometryInfoKHRwith the acceleration structure type, geometry types, counts, and maximum sizes. The geometry data does not need to be populated at this point. -
Call
vkGetAccelerationStructureBuildSizesKHRto get the memory size requirements to perform a build. -
Allocate buffers of sufficient size to hold the acceleration structure (
VkAccelerationStructureBuildSizesKHR::accelerationStructureSize) and build scratch buffer (VkAccelerationStructureBuildSizesKHR::buildScratchSize) -
Call
vkCreateAccelerationStructureKHRto create an acceleration structure at a specified location within a buffer -
Call
vkCmdBuildAccelerationStructuresKHRto build the acceleration structure. The previously populatedVkAccelerationStructureBuildGeometryInfoKHRshould be used as a parameter here, along with the destination acceleration structure object, build scratch buffer, and geometry data pointers (for vertices, indices and transforms)
48.2. VK_KHR_ray_tracing_pipeline
The VK_KHR_ray_tracing_pipeline extension introduces ray tracing pipelines. This new form of rendering pipeline is independent of the traditional rasterization pipeline. Ray tracing pipelines utilize a dedicated set of shader stages, distinct from the traditional vertex/geometry/fragment stages. Ray tracing pipelines also utilize dedicated commands to submit rendering work (vkCmdTraceRaysKHR and vkCmdTraceRaysIndirectKHR). These commands can be regarded as somewhat analagous to the drawing commands in traditional rasterization pipelines (vkCmdDraw and vkCmdDrawIndirect).
To trace rays:
-
Bind a ray tracing pipeline using
vkCmdBindPipelinewithVK_PIPELINE_BIND_POINT_RAY_TRACING_KHR -
Call
vkCmdTraceRaysKHRorvkCmdTraceRaysIndirectKHR
Ray tracing pipelines introduce several new shader domains. These are described below:

-
Ray generation shader represents the starting point for ray tracing. The ray tracing commands (
vkCmdTraceRaysKHRandvkCmdTraceRaysIndirectKHR) launch a grid of shader invocations, similar to compute shaders. A ray generation shader constructs rays and begins tracing via the invocation of traceRayEXT(). Additionally, it processes the results from the hit group. -
Closest hit shaders are executed when the ray intersects the closest geometry. An application can support any number of closest hit shaders. They are typically used for carrying out lighting calculations and can recursively trace additional rays.
-
Miss shaders are executed instead of a closest hit shader when a ray does not intersect any geometry during traversal. A common use for a miss shader is to sample an environment map.
-
The built-in intersection test is a ray-triangle test. Intersection shaders allow for custom intersection handling.
-
Similar to the closest hit shader, any-hit shaders are executed after an intersection is reported. The difference is that an any-hit shader are be invoked for any intersection in the ray interval defined by [tmin, tmax] and not the closest one to the origin of the ray. The any-hit shader is used to filter an intersection and therefore is often used to implement alpha-testing.
48.3. VK_KHR_ray_query
The VK_KHR_ray_query extension provides support for tracing rays from all shader types, including graphics, compute, and ray tracing pipelines.
Ray query requires that ray traversal code is explicitly included within the shader. This differs from ray tracing pipelines, where ray generation, intersection testing and handling of ray-geometry hits are represented as separate shader stages. Consequently, whilst ray query allows rays to be traced from a wider range of shader stages, it also restricts the range of optimizations that a Vulkan implementation might apply to the scheduling and tracing of rays.
The extension does not introduce additional API entry-points. It simply provides API support for the related SPIR-V and GLSL extensions (SPV_KHR_ray_query and GLSL_EXT_ray_query).
The functionality provided by VK_KHR_ray_query is complementary to that provided by VK_KHR_ray_tracing_pipeline, and the two extensions can be used together.
rayQueryEXT rq;
rayQueryInitializeEXT(rq, accStruct, gl_RayFlagsNoneEXT, 0, origin, tMin, direction, tMax);
while(rayQueryProceedEXT(rq)) {
if (rayQueryGetIntersectionTypeEXT(rq, false) == gl_RayQueryCandidateIntersectionTriangleEXT) {
//...
rayQueryConfirmIntersectionEXT(rq);
}
}
if (rayQueryGetIntersectionTypeEXT(rq, true) == gl_RayQueryCommittedIntersectionNoneEXT) {
//...
}48.4. VK_KHR_pipeline_library
VK_KHR_pipeline_library introduces pipeline libraries. A pipeline library is a special pipeline that was created using the VK_PIPELINE_CREATE_LIBRARY_BIT_KHR and cannot be bound and used directly. Instead, these are pipelines that represent a collection of shaders, shader groups and related state which can be linked into other pipelines.
VK_KHR_pipeline_library does not introduce any new API functions directly, or define how to create a pipeline library. Instead, this functionality is left to other extensions which make use of the functionality provided by VK_KHR_pipeline_library. Currently, the only example of this is VK_KHR_ray_tracing_pipeline. VK_KHR_pipeline_library was defined as a separate extension to allow for the possibility of using the same functionality in other extensions in the future without introducing a dependency on the ray tracing extensions.
To create a ray tracing pipeline library:
-
Set
VK_PIPELINE_CREATE_LIBRARY_BIT_KHRinVkRayTracingPipelineCreateInfoKHR::flagswhen callingvkCreateRayTracingPipelinesKHR
To link ray tracing pipeline libraries into a full pipeline:
-
Set
VkRayTracingPipelineCreateInfoKHR::pLibraryInfoto point to an instance ofVkPipelineLibraryCreateInfoKHR -
Populate
VkPipelineLibraryCreateInfoKHR::pLibrarieswith the pipeline libraries to be used as inputs to linking, and setVkPipelineLibraryCreateInfoKHR::libraryCountto the appropriate value
48.5. VK_KHR_deferred_host_operations
VK_KHR_deferred_host_operations introduces a mechanism for distributing expensive CPU tasks across multiple threads. Rather than introduce a thread pool into Vulkan drivers, VK_KHR_deferred_host_operations is designed to allow an application to create and manage the threads.
As with VK_KHR_pipeline_library, VK_KHR_deferred_host_operations was defined as a separate extension to allow for the possibility of using the same functionality in other extensions in the future without introducing a dependency on the ray tracing extensions.
Only operations that are specifically noted as supporting deferral may be deferred. Currently the only operations which support deferral are vkCreateRayTracingPipelinesKHR, vkBuildAccelerationStructuresKHR, vkCopyAccelerationStructureKHR, vkCopyMemoryToAccelerationStructureKHR, and vkCopyAccelerationStructureToMemoryKHR
To request that an operation is deferred:
-
Create a
VkDeferredOperationKHRobject by callingvkCreateDeferredOperationKHR -
Call the operation that you wish to be deferred, passing the
VkDeferredOperationKHRas a parameter. -
Check the
VkResultreturned by the above operation:-
VK_OPERATION_DEFERRED_KHRindicates that the operation was successfully deferred -
VK_OPERATION_NOT_DEFERRED_KHRindicates that the operation successfully completed immediately -
Any error value indicates that an error occurred
-
To join a thread to a deferred operation, and contribute CPU time to progressing the operation:
-
Call
vkDeferredOperationJoinKHRfrom each thread that you wish to participate in the operation -
Check the
VkResultreturned byvkDeferredOperationJoinKHR:-
VK_SUCCESSindicates that the operation is complete -
VK_THREAD_DONE_KHRindicates that there is no more work to assign to the calling thread, but that other threads may still have some additional work to complete. The current thread should not attempt to re-join by callingvkDeferredOperationJoinKHRagain -
VK_THREAD_IDLE_KHRindicates that there is temporarily no work to assign to the calling thread, but that additional work may become available in the future. The current thread may perform some other useful work on the calling thread, and re-joining by callingvkDeferredOperationJoinKHRagain later may prove beneficial
-
After an operation has completed (i.e. vkDeferredOperationJoinKHR has returned VK_SUCCESS), call vkGetDeferredOperationResultKHR to get the result of the operation.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/shader_features.html layout: default ---
49. Shader Features
There are various reasons why every part of SPIR-V was not exposed to Vulkan 1.0. Over time the Vulkan Working Group has identified use cases where it makes sense to expose a new SPIR-V feature.
Some of the following extensions were added alongside a SPIR-V extension. For example, the VK_KHR_8bit_storage extension was created in parallel with SPV_KHR_8bit_storage. The Vulkan extension only purpose is to allow an application to query for SPIR-V support in the implementation. The SPIR-V extension is there to define the changes made to the SPIR-V intermediate representation.
For details how to use SPIR-V extension please read the dedicated Vulkan Guide chapter.
49.1. VK_KHR_spirv_1_4
| Note | Promoted to core in Vulkan 1.2 |
This extension is designed for a Vulkan 1.1 implementations to expose the SPIR-V 1.4 feature set. Vulkan 1.1 only requires SPIR-V 1.3 and some use cases were found where an implementation might not upgrade to Vulkan 1.2, but still want to offer SPIR-V 1.4 features.
49.2. VK_KHR_8bit_storage and VK_KHR_16bit_storage
| Note | GLSL - GL_EXT_shader_16bit_storage defines both |
Both VK_KHR_8bit_storage (promoted in Vulkan 1.2) and VK_KHR_16bit_storage (promoted in Vulkan 1.1) were added to allow the ability to use small values as input or output to a SPIR-V storage object. Prior to these extensions, all UBO, SSBO, and push constants needed to consume at least 4 bytes. With this, an application can now use 8-bit or 16-bit values directly from a buffer. It is also commonly paired with the use of VK_KHR_shader_float16_int8 as this extension only deals with the storage interfaces.
The following is an example of using SPV_KHR_8bit_storage with the GLSL extension:
#version 450
// Without 8-bit storage each block variable has to be 32-byte wide
layout (set = 0, binding = 0) readonly buffer StorageBuffer {
uint data; // 0x0000AABB
} ssbo;
void main() {
uint a = ssbo.data & 0x0000FF00;
uint b = ssbo.data & 0x000000FF;
}With the extension
#version 450
#extension GL_EXT_shader_8bit_storage : enable
layout (set = 0, binding = 0) readonly buffer StorageBuffer {
uint8_t dataA; // 0xAA
uint8_t dataB; // 0xBB
} ssbo;
void main() {
uint a = uint(ssbo.dataA);
uint b = uint(ssbo.dataB);
}49.3. VK_KHR_shader_float16_int8
| Note | Promoted to core in Vulkan 1.2 |
This extension allows the use of 8-bit integer types or 16-bit floating-point types for arithmetic operations. This does not allow for 8-bit integer types or 16-bit floating-point types in any shader input and output interfaces and therefore is commonly paired with the use of VK_KHR_8bit_storage and VK_KHR_16bit_storage.
49.4. VK_KHR_shader_float_controls
| Note | Promoted to core in Vulkan 1.2 |
This extension allows the ability to set how rounding of floats are handled. The VkPhysicalDeviceFloatControlsProperties shows the full list of features that can be queried. This is useful when converting OpenCL kernels to Vulkan.
49.5. VK_KHR_storage_buffer_storage_class
| Note | Promoted to core in Vulkan 1.1 |
Originally SPIR-V combined both UBO and SSBO into the 'Uniform' storage classes and differentiated them only through extra decorations. Because some hardware treats UBO an SSBO as two different storage objects, the SPIR-V wanted to reflect that. This extension serves the purpose of extending SPIR-V to have a new StorageBuffer class.
An example of this can be seen if you take the following GLSL shader snippet:
layout(set = 0, binding = 0) buffer ssbo {
int x;
};If you target Vulkan 1.0 (which requires SPIR-V 1.0), using glslang --target-env vulkan1.0, you will get something like:
Decorate 7(ssbo) BufferBlock
8: TypePointer Uniform 7(ssbo)
9: 8(ptr) Variable Uniform
12: TypePointer Uniform 6(int)Since SPV_KHR_storage_buffer_storage_class was added to SPIR-V 1.3, if you target Vulkan 1.1 (which requires SPIR-V 1.3) ,using glslang --target-env vulkan1.1, it will make use of the new StorageBuffer class.
Decorate 7(ssbo) Block
8: TypePointer StorageBuffer 7(ssbo)
9: 8(ptr) Variable StorageBuffer
12: TypePointer StorageBuffer 6(int)49.6. VK_KHR_variable_pointers
| Note | Promoted to core in Vulkan 1.1 |
A Variable pointer is defined in SPIR-V as
| Note | A pointer of logical pointer type that results from one of the following instructions: |
When this extension is enabled, invocation-private pointers can be dynamic and non-uniform. Without this extension a variable pointer must be selected from pointers pointing into the same structure or be OpConstantNull.
This extension has two levels to it. The first is the variablePointersStorageBuffer feature bit which allows implementations to support the use of variable pointers into a SSBO only. The variablePointers feature bit allows the use of variable pointers outside the SSBO as well.
49.7. VK_KHR_vulkan_memory_model
| Note | Promoted to core in Vulkan 1.2 |
The Vulkan Memory Model formally defines how to synchronize memory accesses to the same memory locations performed by multiple shader invocations and this extension exposes a boolean to let implementations to indicate support for it. This is important because with many things targeting Vulkan/SPIR-V it is important that any memory transfer operations an application might attempt to optimize doesn’t break across implementations.
49.8. VK_EXT_shader_viewport_index_layer
| Note | Promoted to core in Vulkan 1.2 |
This extension adds the ViewportIndex, Layer built-in for exporting from vertex or tessellation shaders.
In GLSL these are represented by gl_ViewportIndex and gl_Layer built-ins.
49.9. VK_KHR_shader_draw_parameters
| Note | Promoted to core in Vulkan 1.1 |
This extension adds the BaseInstance, BaseVertex, and DrawIndex built-in for vertex shaders. This was added as there are legitimate use cases for both inclusion and exclusion of the BaseVertex or BaseInstance parameters in VertexId and InstanceId, respectively.
In GLSL these are represented by gl_BaseInstanceARB, gl_BaseVertexARB and gl_BaseInstanceARB built-ins.
49.10. VK_EXT_shader_stencil_export
This extension allows a shader to generate the stencil reference value per invocation. When stencil testing is enabled, this allows the test to be performed against the value generated in the shader.
In GLSL this is represented by a out int gl_FragStencilRefARB built-in.
49.11. VK_EXT_shader_demote_to_helper_invocation
| Note | Promoted to core in Vulkan 1.3 |
This extension was created to help with matching the HLSL discard instruction in SPIR-V by adding a demote keyword. When using demote in a fragment shader invocation it becomes a helper invocation. Any stores to memory after this instruction are suppressed and the fragment does not write outputs to the framebuffer.
49.12. VK_KHR_shader_clock
This extension allows the shader to read the value of a monotonically incrementing counter provided by the implementation. This can be used as one possible method for debugging by tracking the order of when an invocation executes the instruction. It is worth noting that the addition of the OpReadClockKHR alters the shader one might want to debug. This means there is a certain level of accuracy representing the order as if the instructions did not exists.
49.13. VK_KHR_shader_non_semantic_info
| Note | Promoted to core in Vulkan 1.3 |
This extension exposes SPV_KHR_non_semantic_info which adds the ability to declare extended instruction sets that have no semantic impact and can be safely removed from a module.
49.14. VK_KHR_shader_terminate_invocation
| Note | Promoted to core in Vulkan 1.3 |
This extension adds the new instruction OpTerminateInvocation to provide a disambiguated functionality compared to the OpKill instruction.
49.15. VK_KHR_workgroup_memory_explicit_layout
This extension provides a way for the shader to define the layout of Workgroup Storage Class memory. Workgroup variables can be declared in blocks, and then use the same explicit layout decorations (e.g. Offset, ArrayStride) as other storage classes.
One use case is to do large vector copies (e.g. uvec4 at at a time) from buffer memory into shared memory, even if the shared memory is really a different type (e.g. scalar fp16).
Another use case is a developers could potentially use this to reuse shared memory and reduce the total shared memory consumption using something such as the following:
pass1 - write shmem using type A
barrier()
pass2 - read shmem using type A
barrier()
pass3 - write shmem using type B
barrier()
pass4 - read shmem using type BThe explicit layout support and some form of aliasing is also required for layering OpenCL on top of Vulkan.
49.16. VK_KHR_zero_initialize_workgroup_memory
| Note | Promoted to core in Vulkan 1.3 |
This extension allows OpVariable with a Workgroup Storage Class to use the Initializer operand.
For security reasons, applications running untrusted content (e.g. web browsers) need to be able to zero-initialize workgroup memory at the start of workgroup execution. Adding instructions to set all workgroup variables to zero would be less efficient than what some hardware is capable of, due to poor access patterns.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/translation_layer_extensions.html layout: default ---
50. Translation Layer Extensions
There is a class of extensions that were only created to allow efficient ways for translation layers to map to Vulkan.
This includes replicating legacy behavior that is challenging for drivers to implement efficiently. This functionality is not considered forward looking, and is not expected to be promoted to a KHR extension or to core Vulkan.
Unless this is needed for translation, it is highly recommended that developers use alternative techniques of using the GPU to achieve the same functionality.
50.1. VK_EXT_custom_border_color
Vulkan provides a transparent black, opaque black, and opaque white VkBorderColor for VkSampler objects in the core spec. Both OpenGL and D3D have the option to set the sampler border to be a custom color.
50.2. VK_EXT_border_color_swizzle
After the publication of VK_EXT_custom_border_color, it was discovered that some implementations had undefined behavior when combining a sampler that uses a custom border color with image views whose component mapping is not the identity mapping.
50.3. VK_EXT_depth_clip_enable
The depth clip enable functionality is specified differently from D3D11 and Vulkan. Instead of VkPipelineRasterizationStateCreateInfo::depthClampEnable, D3D11 has DepthClipEnable (D3D12_RASTERIZER_DESC), which only affects the viewport clip of depth values before rasterization and does not affect the depth clamp that always occurs in the output merger stage of the D3D11 graphics pipeline.
50.4. VK_EXT_depth_clip_control
The depth clip control functionality allows the application to use the OpenGL depth range in NDC. In OpenGL it is [-1, 1] as opposed to Vulkan's default of [0, 1]. Support for clip control was supported in OpenGL via the ARB_clip_control extension.
More info in the depth chapter
50.5. VK_EXT_provoking_vertex
Vulkan’s defaults convention for provoking vertex is “first vertex” while OpenGL’s defaults convention is “last vertex”.
50.6. VK_EXT_transform_feedback
Everything needed for transform feedback can be done via a compute shader in Vulkan. There is also a great blog by Jason Ekstrand on why transform feedback is terrible and should be avoided.
50.7. VK_EXT_image_view_min_lod
This extension provides an API-side version of the MinLod SPIR-V qualifier. The new value is associated with the image view, and is intended to match D3D12’s SRV ResourceMinLODClamp parameter. Using MinLod and similar functionality is primarily intended for sparse texturing since higher resolution mip levels can be paged in and out on demand. There are many ways to achieve a similar clamp in Vulkan. A VkImageView can clamp the base level, but a MinLod can also clamp to a fractional LOD and does not have to modify the base texture dimension, which might simplify some algorithms. VkSamplers can also clamp to fractional LOD, but using many unique samplers for this purpose might not be practical.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_EXT_descriptor_indexing.html layout: default ---
51. VK_EXT_descriptor_indexing
| Note | Promoted to core in Vulkan 1.2 |
This extension was designed to be broken down into a few different, smaller features to allow implementations to add support for the each feature when possible.
51.1. Update after Bind
Without this extension, descriptors in an application are not allowed to update between recording the command buffer and the execution of the command buffers. With this extension an application can querying for descriptorBinding*UpdateAfterBind support for the type of descriptor being used which allows an application to then update in between recording and execution.
| Note | Example If an application has a |
After enabling the desired feature support for updating after bind, an application needs to setup the following in order to use a descriptor that can update after bind:
-
The
VK_DESCRIPTOR_POOL_CREATE_UPDATE_AFTER_BIND_BIT_EXTflag for anyVkDescriptorPoolthe descriptor is allocated from. -
The
VK_DESCRIPTOR_SET_LAYOUT_CREATE_UPDATE_AFTER_BIND_POOL_BIT_EXTflag for anyVkDescriptorSetLayoutthe descriptor is from. -
The
VK_DESCRIPTOR_BINDING_UPDATE_AFTER_BIND_BIT_EXTfor each binding in theVkDescriptorSetLayoutthat the descriptor will use.
The following code example gives an idea of the difference between enabling update after bind and without it:

51.2. Partially bound
With the descriptorBindingPartiallyBound feature and using VK_DESCRIPTOR_BINDING_PARTIALLY_BOUND_BIT_EXT in the VkDescriptorSetLayoutBindingFlagsCreateInfo::pBindingFlags an application developer isn’t required to update all the descriptors at time of use.
An example would be if an application’s GLSL has
layout(set = 0, binding = 0) uniform sampler2D textureSampler[64];but only binds the first 32 slots in the array. This also relies on the the application knowing that it will not index into the unbound slots in the array.
51.3. Dynamic Indexing
Normally when an application indexes into an array of bound descriptors the index needs to be known at compile time. With the shader*ArrayDynamicIndexing feature, a certain type of descriptor can be indexed by “dynamically uniform” integers. This was already supported as a VkPhysicalDeviceFeatures for most descriptors, but this extension adds VkPhysicalDeviceDescriptorIndexingFeatures struct that lets implementations expose support for dynamic uniform indexing of input attachments, uniform texel buffers, and storage texel buffers as well.
The key word here is “uniform” which means that all invocations in a SPIR-V Invocation Group need to all use the same dynamic index. This translates to either all invocations in a single vkCmdDraw* call or a single workgroup of a vkCmdDispatch* call.
An example of dynamic uniform indexing in GLSL
layout(set = 0, binding = 0) uniform sampler2D mySampler[64];
layout(set = 0, binding = 1) uniform UniformBufferObject {
int textureId;
} ubo;
// ...
void main() {
// ...
vec4 samplerColor = texture(mySampler[ubo.textureId], uvCoords);
// ...
}This example is “dynamic” as it is will not be known until runtime what the value of ubo.textureId is. This is also “uniform” as all invocations will use ubo.textureId in this shader.
51.4. Dynamic Non-Uniform Indexing
To be dynamically non-uniform means that it is possible that invocations might index differently into an array of descriptors, but it won’t be known until runtime. This extension exposes in VkPhysicalDeviceDescriptorIndexingFeatures a set of shader*ArrayNonUniformIndexing feature bits to show which descriptor types an implementation supports dynamic non-uniform indexing for. The SPIR-V extension adds a NonUniform decoration which can be set in GLSL with the help of the nonuniformEXT keyword added.
An example of dynamic non-uniform indexing in GLSL
#version450
#extension GL_EXT_nonuniform_qualifier : enable
layout(set = 0, binding = 0) uniform sampler2D mySampler[64];
layout(set = 0, binding = 1) uniform UniformBufferObject {
int textureId;
} ubo;
// ...
void main() {
// ...
if (uvCoords.x > runtimeThreshold) {
index = 0;
} else {
index = 1;
}
vec4 samplerColor = texture(mySampler[nonuniformEXT(index)], uvCoords);
// ...
}This example is non-uniform as some invocations index a mySampler[0] and some at mySampler[1]. The nonuniformEXT() is needed in this case.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_EXT_inline_uniform_block.html layout: default ---
52. VK_EXT_inline_uniform_block
| Note | Promoted to core in Vulkan 1.3 |
For a common implementation, descriptors are just a table to indirectly point to the data that was bound to it during the recording of the command buffer. The issue is that not all descriptors are created equally, for example, one descriptor might only be a few DWORDS in size.

Using VK_EXT_inline_uniform_block gives an implementation the opportunity to reduce the number of indirections an implementation takes to access uniform values, when only a few values are used. Unlike push constants, this data can be reused across multiple disjoint sets of draws/dispatches.
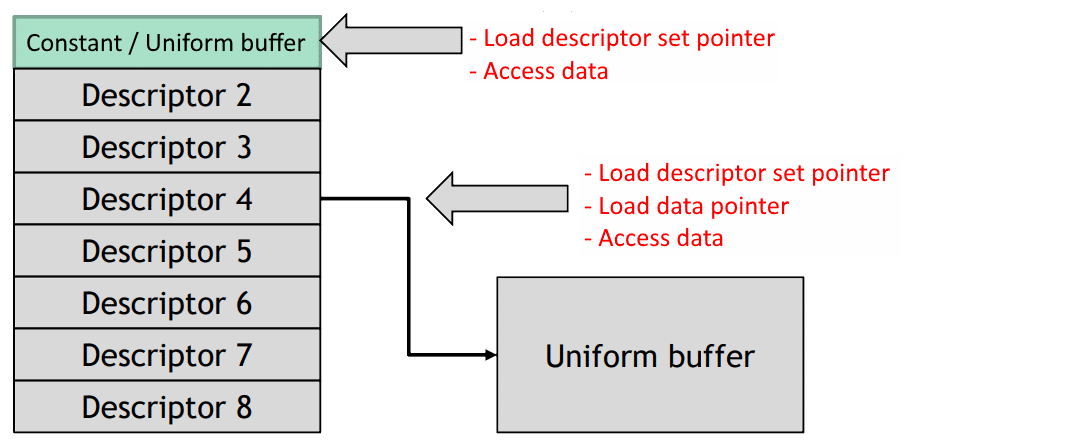
52.1. Suggestions
-
Make sure to check the
VkPhysicalDeviceInlineUniformBlockPropertiesEXTstruct for the limitation for the implementation’s usage of inline uniform blocks. -
Don’t overdo the usage of inlining, otherwise the driver may need to repack them into a buffer, adding CPU overhead and losing the indirection benefit - aim for no more than a few dwords.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_EXT_memory_priority.html layout: default ---
53. VK_EXT_memory_priority
Memory management is an important part of Vulkan. The VK_EXT_memory_priority extension was designed to allow an application to prevent important allocations from being moved to slower memory.
This extension can be explained with an example of two applications (the main application and another process on the host machine). Over time the applications both attempt to consume the limited device heap memory.
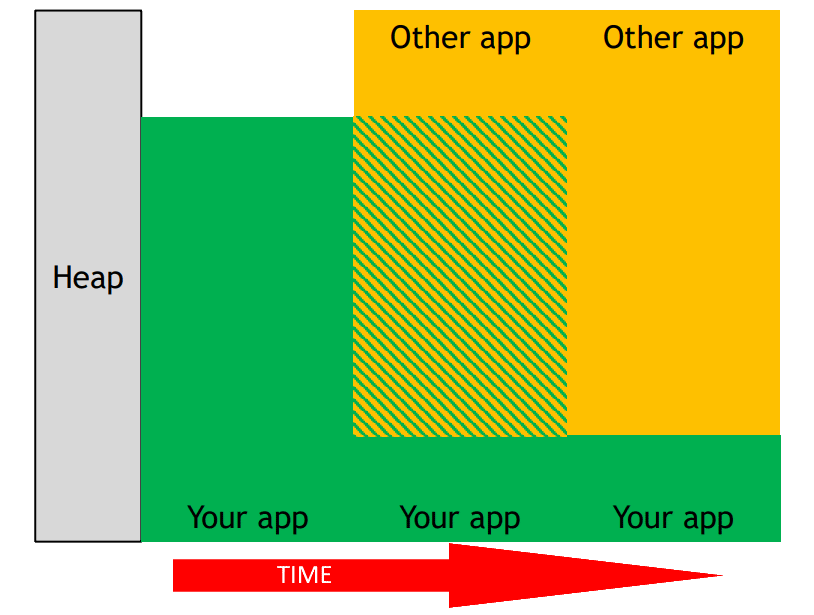
In this situation, the allocation from the main application is still present, just possibly on slower memory (implementation might have moved it to host visible memory until it is needed again).
The decision of what memory will get moved is implementation defined. Let’s now imagine this is the main application’s memory usage

As we can see, there was some memory the application felt was more important to always attempt to keep in fast memory.
The VK_EXT_memory_priority extension makes this very easy. When allocating memory, an application just needs to add VkMemoryPriorityAllocateInfoEXT to VkMemoryAllocateInfo::pNext. From here the VkMemoryPriorityAllocateInfoEXT::priority value can be set with a value between 0.0 and 1.0 (where 0.5) is the default. This allows the application to help the implementation make a better guess if the above situation occurs.
53.1. Suggestions
-
Make sure the extension is supported.
-
Remember this is a hint to the implementation and an application should still try to budget properly prior to using this.
-
Always measure memory bottlenecks instead of making assumptions when possible.
-
Any memory being written to will have a good chance of being a high priority.
-
Render targets (Ex: Framebuffer’s output attachments) are usually important to set to high priority
-
-
View high priority memory as having “high frequency access” and “low latency tolerance”
-
Ex: Vertex buffers, which remain stable across multiple frames, have each value accessed only once, and typically are forgiving for access latency, are usually a good candidate for lower priorities.
-
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_descriptor_update_template.html layout: default ---
54. VK_KHR_descriptor_update_template
| Note | Promoted to core in Vulkan 1.1 |
This extension is designed around how some applications create and update many VkDescriptorSets during the initialization phase. It’s not unlikely that a lot of updates end up having the same VkDescriptorLayout and the same bindings are being updated so therefore descriptor update templates are designed to only pass the update information once.
The descriptors themselves are not specified in the VkDescriptorUpdateTemplate, rather, offsets into an application provided a pointer to host memory are specified, which are combined with a pointer passed to vkUpdateDescriptorSetWithTemplate or vkCmdPushDescriptorSetWithTemplateKHR. This allows large batches of updates to be executed without having to convert application data structures into a strictly-defined Vulkan data structure.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_draw_indirect_count.html layout: default ---
55. VK_KHR_draw_indirect_count
| Note | Promoted to core in Vulkan 1.2 |
Every call to vkCmdDraw consumes a set of parameters describing the draw call. To batch draw calls together the same parameters are stored in a VkBuffer in blocks of VkDrawIndirectCommand. Using vkCmdDrawIndirect allows you to invoke a drawCount number of draws, but the drawCount is needed at record time. The new vkCmdDrawIndirectCount call allows the drawCount to also be in a VkBuffer. This allows the value of drawCount to be dynamic and decided when the draw call is executed.
| Note | The |
The following diagram is to visualize the difference between vkCmdDraw, vkCmdDrawIndirect, and vkCmdDrawIndirectCount.
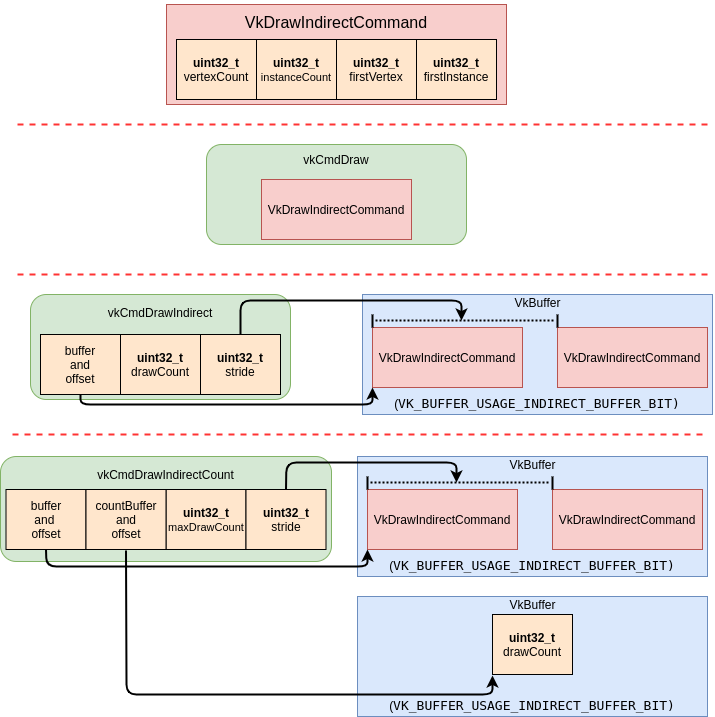
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_image_format_list.html layout: default ---
56. VK_KHR_image_format_list
| Note | Promoted to core in Vulkan 1.2 |
On some implementations, setting the VK_IMAGE_CREATE_MUTABLE_FORMAT_BIT on VkImage creation can cause access to that VkImage to perform worse than an equivalent VkImage created without VK_IMAGE_CREATE_MUTABLE_FORMAT_BIT because the implementation does not know what VkImageView formats will be paired with the VkImage. This may force the implementation to disable (VkImageView) format-specific optimizations such as lossless image compression. If the VkImageFormatListCreateInfo struct used to explicitly list the VkImageView formats the VkImage may be paired with, the implementation may be able to enable format-specific optimization in additional cases.
If the application is not using the VK_IMAGE_CREATE_MUTABLE_FORMAT_BIT to create images, then there is no need to be concerned with this extension.
permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_imageless_framebuffer.html layout: default ---
57. VK_KHR_imageless_framebuffer
| Note | Promoted to core in Vulkan 1.2 |
When creating a VkFramebuffer you normally need to pass the VkImageViews being used in VkFramebufferCreateInfo::pAttachments.
To use an imageless VkFramebuffer
-
Make sure the implementation has support for it by querying
VkPhysicalDeviceImagelessFramebufferFeatures::imagelessFramebufferorVkPhysicalDeviceVulkan12Features::imagelessFramebuffer -
Set the
VK_FRAMEBUFFER_CREATE_IMAGELESS_BITinVkFramebufferCreateInfo::flags -
Include a
VkFramebufferAttachmentsCreateInfostruct in theVkFramebufferCreateInfo::pNext -
When beginning the render pass, pass in a
VkRenderPassAttachmentBeginInfostructure intoVkRenderPassBeginInfo::pNextwith the compatible attachments
// Fill information about attachment
VkFramebufferAttachmentImageInfo attachments_image_info = {};
// ...
VkFramebufferAttachmentsCreateInfo attachments_create_info = {};
// ...
attachments_create_info.attachmentImageInfoCount = 1;
attachments_create_info.pAttachmentImageInfos = &attachments_image_info;
// Create FrameBuffer as imageless
VkFramebufferCreateInfo framebuffer_info = {};
framebuffer_info.pNext = &attachments_create_info;
framebuffer_info.flags |= VK_FRAMEBUFFER_CREATE_IMAGELESS_BIT;
// ...
framebffer_info.pAttachments = NULL; // pAttachments is ignored here now
vkCreateFramebuffer(device, &framebuffer_info, NULL, &framebuffer_object);
// ...
// Start recording a command buffer
VkRenderPassAttachmentBeginInfo attachment_begin_info = {};
// attachment_begin_info.pAttachments contains VkImageView objects
VkRenderPassBeginInfo begin_info = {};
begin_info.pNext = &attachment_begin_info;
// ...
vkCmdBeginRenderPass(command_buffer, &begin_info, VK_SUBPASS_CONTENTS_INLINE);permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_sampler_ycbcr_conversion.html layout: default ---
58. VK_KHR_sampler_ycbcr_conversion
| Note | Promoted to core in Vulkan 1.1 |
All the examples below use a 4:2:0 multi-planar Y′CBCR format for illustration purposes.
58.1. Multi-planar Formats
To represent a Y′CBCR image for which the Y' (luma) data is stored in plane 0, the CB blue chroma difference value ("U") data is stored in plane 1, and the CR red chroma difference value ("V") data is stored in plane 2, an application would use the VK_FORMAT_G8_B8_R8_3PLANE_420_UNORM format.
The Vulkan specification separately describes each multi-planar format representation and its mapping to each color component. Because the mapping and color conversion is separated from the format, Vulkan uses “RGB” color channel notations in the formats, and the conversion then describes the mapping from these channels to the input to the color conversion.
This allows, for example, VK_FORMAT_B8G8R8_UNORM images to represent Y′CBCR texels.
-
G==Y -
B==Cb -
R==Cr
This may require some extra focus when mapping the swizzle components between RGBA and the Y′CBCR format.
58.2. Disjoint
Normally when an application creates a VkImage it only binds it to a single VkDeviceMemory object. If the implementation supports VK_FORMAT_FEATURE_DISJOINT_BIT for a given format then an application can bind multiple disjoint VkDeviceMemory to a single VkImage where each VkDeviceMemory represents a single plane.
Image processing operations on Y′CBCR images often treat channels separately. For example, applying a sharpening operation to the luma channel or selectively denoising luma. Separating the planes allows them to be processed separately or to reuse unchanged plane data for different final images.
Using disjoint images follows the same pattern as the normal binding of memory to an image with the use of a few new functions. Here is some pseudo code to represent the new workflow:
VkImagePlaneMemoryRequirementsInfo imagePlaneMemoryRequirementsInfo = {};
imagePlaneMemoryRequirementsInfo.planeAspect = VK_IMAGE_ASPECT_PLANE_0_BIT;
VkImageMemoryRequirementsInfo2 imageMemoryRequirementsInfo2 = {};
imageMemoryRequirementsInfo2.pNext = &imagePlaneMemoryRequirementsInfo;
imageMemoryRequirementsInfo2.image = myImage;
// Get memory requirement for each plane
VkMemoryRequirements2 memoryRequirements2 = {};
vkGetImageMemoryRequirements2(device, &imageMemoryRequirementsInfo2, &memoryRequirements2);
// Allocate plane 0 memory
VkMemoryAllocateInfo memoryAllocateInfo = {};
memoryAllocateInfo.allocationSize = memoryRequirements2.memoryRequirements.size;
vkAllocateMemory(device, &memoryAllocateInfo, nullptr, &disjointMemoryPlane0));
// Allocate the same for each plane
// Bind plane 0 memory
VkBindImagePlaneMemoryInfo bindImagePlaneMemoryInfo = {};
bindImagePlaneMemoryInfo0.planeAspect = VK_IMAGE_ASPECT_PLANE_0_BIT;
VkBindImageMemoryInfo bindImageMemoryInfo = {};
bindImageMemoryInfo.pNext = &bindImagePlaneMemoryInfo0;
bindImageMemoryInfo.image = myImage;
bindImageMemoryInfo.memory = disjointMemoryPlane0;
// Bind the same for each plane
vkBindImageMemory2(device, bindImageMemoryInfoSize, bindImageMemoryInfoArray));58.3. Copying memory to each plane
Even if an application is not using disjoint memory, it still needs to use the VK_IMAGE_ASPECT_PLANE_0_BIT when copying over data to each plane.
For example, if an application plans to do a vkCmdCopyBufferToImage to copy over a single VkBuffer to a single non-disjoint VkImage the data, the logic for a YUV420p layout will look partially like:
VkBufferImageCopy bufferCopyRegions[3];
bufferCopyRegions[0].imageSubresource.aspectMask = VK_IMAGE_ASPECT_PLANE_0_BIT;
bufferCopyRegions[0].imageOffset = {0, 0, 0};
bufferCopyRegions[0].imageExtent.width = myImage.width;
bufferCopyRegions[0].imageExtent.height = myImage.height;
bufferCopyRegions[0].imageExtent.depth = 1;
/// ...
// the Cb component is half the height and width
bufferCopyRegions[1].imageOffset = {0, 0, 0};
bufferCopyRegions[1].imageExtent.width = myImage.width / 2;
bufferCopyRegions[1].imageExtent.height = myImage.height / 2;
bufferCopyRegions[1].imageSubresource.aspectMask = VK_IMAGE_ASPECT_PLANE_1_BIT;
/// ...
// the Cr component is half the height and width
bufferCopyRegions[2].imageOffset = {0, 0, 0};
bufferCopyRegions[2].imageExtent.width = myImage.width / 2;
bufferCopyRegions[2].imageExtent.height = myImage.height / 2;
bufferCopyRegions[2].imageSubresource.aspectMask = VK_IMAGE_ASPECT_PLANE_2_BIT;
vkCmdCopyBufferToImage(...)It is worth noting here is that the imageOffset is zero because its base is the plane, not the entire sname:VkImage. So when using the imageOffset make sure to start from base of the plane and not always plane 0.
58.4. VkSamplerYcbcrConversion
The VkSamplerYcbcrConversion describes all the “out of scope explaining here” aspects of Y′CBCR conversion which are described in the Khronos Data Format Specification. The values set here are dependent on the input Y′CBCR data being obtained and how to do the conversion to RGB color spacce.
Here is some pseudo code to help give an idea of how to use it from the API point of view:
// Create conversion object that describes how to have the implementation do the {YCbCr} conversion
VkSamplerYcbcrConversion samplerYcbcrConversion;
VkSamplerYcbcrConversionCreateInfo samplerYcbcrConversionCreateInfo = {};
// ...
vkCreateSamplerYcbcrConversion(device, &samplerYcbcrConversionCreateInfo, nullptr, &samplerYcbcrConversion));
VkSamplerYcbcrConversionInfo samplerYcbcrConversionInfo = {};
samplerYcbcrConversionInfo.conversion = samplerYcbcrConversion;
// Create an ImageView with conversion
VkImageViewCreateInfo imageViewInfo = {};
imageViewInfo.pNext = &samplerYcbcrConversionInfo;
// ...
vkCreateImageView(device, &imageViewInfo, nullptr, &myImageView));
// Create a sampler with conversion
VkSamplerCreateInfo samplerInfo = {};
samplerInfo.pNext = &samplerYcbcrConversionInfo;
// ...
vkCreateSampler(device, &samplerInfo, nullptr, &mySampler));58.5. combinedImageSamplerDescriptorCount
An important value to monitor is the combinedImageSamplerDescriptorCount which describes how many descriptor an implementation uses for each multi-planar format. This means for VK_FORMAT_G8_B8_R8_3PLANE_420_UNORM an implementation can use 1, 2, or 3 descriptors for each combined image sampler used.
All descriptors in a binding use the same maximum combinedImageSamplerDescriptorCount descriptors to allow implementations to use a uniform stride for dynamic indexing of the descriptors in the binding.
For example, consider a descriptor set layout binding with two descriptors and immutable samplers for multi-planar formats that have VkSamplerYcbcrConversionImageFormatProperties::combinedImageSamplerDescriptorCount values of 2 and 3 respectively. There are two descriptors in the binding and the maximum combinedImageSamplerDescriptorCount is 3, so descriptor sets with this layout consume 6 descriptors from the descriptor pool. To create a descriptor pool that allows allocating 4 descriptor sets with this layout, descriptorCount must be at least 24.
Some pseudo code how to query for the combinedImageSamplerDescriptorCount:
VkSamplerYcbcrConversionImageFormatProperties samplerYcbcrConversionImageFormatProperties = {};
VkImageFormatProperties imageFormatProperties = {};
VkImageFormatProperties2 imageFormatProperties2 = {};
// ...
imageFormatProperties2.pNext = &samplerYcbcrConversionImageFormatProperties;
imageFormatProperties2.imageFormatProperties = imageFormatProperties;
VkPhysicalDeviceImageFormatInfo2 imageFormatInfo = {};
// ...
imageFormatInfo.format = formatToQuery;
vkGetPhysicalDeviceImageFormatProperties2(physicalDevice, &imageFormatInfo, &imageFormatProperties2));
printf("combinedImageSamplerDescriptorCount = %u\n", samplerYcbcrConversionImageFormatProperties.combinedImageSamplerDescriptorCount);permalink:/Notes/004-3d-rendering/vulkan/chapters/extensions/VK_KHR_shader_subgroup_uniform_control_flow.html layout: default ---
59. VK_KHR_shader_subgroup_uniform_control_flow
59.1. Overview
VK_KHR_shader_subgroup_uniform_control_flow provides stronger guarantees for reconvergence of invocations in a shader. If the extension is supported, shaders can be modified to include a new attribute that provides the stronger guarantees (see GL_EXT_subgroup_uniform_control_flow). This attribute can only be applied to shader stages that support subgroup operations (check VkPhysicalDeviceSubgroupProperties::supportedStages or VkPhysicalDeviceVulkan11Properties::subgroupSupportedStages).
The stronger guarantees cause the uniform control flow rules in the SPIR-V specification to also apply to individual subgroups. The most important part of those rules is the requirement to reconverge at a merge block if the all invocations were converged upon entry to the header block. This is often implicitly relied upon by shader authors, but not actually guaranteed by the core Vulkan specification.
59.2. Example
Consider the following GLSL snippet of a compute shader that attempts to reduce the number of atomic operations from one per invocation to one per subgroup:
// Free should be initialized to 0.
layout(set=0, binding=0) buffer BUFFER { uint free; uint data[]; } b;
void main() {
bool needs_space = false;
...
if (needs_space) {
// gl_SubgroupSize may be larger than the actual subgroup size so
// calculate the actual subgroup size.
uvec4 mask = subgroupBallot(needs_space);
uint size = subgroupBallotBitCount(mask);
uint base = 0;
if (subgroupElect()) {
// "free" tracks the next free slot for writes.
// The first invocation in the subgroup allocates space
// for each invocation in the subgroup that requires it.
base = atomicAdd(b.free, size);
}
// Broadcast the base index to other invocations in the subgroup.
base = subgroupBroadcastFirst(base);
// Calculate the offset from "base" for each invocation.
uint offset = subgroupBallotExclusiveBitCount(mask);
// Write the data in the allocated slot for each invocation that
// requested space.
b.data[base + offset] = ...;
}
...
}There is a problem with the code that might lead to unexpected results. Vulkan only requires invocations to reconverge after the if statement that performs the subgroup election if all the invocations in the workgroup are converged at that if statement. If the invocations don’t reconverge then the broadcast and offset calculations will be incorrect. Not all invocations would write their results to the correct index.
VK_KHR_shader_subgroup_uniform_control_flow can be utilized to make the shader behave as expected in most cases. Consider the following rewritten version of the example:
// Free should be initialized to 0.
layout(set=0, binding=0) buffer BUFFER { uint free; uint data[]; } b;
// Note the addition of a new attribute.
void main() [[subroup_uniform_control_flow]] {
bool needs_space = false;
...
// Note the change of the condition.
if (subgroupAny(needs_space)) {
// gl_SubgroupSize may be larger than the actual subgroup size so
// calculate the actual subgroup size.
uvec4 mask = subgroupBallot(needs_space);
uint size = subgroupBallotBitCount(mask);
uint base = 0;
if (subgroupElect()) {
// "free" tracks the next free slot for writes.
// The first invocation in the subgroup allocates space
// for each invocation in the subgroup that requires it.
base = atomicAdd(b.free, size);
}
// Broadcast the base index to other invocations in the subgroup.
base = subgroupBroadcastFirst(base);
// Calculate the offset from "base" for each invocation.
uint offset = subgroupBallotExclusiveBitCount(mask);
if (needs_space) {
// Write the data in the allocated slot for each invocation that
// requested space.
b.data[base + offset] = ...;
}
}
...
}The differences from the original shader are relatively minor. First, the addition of the subgroup_uniform_control_flow attribute informs the implementation that stronger guarantees are required by this shader. Second, the first if statement no longer tests needs_space. Instead, all invocations in the subgroup enter the if statement if any invocation in the subgroup needs to write data. This keeps the subgroup uniform to utilize the enhanced guarantees for the inner subgroup election.
There is a final caveat with this example. In order for the shader to operate correctly in all circumstances, the subgroup must be uniform (converged) prior to the first if statement.
59.3. Related Extensions
-
GL_EXT_subgroup_uniform_control_flow - adds a GLSL attribute for entry points to notify implementations that stronger guarantees for convergence are required. This translates to a new execution mode in the SPIR-V entry point.
-
SPV_KHR_subgroup_uniform_control_flow - adds an execution mode for entry points to indicate the requirement for stronger reconvergence guarantees.